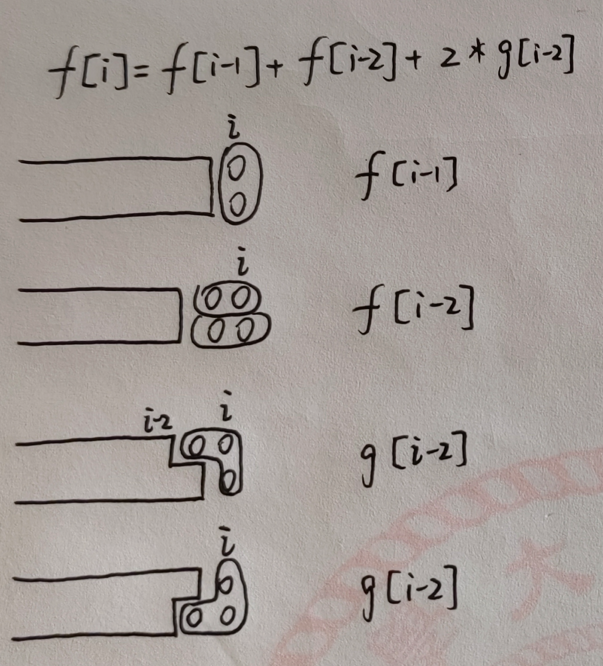本文最后更新于 2024年9月28日 下午
动态规划
动态规划分为被动转移和主动转移,而其根本在于状态表示和状态转移。如何完整表示 所有状态?如何不重不漏 划分子集从而进行状态转移?
【递推】反转字符串
https://www.acwing.com/problem/content/5574/
题意:给定 n 个字符串,每一个字符串对应一个代价 w i w_i w i
思路:很显然每一个字符串都有两种状态,我们可以进行二叉搜索或者二进制枚举。那么我们可以进行 dp 吗?答案是可以的。我们可以发现,对于第 i 个字符串,是否需要翻转仅仅取决于第 i-1 个字符串的大小,无后效性,可以进行递推。我们定义状态数组 f[i][j] 进行状态标识。其中
f[i][0] 表示第 i 个字符串不需要翻转时的最小代价f[i][1] 表示第 i 个字符串需要翻转时的最小代价
状态转移就是当前一个字符串比当前字符串的字典序小时进行转移,即当前最小代价是前一个状态的最小代价加上当前翻转状态的代价。至于什么时候可以进行状态转移,一共有 4 种情况,即:
s[i-1] 不翻转,s[i] 不翻转。此时 f[i][0] = min(f[i][0], f[i-1][0])s[i-1] 翻转,s[i] 不翻转。此时 f[i][0] = min(f[i][0], f[i-1][1])s[i-1] 不翻转,s[i] 翻转。此时 f[i][1] = min(f[i][1], f[i-1][0] + w[i])s[i-1] 翻转,s[i] 翻转。此时 f[i][1] = min(f[i][1], f[i-1][1] + w[i])
最终答案就在 f[n][0] 和 f[n][1] 中取 min 即可
时间复杂度:O ( n ) O(n) O ( n )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 #include <iostream> #include <cstring> #include <algorithm> using namespace std;using ll = long long ;const int N = 100010 ;int n, w[N];2 ]; 2 ]; ll dp () {1 ][0 ] = 0 , f[1 ][1 ] = w[1 ];for (int i = 2 ; i <= n; i++) {if (s[i - 1 ][0 ] <= s[i][0 ]) f[i][0 ] = min (f[i][0 ], f[i - 1 ][0 ]);if (s[i - 1 ][1 ] <= s[i][0 ]) f[i][0 ] = min (f[i][0 ], f[i - 1 ][1 ]);if (s[i - 1 ][0 ] <= s[i][1 ]) f[i][1 ] = min (f[i][1 ], f[i - 1 ][0 ] + w[i]);if (s[i - 1 ][1 ] <= s[i][1 ]) f[i][1 ] = min (f[i][1 ], f[i - 1 ][1 ] + w[i]);return min (f[n][0 ], f[n][1 ]);int main () for (int i = 1 ; i <= n; i++) cin >> w[i];for (int i = 1 ; i <= n; i++) {0 ];1 ] = s[i][0 ];reverse (s[i][1 ].begin (), s[i][1 ].end ());memset (f, 0x3f , sizeof f);dp ();if (res == 0x3f3f3f3f3f3f3f3fll ) res = -1 ;"\n" ;return 0 ;
【递推】最大化子数组的总成本
https://leetcode.cn/problems/maximize-total-cost-of-alternating-subarrays/
题意:给定长度为 n 的序列,现在需要将其分割为子数组,并定义每一个子数组的价值为「奇数位置为原数值,偶数位置为相反数」,返回最大分割价值
思路:~~一开始还在想着如何贪心,即仅考虑连续的负数区间,但是显然的贪不出全局最优解。~~于是转而考虑暴力 dp。思路和朴素 01 背包有相似之处。
状态定义。首先我们一定需要按照元素进行枚举,因此第一维度我们就定义为序列长度,但是仅仅这样定义就能表示全部的状态了吗?显然不行。根据题目的奇偶价值约束,我们在判定每一个负数 是否可以「取相反数」价值时,是取决于上一个负数是否取了相反数价值。为了统一化,我们将正负数一起考虑前一个数是否取了相反价值的情况,因此我们需要再增加「前一个数是否取了相反价值」的状态表示,而这仅仅是一个二值逻辑,直接开两个空间即可。于是状态定义呼之欲出:
f[i][0] 表示第 i 个数取原始价值 的情况下,序列 [0, i-1] 的最大价值f[i][1] 表示第 i 个数取相反价值 的情况下,序列 [0, i-1] 的最大价值
状态转移。显然对于上述状态定义,仅仅需要对「连续负数区间」进行考虑,因此对于 nums[i] >= 0 的情况是没有选择约束的,原始价值和相反价值都是可行的方案那么为了最大化最终收益显然选择原始正价值,并且可以从上一个情况的任意状态转移过来那么同样为了最大化最终受益显然选择最大的基状态,于是可得:
f[i][0] = max(f[i-1][0], f[i-1][1]) + nums[i]f[i][1] = max(f[i-1][0], f[i-1][1]) - nums[i]
而对于 nunms[i] < 0 的情况,能否选择相反数取决于前一个数的正负性。当前一个数 nums[i-1] >= 0 时,显然当前负数原始价值和相反价值都可以取到;当前一个数 nums[i-1] < 0 时,则当前负数仅有在前一个负数取原始价值的情况下才能取相反价值,于是可得:
if nums[i-1] >= 0
f[i][0] = max(f[i-1][0], f[i-1][1]) + nums[i]f[i][1] = max(f[i-1][0], f[i-1][1] - nums[i])
if nums[i-1] < 0
f[i][0] = max(f[i-1][0], f[i-1][1] + nums[i])f[i][1] = f[i-1][0] - nums[i]
答案表示。max(f[n-1][0], f[n-1][1])
时间复杂度:O ( n ) O(n) O ( n )
[] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 class Solution {public :long long maximumTotalCost (vector<int >& nums) using ll = long long ;int n = nums.size ();f (n, vector <ll>(2 , 0 ));0 ][0 ] = f[0 ][1 ] = nums[0 ];for (int i = 1 ; i < n; i++) {if (nums[i] >= 0 || nums[i-1 ] >= 0 ) {0 ] = max (f[i-1 ][0 ], f[i-1 ][1 ]) + nums[i];1 ] = max (f[i-1 ][0 ], f[i-1 ][1 ]) - nums[i];else {0 ] = max (f[i-1 ][0 ], f[i-1 ][1 ]) + nums[i];1 ] = f[i-1 ][0 ] - nums[i];return max (f[n-1 ][0 ], f[n-1 ][1 ]);
[] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 class Solution :def maximumTotalCost (self, nums: List [int ] ) -> int :len (nums)0 ] * 2 for _ in range (n)]0 ][0 ] = f[0 ][1 ] = nums[0 ]for i in range (1 , n):if nums[i] >= 0 or nums[i-1 ] >= 0 :0 ] = max (f[i-1 ][0 ], f[i-1 ][1 ]) + nums[i]1 ] = max (f[i-1 ][0 ], f[i-1 ][1 ]) - nums[i]else :0 ] = max (f[i-1 ][0 ], f[i-1 ][1 ]) + nums[i]1 ] = f[i-1 ][0 ] - nums[i]return max (f[n-1 ][0 ], f[n-1 ][1 ])
【递推】费解的开关
https://www.acwing.com/problem/content/97/
题意:给定 n 个 5*5 的矩阵,代表当前局面。矩阵中每一个元素要么是 0 要么是 1,现在需要计算从当前状态操作到全 1 状态最少需要几次操作?操作描述为改变当前状态为相反状态后,四周的四个元素也需要改变为相反的状态
思路:我们采用递推的思路。为了尽可能少的进行按灯操作,我们从第二行开始考虑,若前一行的某一元素为 0,则下一行的同一列位置就需要按一下,以此类推将 2 → 5 2 \to 5 2 → 5
对于第一个问题:从上述思路可以看出,1 → n − 1 1 \to n-1 1 → n − 1 n − 1 n-1 n − 1 n − 1 n-1 n − 1
对于第二个问题:可以发现,上述算法思路中,对于第一行是没有任何操作的(可以将第一行看做递推的初始化条件),第一行的状态影响全局的总操作数,我们不能确定不对第一行进行任何操作得到的总操作数就是最优的,故我们需要对第一行 5 个灯进行枚举 按下。我们采用 5 位二进制的方法对第一行的 5 个灯进行枚举按下操作,然后对于当前第一行的按下局面(递推初始化状态)进行 2 → n 2 \to n 2 → n
时间复杂度:O ( T × 2 5 × 25 × 5 ) O(T \times 2^5 \times 25 \times 5) O ( T × 2 5 × 25 × 5 )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 #include <bits/stdc++.h> #define int long long using namespace std;const int N = 10 ;char g[N][N], now[N][N];int dx[] = {0 , 1 , -1 , 0 , 0 }, dy[] = {0 , 0 , 0 , 1 , -1 };void turn (int x, int y) for (int k = 0 ; k < 5 ; k++) {int nx = x + dx[k], ny = y + dy[k];1 ;void solve () for (int i = 1 ; i <= 5 ; i++) {1 );int res = 30 ;for (int op = 0 ; op < (1 << 5 ); op++) {memcpy (now, g, sizeof g);int step = 0 ;for (int i = 0 ; i < 5 ; i++) {if (op & (1 << i)) {turn (1 , 5 - i);for (int i = 1 ; i <= 4 ; i++) {for (int j = 1 ; j <= 5 ; j++) {if (now[i][j] == '0' ) {turn (i + 1 , j);bool ok = true ;for (int j = 1 ; j <= 5 ; j++) {if (now[5 ][j] == '0' ) {false ;if (ok) {min (res, step);6 ? -1 : res) << "\n" ;signed main () sync_with_stdio (false );tie (nullptr ), cout.tie (nullptr );int T = 1 ;while (T--) solve ();return 0 ;
【递推/线性dp/哈希】Decode
https://codeforces.com/contest/1996/problem/E
题意:给定一个01字符串,问所有区间中01数量相等的子串总共有多少个。
思路:
我们可以最直接的想到 O ( n 5 ) O(n^5) O ( n 5 ) O ( n 2 ) O(n^2) O ( n 2 ) O ( n 2 ) O(n^2) O ( n 2 ) O ( n ) O(n) O ( n ) O ( n ) O(n) O ( n ) 1 0 5 10^5 1 0 5
容易想到动态规划的思路。我们定义 dp[i] 表示右端点是 s[i] 的所有区间中,合法01子串的数量,那么显然 dp[0] = s[i] == '1'。现在考虑 dp[i] 如何转移。不难发现以 s[i] 为右端点的所有区间一定包含以 s[i - 1] 为右端点的所有区间,多出来的合法子串进存在于以 s[i] 结尾的子串中,我们假设以 s[i] 结尾的合法子串数量为 t,则状态转移方程为:dp[i] = dp[i - 1] + t。显然我们可以用一个滚动变量来代替 dp 数组,记作now,每次维护完 now 以后,将其累加到答案即可。现在我们将枚举区间从 O ( n 2 ) O(n^2) O ( n 2 ) O ( n ) O(n) O ( n ) t 呢?
通过一个小 trick 求解「以 s[i] 结尾的合法子串」的数量。显然可以通过前缀和枚举 j ∈ [ 1 , i ] j \in [1,i] j ∈ [ 1 , i ] i - j + 1 == 2 * (pre[i] - pre[j - 1]) 的数量。但是这样就是 O ( n 2 ) O(n^2) O ( n 2 ) s[i] == '0' 时,将其记作 -1,当 s[i] == '1' 时,保持不变仍然记作 1。这样我们在向前枚举 j 寻找合法区间时,本质上就是在寻找 pre[i] - pre[j - 1] == 0,即 pre[j - 1] == pre[i] 的个数。假设下标从 0 开始,则每找到一个合法的 j,都会对答案贡献 j + 1。因此我们只需要哈希存储每一个前缀和对应的下标累计值即可。
时间复杂度:O ( n ) O(n) O ( n )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 #include <bits/stdc++.h> using ll = long long ;using namespace std;void solve () int n = s.size ();vector<ll> pre (n + 1 ) ;for (int i = 0 ; i < n; i++) {1 ] = pre[i] + (s[i] == '0' ? -1 : 1 );auto add = [&](ll x, ll y) {1e9 + 7 ;return ((x % mod) + (y % mod)) % mod;0 , now = 0 ;for (ll i = 0 ; i <= n; i++) {add (now, f[pre[i]]);add (res, now);1 ;"\n" ;signed main () sync_with_stdio (false );tie (nullptr );int T = 1 ;while (T--) solve ();return 0 ;
【递推/数学】Squaring
https://codeforces.com/contest/1995/problem/C
题意:给定一个序列,可以对其中任何一个数进行任意次平方操作,即 a i → a i 2 a_i \to a_i^2 a i → a i 2
思路:
首先显然的我们不希望第一个数 a 0 a_0 a 0
对于当前数字 a i a_i a i a i − 1 a_{i-1} a i − 1 z i − 1 z_{i-1} z i − 1 a i − 1 2 z i − 1 ≤ a i 2 k \displaystyle a_{i-1}^{2^{z_{i-1}}}\le a_i^{2^{k}} a i − 1 2 z i − 1 ≤ a i 2 k
k : = z i − 1 + ⌈ log 2 ( log 2 a i − 1 log 2 a i ) ⌉ k:= z_{i-1}+ \left\lceil \log_2(\frac{\log_2 {a_{i-1}}}{\log_2{a_i}}) \right \rceil
k := z i − 1 + ⌈ log 2 ( log 2 a i log 2 a i − 1 ) ⌉
由于 a j ∈ [ 1 , 1 0 6 ] , z j ≥ 0 , k ≥ 0 a_j \in [1, 10^6],z_j\ge 0,k \ge 0 a j ∈ [ 1 , 1 0 6 ] , z j ≥ 0 , k ≥ 0
讨论 a i a_i a i a i − 1 a_{i-1} a i − 1 1 1 1
讨论 k k k 0 0 0 a i − 1 < a i a_{i-1} < a_i a i − 1 < a i a i a_i a i a i ≥ 1 a_i\ge1 a i ≥ 1 z i z_i z i 0 0 0 0 0 0
时间复杂度:O ( n ) O(n) O ( n )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 #include <bits/stdc++.h> using ll = long long ;using namespace std;void solve () int n;vector<int > a (n) ;for (int i = 0 ; i < n; i++) {vector<ll> z (n, 0 ) ;0 ;for (int i = 1 ; i < n; i++) {if (a[i] == 1 && a[i - 1 ] > 1 ) {-1 << "\n" ;return ;else if (a[i] == 1 && a[i - 1 ] == 1 || a[i - 1 ] == 1 ) {continue ;1 ] + ceil (log2 (log2 (a[i - 1 ]) / log2 (a[i])));max (0ll , t);"\n" ;signed main () sync_with_stdio (false );tie (nullptr );int T = 1 ;while (T--) solve ();return 0 ;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 from typing import List , Tuple from collections import defaultdict, dequefrom itertools import combinations, permutationsimport math, heapq, queuelambda : int (input ())lambda : float (input ())lambda : tuple (map (int , input ().split()))lambda : list (map (int , input ().split()))def solve () -> None :0 ] * nfor i in range (1 , n):if a[i] == 1 and a[i - 1 ] > 1 :print (-1 )return elif a[i] == 1 and a[i - 1 ] == 1 or a[i - 1 ] == 1 :continue 1 ] + math.ceil(math.log2(math.log2(a[i - 1 ]) / math.log2(a[i])))max (0 , t)print (sum (z))if __name__ == '__main__' :1 while T: solve(); T -= 1
【递推/dfs】牛的语言学
https://www.acwing.com/problem/content/description/5559/
题意:已知一个字符串由前段的一个词根和后段的多个词缀组成。词根的要求是长度至少为 5,词缀的要求是长度要么是 2, 要么是 3,以及不允许连续的相同词缀组成后段。现在给定最终的字符串,问一共有多少种词缀?按照字典序输出所有可能的词缀
思路一:搜索 。很显然我们应该从字符串的最后开始枚举词缀进行搜索,因为词缀前面的所有字符全部都可以作为词根合法存在,我们只需要考虑当前划分出来的词缀是否合法即可。约束只有一个,不能与后面划分出来的词缀相同即可,由于我们是从后往前搜索,因此我们在搜索时保留后一个词缀即可。如果当前词缀和上一个词缀相同则返回,反之如果合法则加入 set 自动进行字典序排序。
时间复杂度:O ( 2 n 2 ) O(2^{\frac{n}{2}}) O ( 2 2 n )
思路二:动态规划(递推) 。动规其实就是 dfs 的逆过程 ,我们从已知结果判断当前局面是否合法。很显然词根是包罗万象的,只要长度合法,不管什么样的都是可行的,故我们在判断当前局面是否合法时,只需要判断当前词缀是否合法即可。于是便可知当前状态是从后面的字符串转移过来的。我们定义状态转移记忆数组 f[i] 表示字符串 s[1,i] 是否可以组成词根。如果 f[i] 为真,则表示 s[1,i] 为一个合法的词根,s[i+1,n] 为一个合法的词缀串,那么词根后面紧跟着的一定是一个长度为 2 或 3 的合法词缀。
我们以紧跟着长度为 2 的合法词缀为例。如果 s[i+1,i+2] 为一个合法的词缀,则必须要满足以下两个条件之一
s[i+1,i+2] 与 s[i+3,i+4] 不相等,即后面的后面是一个长度也为 2 且合法的词缀s[1,i+5] 是一个合法的词根,即 f[i+5] 标记为真,即后面的后面是一个长度为 3 且合法的词缀
以紧跟着长度为 3 的哈法词缀同理。如果 s[i+1,i+3] 为一个合法的词缀,则必须要满足以下两个条件之一
s[i+1,i+3] 与 s[i+4,i+6] 不相等,即后面的后面是一个长度也为 3 且合法的词缀s[1,i+5] 是一个合法的词根,即 f[i+5] 标记为真,即后面的后面是一个长度为 2 且合法的词缀
时间复杂度:O ( n log n ) O(n \log n) O ( n log n ) dp 的过程是线性的,主要时间开销在 set 的自动排序上
dfs 代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 #include <iostream> #include <cstring> #include <vector> #include <queue> #include <stack> #include <algorithm> #include <unordered_map> #include <set> using namespace std;void dfs (int idx, int length, string post) if (idx <= 5 ) return ;substr (idx, length);if (now == post) {return ;else {insert (now);dfs (idx - 2 , 2 , now);dfs (idx - 3 , 3 , now);void solve () "$" + s;int tail_point = s.size ();dfs (tail_point - 2 , 2 , "" );dfs (tail_point - 3 , 3 , "" );size () << "\n" ;for (auto & str: res) cout << str << "\n" ;int main () sync_with_stdio (false );tie (nullptr ), cout.tie (nullptr );int T = 1 ;while (T--) solve ();return 0 ;
dp 代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 #include <iostream> #include <cstring> #include <vector> #include <queue> #include <stack> #include <algorithm> #include <unordered_map> #include <set> using namespace std;const int N = 50010 ;bool f[N]; void solve () "$" + s;int n = s.size () - 1 ;true ;for (int i = n; i >= 5 ; i--) {for (int len = 2 ; len <= 3 ; len++) {if (f[i + len]) {substr (i + 1 , len);substr (i + 1 + len, len);if (a != b || f[i + 5 ]) {insert (a);true ;size () << "\n" ;for (auto & x: res) cout << x << "\n" ;int main () sync_with_stdio (false );tie (nullptr ), cout.tie (nullptr );int T = 1 ;while (T--) solve ();return 0 ;
【线性dp】最小化网络并发线程分配
https://vijos.org/d/nnu_contest/p/1492
题意:现在有一个线性网络需要分配并发线程,每一个网络有一个权重,现在有一个线程分配规则。对于当前网络,如果权重比相邻的网络大,则线程就必须比相邻的网络大。
思路:我们从答案角度来看,对于一个网络,我们想知道它的相邻的左边线程数和右边线程数,如果当前网络比左边和右边的权重都大,则就是左右线程数的最大值+1,当然这些的前提是左右线程数已经是最优的状态 ,因此我们要先求“左右线程”。分析可知,左线程只取决于左边的权重与线程数,右线程同样只取决于右边的权重和线程数,因此我们可以双向扫描一遍即可求得“左右线程”。最后根据“左右线程”即可求得每一个点的最优状态。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 void solve () int n; cin >> n;vector<int > w (n + 1 ) , l (n + 1 , 1 ) , r (n + 1 , 1 ) ;for (int i = 1 ; i <= n; i++) {for (int i = 2 , j = n - 1 ; i <= n && j >= 1 ; i++, j--) {if (w[i] > w[i - 1 ]) {1 ] + 1 ;if (w[j] > w[j + 1 ]) {1 ] + 1 ;int res = 0 ;for (int i = 1 ; i <= n; i++) {max (l[i], r[i]);"\n" ;
【线性dp】Block Sequence
https://codeforces.com/contest/1881/problem/E
题意:给定一个长为 n ≤ 2 × 1 0 5 n\le 2\times 10^5 n ≤ 2 × 1 0 5 − 1 -1 − 1
思路:
首先可以看出,序列的首元素一定是对应子数组剩余元素的个数。我们不妨倒序枚举每一个元素并定义 f[i] 表示使数组 a[i:] 符合定义的最小删除次数,这样每次枚举到的元素都一定是所在子数组的首元素。
接下来考虑状态转移。对于当前枚举到的元素 a[i],如果不删除,则 f[i] 将从 f[i+a[i]+1] 转移过来;如果删除,则 f[i] 将从 f[i+1] 转移过来。两者取最小值即可。
时间复杂度 O ( n ) O(n) O ( n )
1 2 3 4 5 6 7 8 9 10 def solve () -> Optional :1 )0 for i in range (n - 1 , -1 , -1 ):1 ] + 1 if i + a[i] + 1 <= n:min (f[i], f[i + a[i] + 1 ])return f[0 ]
【线性dp】覆盖墙壁
https://www.luogu.com.cn/problem/P1990
题意:给定两种砖块,分别为日字型与L型,问铺满 2 ∗ n 2*n 2 ∗ n
思路:
我们采用递推的思路
d e f i n e : define: d e f in e : f[i] 表示铺满前 2 ∗ i 2*i 2 ∗ i g[i] 表示铺满前 2 ∗ i + 1 2*i+1 2 ∗ i + 1 b a s e : base: ba se : f[0] = 1, f[1] = 1, g[0] = 0, g[1] = 1d p : dp: d p : f[i] = f[i-1] + f[i-2] + g[i-1] ∣ ∣ || ∣∣ g[i] = f[i-1] + g[i-1]r e s u l t : result: res u lt : f[n]
手绘:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 #include <bits/stdc++.h> using namespace std;const int N = 1000010 , mod = 10000 ;int n;int f[N], g[N];void solve () 0 ] = 1 , f[1 ] = 1 ;0 ] = 0 , g[1 ] = 1 ;for (int i = 2 ; i <= n; i++) {1 ] + f[i - 2 ] + 2 * g[i - 2 ]) % mod;1 ] + g[i - 1 ]) % mod;"\n" ;int main () sync_with_stdio (false );tie (nullptr ), cout.tie (nullptr );int T = 1 ;while (T--) solve ();return 0 ;
【线性dp】施咒的最大总伤害
https://leetcode.cn/problems/maximum-total-damage-with-spell-casting/
标签:线性 dp
题意:给定一个数组,选择一个子序列使得总和最大。约束为:如果选择了值为 x x x x − 2 , x − 1 , x + 1 , x + 2 x-2,x-1,x+1,x+2 x − 2 , x − 1 , x + 1 , x + 2
思路:
哈希计数。首先很显然的我们需要进行哈希计数,便于按数值升序枚举元素。我们定义哈希后的序列为 v,大小为 m,存储每一种数的数值 val: int 和个数 cnt: int
状态定义。我们定义状态 f[i] 表示哈希序列 [1,i] 中子序列总和的最大值,则最终答案就是 f[m]
状态转移。对于每一个哈希元素,都有选择和不选两种状态。假设当前枚举到的哈希元素为 i,
不选当前元素。就相当于没有当前元素,则 f[i] = f[i-1]
选择当前元素。我们就需要从哈希序列 [1,i-1] 中,比当前哈希元素 v[i].val 小 2 且对应子序列之和最大的那个状态 f[j] 转移过来。显然我们可以直接枚举哈希序列 [1,i-1],但是这样就是 O ( n 2 ) O(n^2) O ( n 2 ) f[] 数组是单调递增的并且哈希序列的元素数值 v[].val 也是单调递增的。也就是说对于当前状态 f[i],在枚举哈希序列 [1,i-1] 时,其实并不需要从 1 开始枚举,可以从上一个状态枚举到的状态(记作 j)开始枚举(因为上一个状态对应的 f[j] 是上一个状态可转移的方案中最大的并且 v[j].val 一定比当前方案的哈希数值 v[i].val 小 2)。于是状态转移的时间开销就从 O ( n ) O(n) O ( n ) O ( 1 ) O(1) O ( 1 )
时间复杂度:O ( n ) O(n) O ( n )
空间复杂度:O ( n ) O(n) O ( n )
[] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 class Solution {public :long long maximumTotalDamage (vector<int >& power) using ll = long long ;int , int > a;for (int x: power) {int m = a.size (), idx = 1 ;struct node { ll val, cnt; };vector<node> v (m + 1 ) ;for (auto it: a) {vector<ll> f (m + 1 ) ;1 ] = v[1 ].val * v[1 ].cnt;for (int i = 2 , j = 1 ; i <= m; i++) {while (j < i && v[j].val < v[i].val - 2 ) {max (f[i - 1 ], f[j] + v[i].val * v[i].cnt);return f[m];
[] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 class Solution :def maximumTotalDamage (self, power: List [int ] ) -> int :from collections import defaultdictint )for x in power:1 sorted (a.items(), key=lambda x: x[0 ])class node :def __init__ (self, val: int , cnt: int ) -> None :self .val = valself .cnt = cntlen (a), 1 0 , 0 )] * (m + 1 )for it in a:0 ], it[1 ])1 0 ] * (m + 1 )1 ], j = v[1 ].val * v[1 ].cnt, 1 for i in range (2 , m + 1 ):while j < i and v[j].val < v[i].val - 2 :1 1 max (f[i - 1 ], f[j] + v[i].val * v[i].cnt)return f[m]
【线性dp】奇怪的汉诺塔
https://www.acwing.com/problem/content/98/
题意:四塔汉诺塔问题。求在给定 n n n
思路:
我们定义「最小完成单元」为:在满足游戏规则的情况下,将一座塔的所有圆盘移动到另一座塔所需的最少塔数。那么显然的最小完成单元为 3 座塔。定义 d[i] 表示三塔模式下 i i i f[i] 表示四塔模式下 i i i
对于 4 座塔的情况,相当于最小完成单元又多了 1 座塔。那么显然多出来的这座塔有两个处置方案:
如果我们不利用 这座塔。那么还剩 3 座塔,也就是最小完成单元,此时的最少移动次数是唯一的,也就是 f[i] = d[i]
如果我们要利用 这座塔。那么我们只能在这一座塔上 按规则放圆盘。因为要确保最小完成单元来让剩余的圆盘移动到另一座塔。如果还在别的塔上放置了圆盘,那么将不符合最小完成单元的定义,游戏无法结束。当然我们不能将所有的圆盘都先放到这座塔上,因为这种情况下是不可能成立的,我们不可能让一个「我们正在求解的问题」作为我们的答案。也就是说 j < i j<i j < i
至此四塔模式下 i i i j ∈ [ 0 , i − 1 ] j \in [0,i-1] j ∈ [ 0 , i − 1 ] f [ j ] f[j] f [ j ] i − j i-j i − j d [ i − j ] d[i-j] d [ i − j ] j j j f [ j ] f[j] f [ j ]
于是最终的状态转移方程为:
f i = min { f j + d i − j + f j } , i ∈ [ 1 , n ] , j ∈ [ 0 , i − 1 ] f_i = \min{ \{ f_j+d_{i-j}+f_j \} },\quad i \in [1,n],\quad j \in [0,i-1]
f i = min { f j + d i − j + f j } , i ∈ [ 1 , n ] , j ∈ [ 0 , i − 1 ]
时间复杂度:O ( n 2 ) O(n^2) O ( n 2 )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 #include <bits/stdc++.h> using ll = long long ;using namespace std;void solve () int n = 12 ;vector<int > d (n + 1 ) ; vector<int > f (n + 1 , 1e9 ) ; 1 ] = 1 ;for (int i = 1 ; i <= n; i++) {1 + 2 * d[i - 1 ];1 ] = 1 ;for (int i = 1 ; i <= n; i++) {for (int j = 0 ; j <= i - 1 ; j++) {min (f[i], f[j] + d[i - j] + f[j]);"\n" ;signed main () sync_with_stdio (false );tie (nullptr );int T = 1 ;while (T--) solve ();return 0 ;
【线性dp/dfs】数的计算
https://www.luogu.com.cn/problem/P1028
题意:给定一个数和一种构造方法,即对于当前的数,可以在其后面添加一个最大为当前一半大的数,以此类推构造成一个数列。问一共可以构造出多少个这种数列
思路一:dfs
非常显然的一个搜索树,答案就是结点数
时间复杂度:O ( 方案数 ) O(\text{方案数}) O ( 方案数 )
思路二:dp
dfs代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 #include <bits/stdc++.h> using namespace std;typedef long long ll;int n, res;void dfs (int x) for (int i = x >> 1 ; i >= 1 ; i--) {dfs (i);void solve () dfs (n);"\n" ;signed main () sync_with_stdio (false );tie (nullptr ), cout.tie (nullptr );int T = 1 ;while (T--) solve ();return 0 ;
dp代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 #include <bits/stdc++.h> using namespace std;typedef long long ll;int n;void solve () vector<ll> dp (n + 1 , 1 ) ;for (int i = 2 ; i <= n; i++) {for (int j = 1 ; j <= i >> 1 ; j++) {"\n" ;signed main () sync_with_stdio (false );tie (nullptr ), cout.tie (nullptr );int T = 1 ;while (T--) solve ();return 0 ;
【线性dp/二分答案】规划兼职工作
https://leetcode.cn/problems/maximum-profit-in-job-scheduling/description/
题意:给定 n 份工作的起始时间、终止时间、收益值,现在需要不重叠时间的选择工作使得收益最大
思路:动态规划、二分答案。为了不重不漏的枚举每一份工作,我们将工作按照结束时间进行排序,然后就可以枚举每一份工作了。接下来要解决的问题是,如何根据起始时间和终止时间进行工作的选择。显然的,每一份工作有选与不选两种状态,是否选择取决于收益是否更优,我们考虑动态规划。我们定义状态表 f[i] 表示在前 i 个工作中选择的最大工作收益,返回值就是 f[n],先看图
选择第 i 个工作:f[i] = f[r] + profit[i](其中 r 表示 [1,i-1] 份工作中,结束时间早于当前工作起始时间的最右边的工作,在 [1,i-1] 中二分查找即可)
不选第 i 个工作:f[i] = f[i - 1]
选择最大属性进行状态转移即可:f[i] = max(f[i - 1], f[r] + profit[i])
时间复杂度:O ( n log n ) O(n\log n) O ( n log n )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 class Solution {public :int jobScheduling (vector<int >& startTime, vector<int >& endTime, vector<int >& profit) int n = startTime.size ();int , 3>> jobs (n + 1 );for (int i = 1 ; i <= n; i++) {1 ], endTime[i - 1 ], profit[i - 1 ]};sort (jobs.begin () + 1 , jobs.end (), [&](array<int , 3 >& x, array<int , 3 >& y){return x[1 ] < y[1 ];vector<int > f (n + 1 ) ;for (int i = 1 ; i <= n; i++) {int l = 0 , r = i - 1 ;while (l < r) {int mid = (l + r + 1 ) >> 1 ;if (jobs[mid][1 ] <= jobs[i][0 ]) l = mid;else r = mid - 1 ;max (f[i - 1 ], f[r] + jobs[i][2 ]);return f[n];
【线性dp/二分查找】最长上升子序列
https://www.luogu.com.cn/problem/B3637
题意:给定序列,求解其中最长上升子序列 (Longest Increasing Subsequence, 简称 LIS) 的长度。
思路:我们采用动态规划。
状态定义 :定义状态数组 f[i] 表示以元素 a[i] 结尾的最长上升子序列的长度,显然的初始状态全都是 1
状态转移 :
答案表示 。最终答案就是 max_len
时间复杂度:O ( n log n ) O(n \log n) O ( n log n )
暴力枚举元素
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 #include <bits/stdc++.h> using ll = long long ;using namespace std;void solve () int n;vector<int > a (n) ;for (int i = 0 ; i < n; i++) {vector<int > f (n, 1 ) ;for (int i = 0 ; i < n; i++) {for (int j = 0 ; j < i; j++) {if (a[i] > a[j]) {max (f[i], f[j] + 1 );max_element (f.begin (), f.end ()) << "\n" ;signed main () sync_with_stdio (false );tie (nullptr );int T = 1 ;while (T--) solve ();return 0 ;
暴力枚举长度
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 #include <bits/stdc++.h> using ll = long long ;using namespace std;void solve () int n;vector<int > a (n) ;for (int i = 0 ; i < n; i++) {int >> dp (n + 1 , vector <int >());int max_len = 1 ;1 ].push_back (a[0 ]);for (int i = 1 ; i < n; i++) {bool ok = false ;for (int j = max_len; j >= 1 ; j--) {for (int x: dp[j]) {if (a[i] > x) {1 ].push_back (a[i]);max (max_len, j + 1 );true ;goto flag;if (!ok) {1 ].push_back (a[i]);"\n" ;signed main () sync_with_stdio (false );tie (nullptr );int T = 1 ;while (T--) solve ();return 0 ;
贪心二分优化
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 #include <bits/stdc++.h> using ll = long long ;using namespace std;void solve () int n;vector<int > a (n) ;for (int i = 0 ; i < n; i++) {vector<int > mi (n + 1 , INT_MAX) ;int max_len = 1 ;1 ] = a[0 ];for (int i = 1 ; i < n; i++) {int l = 1 , r = max_len;while (l < r) {int mid = (l + r + 1 ) >> 1 ;if (a[i] > mi[mid]) l = mid;else r = mid - 1 ;if (a[i] > mi[r]) {1 ] = min (mi[r + 1 ], a[i]);max (max_len, r + 1 );else {1 ] = a[i];"\n" ;signed main () sync_with_stdio (false );tie (nullptr );int T = 1 ;while (T--) solve ();return 0 ;
【网格图dp/dfs】过河卒
https://www.luogu.com.cn/problem/P1002
题意:给定一个矩阵,现在需要从左上角走到右下角,问一共有多少种走法?有一个特殊限制是,对于图中的9个点是无法通过的。
思路一:dfs
思路二:dp
dfs代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 #include <bits/stdc++.h> using namespace std;typedef long long ll;const int N = 30 ;int n, m, a, b;int res;bool notsafe[N][N];void init () int px[9 ] = {0 , -1 , -2 , -2 , -1 , 1 , 2 , 2 , 1 };int py[9 ] = {0 , 2 , 1 , -1 , -2 , -2 , -1 , 1 , 2 };for (int i = 0 ; i < 9 ; i++) {int na = a + px[i], nb = b + py[i];if (na < 0 || nb < 0 ) continue ;true ;void dfs (int x, int y) if (x > n || y > m || notsafe[x][y]) {return ;if (x == n && y == m) {return ;dfs (x, y + 1 );dfs (x + 1 , y);void solve () init ();dfs (0 , 0 );"\n" ;signed main () sync_with_stdio (false );tie (nullptr ), cout.tie (nullptr );int T = 1 ;while (T--) solve ();return 0 ;
dp代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 #include <bits/stdc++.h> using namespace std;typedef long long ll;const int N = 30 ;int n, m, a, b;bool notsafe[N][N];void solve () int px[9 ] = {0 , -1 , -2 , -2 , -1 , 1 , 2 , 2 , 1 };int py[9 ] = {0 , 2 , 1 , -1 , -2 , -2 , -1 , 1 , 2 };for (int i = 0 ; i < 9 ; i++) {int na = a + px[i], nb = b + py[i];if (na < 0 || nb < 0 ) continue ;true ;1 ][1 ] = 1 ;for (int i = 1 ; i <= n; i++) {for (int j = 1 ; j <= m; j++) {if (!notsafe[i - 1 ][j]) dp[i][j] += dp[i - 1 ][j];if (!notsafe[i][j - 1 ]) dp[i][j] += dp[i][j - 1 ];"\n" ;signed main () sync_with_stdio (false );tie (nullptr ), cout.tie (nullptr );int T = 1 ;while (T--) solve ();return 0 ;
【网格图dp】摘樱桃 II
https://leetcode.cn/problems/cherry-pickup-ii/
题意:给定一个 n n n m m m
思路:
状态定义。最终状态一定是两人都在最后一行的任意两列,我们如何定义状态可以不重不漏的表示两人的运动状态呢?可以发现两人始终在同一行,但是列数不一定相同,我们定义状态 f [ i ] [ j ] [ k ] f[i][j][k] f [ i ] [ j ] [ k ] i i i j j j k k k
max ( f [ n − 1 ] [ j ] [ k ] ) , j , k ∈ [ 0 , m ] \max{(f[n-1][j][k])},j,k\in[0,m]
max ( f [ n − 1 ] [ j ] [ k ]) , j , k ∈ [ 0 , m ]
状态转移。本题难点在于状态定义,一旦定义好了以后状态转移就不困难了。对于当前状态 f [ i ] [ j ] [ k ] f[i][j][k] f [ i ] [ j ] [ k ] 3 × 3 = 9 3\times 3=9 3 × 3 = 9
时间复杂度:O ( n m 2 ) O(nm^2) O ( n m 2 )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 class Solution :def cherryPickup (self, g: List [List [int ]] ) -> int :len (g), len (g[0 ])1 ] * m for _ in range (m)] for _ in range (n)]0 ][0 ][m - 1 ] = g[0 ][0 ] + g[0 ][m - 1 ]for i in range (1 , n):for j in range (m):for k in range (m):for p in range (j - 1 , j + 2 ):for q in range (k - 1 , k + 2 ):if 0 <= p < m and 0 <= q < m and f[i - 1 ][p][q] != -1 :max (f[i][j][k], f[i - 1 ][p][q] + g[i][j] + (0 if j == k else g[i][k]))0 for j in range (m):for k in range (j, m):max (res, f[n - 1 ][j][k])return res
【网格图dp】摘樱桃
弱化版 ( n ≤ 50 ) (n\le 50) ( n ≤ 50 ) https://leetcode.cn/problems/cherry-pickup/
强化版 ( n ≤ 300 ) (n\le300) ( n ≤ 300 ) https://codeforces.com/problemset/problem/213/C
题意:给定一个 n 行 n 列的网格图,问从左上走到右下,再从右下走到左上最多可以获得多少价值?一个单元格只能被计算一次价值。
注:弱化版中 -1 表示不可达,强化版没有不可达的约束。强化版 AC 代码
思路一:暴力dp
首先对于来回问题可以转化为两次去的问题,即问题等价于求解「两个人从左上角走到右下角」的最大收益。
显然我们可以定义四维的状态,其中 f [ i ] [ j ] [ p ] [ q ] f[i][j][p][q] f [ i ] [ j ] [ p ] [ q ] ( i , j ) (i,j) ( i , j ) ( p , q ) (p,q) ( p , q )
时间复杂度:O ( n 4 ) O(n^4) O ( n 4 )
思路二:优化dp
注意到问题可以进一步等价于「两个人同时 从左上角走到右下角」的最大收益。也就是两个人到起点 ( 0 , 0 ) (0,0) ( 0 , 0 ) i + j = p + q i+j=p+q i + j = p + q ( i , j ) (i,j) ( i , j ) O ( 1 ) O(1) O ( 1 )
状态定义。我们定义 f [ k ] [ i 1 ] [ i 2 ] f[k][i_1][i_2] f [ k ] [ i 1 ] [ i 2 ] ( i 1 , k − i 1 ) (i_1,k-i_1) ( i 1 , k − i 1 ) ( i 2 , k − i 2 ) (i_2,k-i_2) ( i 2 , k − i 2 ) f [ 2 n − 2 ] [ n − 1 ] [ n − 1 ] f[2n-2][n-1][n-1] f [ 2 n − 2 ] [ n − 1 ] [ n − 1 ]
时间复杂度:O ( n 3 ) O(n^3) O ( n 3 )
暴力dp:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 template <class T>void chmax (T& a, T b) max (a, b);int di[4 ] = {-1 , -1 , 0 , 0 };int dj[4 ] = {0 , 0 , -1 , -1 };int dp[4 ] = {-1 , 0 , -1 , 0 };int dq[4 ] = {0 , -1 , 0 , -1 };class Solution {public :int cherryPickup (vector<vector<int >>& g) int n = g.size ();int f[n][n][n][n];memset (f, -1 , sizeof f);0 ][0 ][0 ][0 ] = g[0 ][0 ] == -1 ? -1 : g[0 ][0 ];for (int i = 0 ; i < n; i++) {for (int j = 0 ; j < n; j++) {if (g[i][j] == -1 ) {continue ;for (int p = 0 ; p < n; p++) {for (int q = 0 ; q < n; q++) {if (g[p][q] == -1 ) {continue ;for (int k = 0 ; k < 4 ; k++) {int ni = i + di[k], nj = j + dj[k];int np = p + dp[k], nq = q + dq[k];if (ni >= 0 && nj >= 0 && np >= 0 && nq >= 0 && f[ni][nj][np][nq] != -1 ) {chmax (f[i][j][p][q], f[ni][nj][np][nq] + g[i][j] + (i == p && j == q ? 0 : g[p][q]));return f[n - 1 ][n - 1 ][n - 1 ][n - 1 ] == -1 ? 0 : f[n - 1 ][n - 1 ][n - 1 ][n - 1 ];
优化dp:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 template <class T>void chmax (T& a, T b) max (a, b);int dx[] = {0 , 0 , -1 , -1 };int dy[] = {0 , -1 , 0 , -1 };class Solution {public :int cherryPickup (vector<vector<int >>& g) int n = g.size ();int f[2 * n - 1 ][n][n];memset (f, -1 , sizeof f);0 ][0 ][0 ] = g[0 ][0 ] == -1 ? -1 : g[0 ][0 ];for (int k = 1 ; k <= 2 * n - 2 ; k++) {for (int i1 = 0 ; i1 < n; i1++) {for (int i2 = 0 ; i2 < n; i2++) {int j1 = k - i1, j2 = k - i2;if (j1 < 0 || j1 >= n || j2 < 0 || j2 >= n || g[i1][j1] == -1 || g[i2][j2] == -1 ) {continue ;for (int t = 0 ; t < 4 ; t++) {int ni1 = i1 + dx[t], nj1 = k - ni1;int ni2 = i2 + dy[t], nj2 = k - ni2;if (ni1 >= 0 && nj1 >= 0 && ni2 >= 0 && nj2 >= 0 && f[k - 1 ][ni1][ni2] != -1 ) {chmax (f[k][i1][i2], f[k - 1 ][ni1][ni2] + g[i1][j1] + (i1 == i2 && j1 == j2 ? 0 : g[i2][j2]));return f[2 * n - 2 ][n - 1 ][n - 1 ] == -1 ? 0 : f[2 * n - 2 ][n - 1 ][n - 1 ];
【树形dp】最大社交深度和
https://vijos.org/d/nnu_contest/p/1534
算法:树形dp、BFS
题意:给定一棵树,现在需要选择其中的一个结点为根节点,使得深度和最大。深度的定义是以每个结点到树根所经历的结点数
思路一:暴力
思路二:树形dp
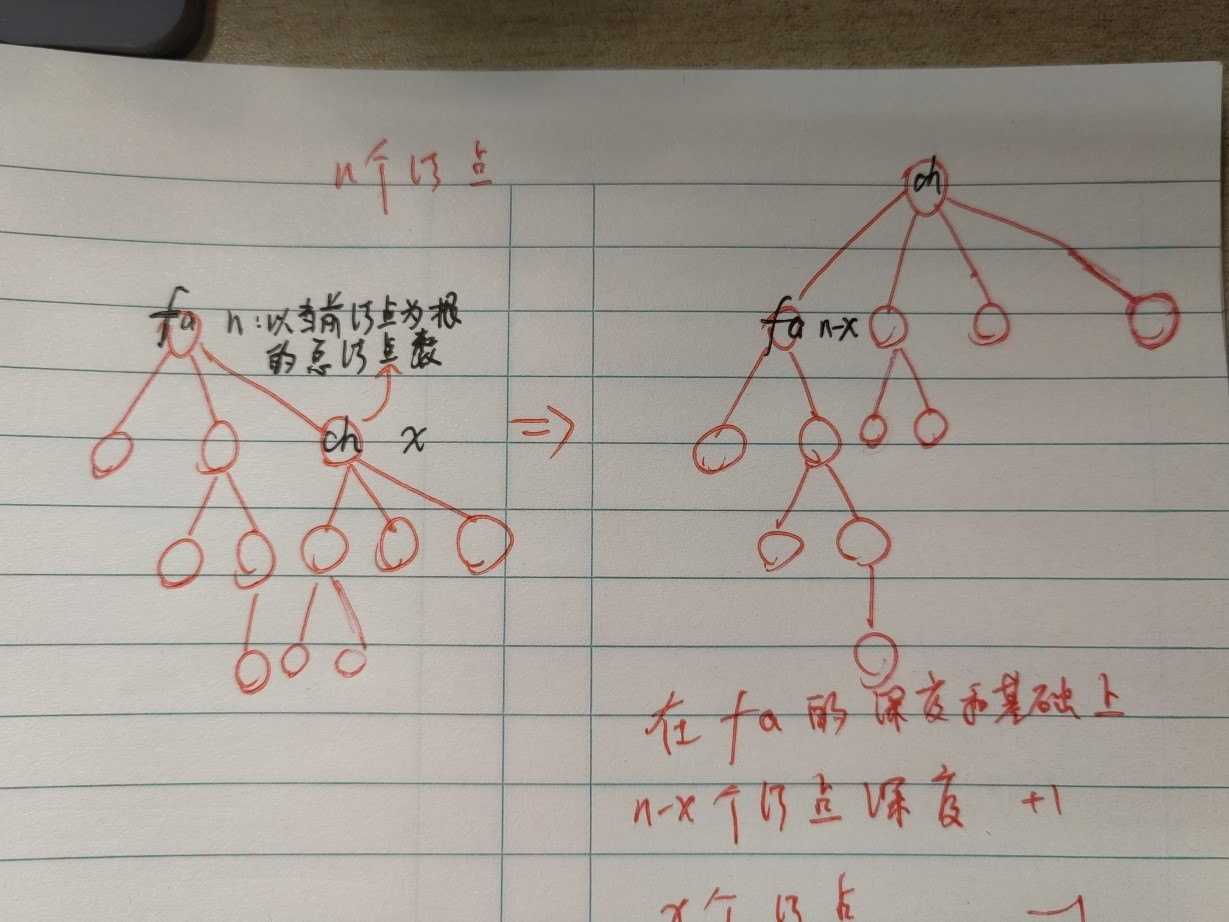
我们可以发现,对于当前的根结点 fa,我们选择其中的一个子结点 ch,将 ch 作为新的根结点(如右图)。那么对于当前的 ch 的深度和,我们可以借助 fa 的深度和进行求解。我们假设以 ch 为子树的结点总数为 x,那么这 x 个结点在换根之后,相对于 ch 的深度和,贡献了 -x 的深度;而对于 fa 的剩下来的 n-x 个结点,相对于 ch 的深度和,贡献了 n-x 的深度。于是 ch 的深度和就是 fa的深度和 -x+n-x,即:
d e p [ c h ] = d e p [ f a ] − x + n − x = d e p [ f a ] + n − 2 × x dep[ch] = dep[fa]-x+n-x = dep[fa]+n-2\times x
d e p [ c h ] = d e p [ f a ] − x + n − x = d e p [ f a ] + n − 2 × x
于是我们很快就能想到利用前后层的递推关系,O ( 1 ) O(1) O ( 1 )
代码实现:我们可以先计算出 base 的情况,即任选一个结点作为根结点,然后基于此进行迭代计算。在迭代计算的时候需要注意的点就是在一遍 dfs 计算某个结点的深度和 dep[root] 时,如果希望同时计算出每一个结点作为子树时,子树的结点数,显然需要分治计算一波。关于分治的计算我熟练度不够高,特此标注一下debug了3h的点 :即在递归到最底层,进行回溯计算的时候,需要注意不能统计父结点的结点值(因为建的是双向图,所以一定会有从父结点回溯的情况),那么为了避开这个点,就需要在 O ( 1 ) O(1) O ( 1 ) fa。
没有考虑从父结点回溯的情况的dfs代码
1 2 3 4 5 6 7 8 9 10 void dfs (int now, int depth) if (!st[now]) {true ;for (auto & ch: G[now]) {dfs (ch, depth + 1 );
考虑了从父结点回溯的情况的dfs代码
1 2 3 4 5 6 7 8 9 10 11 12 void dfs (int now, int fa, int depth) if (!st[now]) {true ;for (auto & ch: G[now]) {dfs (ch, now, depth + 1 );if (ch != fa) {
时间复杂度:Θ ( 2 n ) \Theta(2n) Θ ( 2 n )
暴力代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 const int N = 500010 ;int n;int > G[N];int st[N], dep[N];void dfs (int id, int now, int depth) if (!st[now]) {1 ;for (auto & node: G[now]) {dfs (id, node, depth + 1 );void solve () for (int i = 1 ; i <= n - 1 ; i++) {int a, b;push_back (b);push_back (a);int res = 0 ;for (int i = 1 ; i <= n; i++) {memset (st, 0 , sizeof st);dfs (i, i, 1 );max (res, dep[i]);"\n" ;
优化代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 const int N = 500010 ;int n, dep[N], root = 1 ;int > G[N], cnt (N, 1 );;bool st[N];void dfs (int now, int fa, int depth) if (!st[now]) {true ;for (auto & ch: G[now]) {dfs (ch, now, depth + 1 );if (ch != fa) {void bfs () memset (st, 0 , sizeof st);int > q;push (root);true ;while (q.size ()) {int fa = q.front (); pop ();for (auto & ch: G[fa]) {if (!st[ch]) {true ;2 * cnt[ch];push (ch);void solve () for (int i = 1 ; i <= n - 1 ; i++) {int a, b;push_back (b);push_back (a);dfs (root, -1 , 1 );bfs ();max_element (dep, dep + n + 1 ) << "\n" ;
【高维dp/dfs】栈
https://www.luogu.com.cn/problem/P1044
题意:n个数依次进栈,随机出栈,问一共有多少种出栈序列?
思路一:dfs
我们可以这么构造搜索树:已知对于当前的栈,一共有两种状态
入栈 - 如果当前还有数没有入栈
出栈 - 如果当前栈内还有元素
搜索参数:i,j 表示入栈数为 i 出栈数为 j 的状态
搜索终止条件
入栈数 < 出栈数 - i < j i<j i < j
入栈数 > 总数 n n n i = n i = n i = n
答案状态:入栈数为n,出栈数也为n
时间复杂度:O ( 方案数 ) O(\text{方案数}) O ( 方案数 )
思路二:dp
采用上述dfs时的状态表示方法,i,j 表示入栈数为 i 出栈数为 j 的状态。
我们在搜索的时候,考虑的是接下来可以搜索的状态
即出栈一个数的状态 - i+1,j
和入栈一个数的状态 - i,j+1
如图:
而我们在dp的时候,需要考虑的是子结构的解来得出当前状态的答案,就需要考虑之前的状态。即当前状态是从之前的哪些状态转移过来的。和上述dfs思路是相反的。我们需要考虑的是
上一个状态入栈一个数到当前状态 - i-1,j → \to → i,j
上一个状态出栈一个数到当前状态 - i,j-1 → \to → i,j
特例:i = j i=j i = j i ≥ j i \ge j i ≥ j
如图:
我们知道,入栈数一定是大于等于出栈数的,即 i ≥ j i\ge j i ≥ j j j j [ 1 , i ] [1,i] [ 1 , i ]
b a s e base ba se j = 0 j=0 j = 0
d p [ i ] [ 0 ] = 0 , ( i = 1 , 2 , 3 , . . . , n ) dp[i][0]=0,(i=1,2,3,...,n)
d p [ i ] [ 0 ] = 0 , ( i = 1 , 2 , 3 , ... , n )
时间复杂度:O ( n 2 ) O(n^2) O ( n 2 )
dfs代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 #include <bits/stdc++.h> using namespace std;typedef long long ll;int n, res;void dfs (int i, int j) if (i < j || i > n) return ;if (i == n && j == n) res++;dfs (i + 1 , j);dfs (i, j + 1 );void solve () dfs (0 , 0 );"\n" ;signed main () sync_with_stdio (false );tie (nullptr ), cout.tie (nullptr );int T = 1 ;while (T--) solve ();return 0 ;
dp代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 #include <bits/stdc++.h> using namespace std;typedef long long ll;const int N = 20 ;int n;void solve () for (int i = 1 ; i <= n; i++) dp[i][0 ] = 1 ;for (int i = 1 ; i <= n; i++)for (int j = 1 ; j <= i; j++)if (i == j) dp[i][j] = dp[i][j - 1 ];else dp[i][j] = dp[i - 1 ][j] + dp[i][j - 1 ];"\n" ;signed main () sync_with_stdio (false );tie (nullptr ), cout.tie (nullptr );int T = 1 ;while (T--) solve ();return 0 ;
【高维dp】找出所有稳定的二进制数组 II
https://leetcode.cn/problems/find-all-possible-stable-binary-arrays-ii/
题意:构造一个仅含有 n n n 0 0 0 m m m 1 1 1 k k k 0 0 0 1 1 1 1 0 9 + 7 10^9+7 1 0 9 + 7
思路:
定义状态表。我们从左到右确定每一位的数字时,需要确定这么三个信息:当前是哪一位?还剩几个 0 0 0 1 1 1 0 0 0 1 1 1 f [ i ] [ j ] [ k ] f[i][j][k] f [ i ] [ j ] [ k ] i i i 0 0 0 j j j 1 1 1 i + j i+j i + j k k k f [ n ] [ m ] [ 0 ] + f [ n ] [ m ] [ 1 ] f[n][m][0]+f[n][m][1] f [ n ] [ m ] [ 0 ] + f [ n ] [ m ] [ 1 ]
定义子问题。以当前第 i + j i+j i + j 0 0 0 1 1 1 f [ i ] [ j ] [ 0 ] f[i][j][0] f [ i ] [ j ] [ 0 ] 1 1 1 0 0 0 k k k 0 0 0 1 1 1 k k k 0 0 0 0 0 0
状态转移方程。综上所述,可以得到以下两个状态转移方程:
f [ i ] [ j ] [ 0 ] = f [ i − 1 ] [ j ] [ 1 ] + f [ i − 1 ] [ j ] [ 0 ] − f [ i − k − 1 ] [ j ] [ 1 ] f [ i ] [ j ] [ 1 ] = f [ i ] [ j − 1 ] [ 0 ] + f [ i ] [ j − 1 ] [ 1 ] − f [ i ] [ j − k − 1 ] [ 0 ] \begin{aligned}
f[i][j][0] = f[i - 1][j][1] + f[i - 1][j][0] - f[i - k - 1][j][1] \\
f[i][j][1] = f[i][j - 1][0] + f[i][j - 1][1] - f[i][j - k - 1][0]
\end{aligned}
f [ i ] [ j ] [ 0 ] = f [ i − 1 ] [ j ] [ 1 ] + f [ i − 1 ] [ j ] [ 0 ] − f [ i − k − 1 ] [ j ] [ 1 ] f [ i ] [ j ] [ 1 ] = f [ i ] [ j − 1 ] [ 0 ] + f [ i ] [ j − 1 ] [ 1 ] − f [ i ] [ j − k − 1 ] [ 0 ]
时间复杂度:O ( n m ) O(nm) O ( nm )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 class Solution {public :int numberOfStableArrays (int n, int m, int k) const int mod = 1e9 + 7 ;int , 2>>> f (n + 1 , vector<array<int , 2 >>(m + 1 ));for (int i = 0 ; i <= min (n, k); i++) {0 ][0 ] = 1 ;for (int j = 0 ; j <= min (m, k); j++) {0 ][j][1 ] = 1 ;for (int i = 1 ; i <= n; i++) {for (int j = 1 ; j <= m; j++) {0 ] = (f[i - 1 ][j][1 ] + f[i - 1 ][j][0 ]) % mod;if (i - k - 1 >= 0 ) {0 ] = (f[i][j][0 ] - f[i - k - 1 ][j][1 ] + mod) % mod;1 ] = (f[i][j - 1 ][0 ] + f[i][j - 1 ][1 ]) % mod;if (j - k - 1 >= 0 ) {1 ] = (f[i][j][1 ] - f[i][j - k - 1 ][0 ] + mod) % mod;return (f[n][m][0 ] + f[n][m][1 ]) % mod;
【高维dp】学生出勤记录 II
https://leetcode.cn/problems/student-attendance-record-ii/description/
题意:构造一个仅含有 P , A , L P,A,L P , A , L A A A 1 1 1 L L L 2 2 2 1 0 9 + 7 10^9+7 1 0 9 + 7
思路:
模拟分析问题。我们从前往后构造。对于当前第 i i i s [ i ] s[i] s [ i ] 3 3 3 P P P A A A s [ 0 : i − 1 ] s[0:i-1] s [ 0 : i − 1 ] A A A L L L s [ 0 : i − 1 ] s[0:i-1] s [ 0 : i − 1 ] L L L 被动转移 的动态规划求解。
状态定义。从上述分析不难发现需要 3 3 3 f [ i ] [ j ] [ k ] f[i][j][k] f [ i ] [ j ] [ k ] i i i s [ 0 : i ] s[0:i] s [ 0 : i ] j j j A A A k k k L L L
初始化。每一位填什么取决于前缀 s [ 0 : i − 1 ] s[0:i-1] s [ 0 : i − 1 ] f [ 0 ] [ ] [ ] f[0][][] f [ 0 ] [ ] [ ] 0 0 0 0 0 0 P , A , L P,A,L P , A , L f [ 0 ] [ 0 ] [ 0 ] = f [ 0 ] [ 1 ] [ 0 ] = f [ 0 ] [ 0 ] [ 1 ] = 1 f[0][0][0] = f[0][1][0] = f[0][0][1] = 1 f [ 0 ] [ 0 ] [ 0 ] = f [ 0 ] [ 1 ] [ 0 ] = f [ 0 ] [ 0 ] [ 1 ] = 1 0 0 0
状态转移。考虑第 i i i
填 P P P f [ i ] [ j ] [ 0 ] f[i][j][0] f [ i ] [ j ] [ 0 ]
填 A A A A A A f [ i ] [ 1 ] [ 0 ] f[i][1][0] f [ i ] [ 1 ] [ 0 ]
填 L L L 1 1 1 L L L f [ i ] [ j ] [ k ] f[i][j][k] f [ i ] [ j ] [ k ]
最终答案。为 ∑ j = 0 1 ∑ k = 0 2 f [ n − 1 ] [ j ] [ k ] \displaystyle \sum_{j=0}^{1}\sum_{k=0}^{2}f[n-1][j][k] j = 0 ∑ 1 k = 0 ∑ 2 f [ n − 1 ] [ j ] [ k ]
时间复杂度:Θ ( 6 n ) \Theta (6n) Θ ( 6 n )
[] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 class Solution {public :int checkRecord (int n) const int mod = 1e9 + 7 ;int f[n][2 ][3 ];memset (f, 0 , sizeof f);0 ][0 ][0 ] = f[0 ][1 ][0 ] = f[0 ][0 ][1 ] = 1 ;for (int i = 1 ; i < n; i++) {for (int j = 0 ; j <= 1 ; j++) {for (int k = 0 ; k <= 2 ; k++) {0 ] = (f[i][j][0 ] + f[i - 1 ][j][k]) % mod;for (int k = 0 ; k <= 2 ; k++) {1 ][0 ] = (f[i][1 ][0 ] + f[i - 1 ][0 ][k]) % mod;for (int j = 0 ; j <= 1 ; j++) {for (int k = 1 ; k <= 2 ; k++) {1 ][j][k - 1 ]) % mod;int res = 0 ;for (int j = 0 ; j <= 1 ; j++) {for (int k = 0 ; k <= 2 ; k++) {1 ][j][k]) % mod;return res;
[] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 class Solution :def checkRecord (self, n: int ) -> int :int (1e9 + 7 )0 , 0 , 0 ] for _ in range (2 )] for _ in range (n)]0 ][0 ][0 ] = f[0 ][1 ][0 ] = f[0 ][0 ][1 ] = 1 for i in range (1 , n):for j in range (2 ):for k in range (3 ):0 ] = (f[i][j][0 ] + f[i - 1 ][j][k]) % modfor k in range (3 ):1 ][0 ] = (f[i][1 ][0 ] + f[i - 1 ][0 ][k]) % modfor j in range (2 ):for k in range (1 , 3 ):1 ][j][k - 1 ]) % mod0 for j in range (2 ):for k in range (3 ):1 ][j][k]) % modreturn res
【区间dp】对称山脉
https://www.acwing.com/problem/content/5169/
模拟,时间复杂度 O ( n 3 ) O(n^3) O ( n 3 )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 #include <iostream> #include <cmath> using namespace std;const int N = 5010 ;int n;int a[N];int main () for (int i = 1 ; i <= n; i++)for (int len = 1 ; len <= n; len++) {int res = 2e9 ;for (int i = 1 , j = i + len - 1 ; j <= n; i++, j++) {int l = i, r = j;int sum = 0 ;while (l < r) {abs (a[l] - a[r]);min (res, sum);' ' ;return 0 ;
dp优化,时间复杂度 O ( n 2 ) O(n^2) O ( n 2 )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 #include <iostream> #include <cmath> #include <cstring> using namespace std;const int N = 5010 ;int n;int a[N];int dp[N][N]; int res[N]; int main () for (int i = 1 ; i <= n; i++)memset (res, 0x3f , sizeof res);1 ] = 0 ;for (int i = 1 , j = i + 1 ; j <= n; i++, j++) {abs (a[i] - a[j]);2 ] = min (res[2 ], dp[i][j]);for (int len = 3 ; len <= n; len++) {for (int i = 1 , j = i + len - 1 ; j <= n; i++, j++) {1 ][j - 1 ] + abs (a[i] - a[j]);min (res[len], dp[i][j]);for (int i = 1 ; i <= n; i++)' ' ;return 0 ;
【状压dp】Avoid K Palindrome 🔥
https://atcoder.jp/contests/abc359/tasks/abc359_d
题意:给定一个长度为 n ≤ 1000 n\le 1000 n ≤ 1000 s s s k ≤ 10 k\le10 k ≤ 10 'A','B' 和 '?'。其中 '?' 可以转化为 'A' 或 'B',假设有 q q q '?',则一共可以转化出 2 q 2^q 2 q s s s s s s k k k
思路:最暴力的做法就是 2^q 枚举所有可能的字符串,然后再 O(n) 的检查,这样时间复杂度为 O ( n 2 n ) O(n2^n) O ( n 2 n )
时间复杂度: