机器学习课程设计
本文最后更新于 2025年1月18日 凌晨
前言
本项目是机器学习课程设计, 主要内容是利用 机器学习和深度学习 算法实现 高糖预测 功能.
repo: https://github.com/Mr-LUHAOYU/MachineLearningClassDesign
小组成员: 19220432 陆昊宇, 19220448 董文杰, 19220430 沈子毅
一. 数据预处理
数据集包含 16 个糖前用户多天的时序特征和血糖真值. 其中特征包括: 血容量脉冲信号 (BVP), 皮肤电活动 (EDA), 皮肤温度 (TEMP), 三轴加速度计 (ACC), 心率 (HR), 搏动间隔 (IBI). 同时还包括时间戳 (datatime) 和血糖浓度 (glucose).
我们对每一个用户的时序数据分别进行预处理和保存. 内容包括:
- 数据映射: 我们将每个用户的多天数据以 0.25ms 的粒度映射到一天的 ms 中.
- 缺失异常值处理: 我们利用真实的数据进行线性 (linear) 循环插值处理, 从而将所有的缺失值和异常值进行填充.
- 归一化: 我们对每一个用户除了时间戳和血糖值之外的其他特征进行 最大最小值 归一化处理, 使得其值域落在 之间.
- 可视化: 我们利用
subplots绘制 16 个用户的 时间-血糖趋势图 以便于观察数据分布从而决策出合适的阶段划分.
最终对于每一个用户可以得到类似于下面结构的 时序特征 矩阵, 共 9 个原始特征:
| datetime | eda | temp | ibi | acc_x | acc_y | acc_z | bvp | hr |
|---|---|---|---|---|---|---|---|---|
| 0 | 0.322 | 0.780 | 0.486 | 0.681 | 0.577 | 0.285 | 0.469 | 0.342 |
| … | … | … | … | … | … | … | … | … |
| 345599 | 0.322 | 0.780 | 0.472 | 0.684 | 0.577 | 0.285 | 0.470 | 0.343 |
二. 特征工程
本阶段, 我们首先利用 快速傅里叶变换 (FFT) 和 预训练模型 (xgboost) 删除无关特征 bvp 和 ibi. 然后将剩余的的合理特征以 分钟为时序间隔进行特征提取, 最终得到可用于训练和预测的数据.
2.1 特征删除
在进行特征提取前, 我们有必要对数据进行第一轮降维. 为此我们引入 快速傅里叶变换 (FFT) 和 预训练模型 (xgboost).
对于 FFT 策略. 我们尝试将所有特征关于血糖值一一进行频谱分析比对, 如果两者频谱图在相同量纲下趋势相同则认为该特征与血糖变化趋势强相关, 反之则认为弱相关, 需要排除该特征. 最终发现 bvp 和 ibi 两个特征与血糖呈现弱相关 (如下图所示), 我们将这两个特征维度直接删除.
对于预训练策略. 我们引入 xgboost 模型, 得到 16 人的预训练数据 (如下表所示). 其中 表示从所有特征中选择预训练特征的数量, 其余特征数值表示特征与血糖的逆关系, 数值越大表明该特征与血糖越无关. 可以发现无论从所有特征中选择多少个用于预训练的特征, bvp 和 ibi 始终都和血糖的关系最弱, 因此需要删除 bvp 和 ibi 这两个特征. 此时结论与使用 FFT 策略的结论互相佐证.
| cnt | datetime | eda | temp | ibi | acc_x | acc_y | acc_z | bvp | hr |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 1.0 | 3.125 | 2.25 | 7.6875 | 6.3125 | 5.8750 | 6.0000 | 8.9375 | 3.8125 |
| 2 | 1.0 | 2.125 | 1.25 | 6.6875 | 5.3125 | 4.8750 | 5.0000 | 7.9375 | 2.8125 |
| 3 | 1.0 | 1.375 | 1.00 | 5.6875 | 4.3125 | 3.8750 | 4.0000 | 6.9375 | 1.8125 |
| 4 | 1.0 | 1.000 | 1.00 | 4.6875 | 3.3125 | 2.8750 | 3.0625 | 5.9375 | 1.1250 |
| 5 | 1.0 | 1.000 | 1.00 | 3.6875 | 2.3125 | 1.8750 | 2.1250 | 4.9375 | 1.0625 |
| 6 | 1.0 | 1.000 | 1.00 | 2.7500 | 1.5625 | 1.2500 | 1.5000 | 3.9375 | 1.0000 |
| 7 | 1.0 | 1.000 | 1.00 | 1.8750 | 1.0625 | 1.0625 | 1.0625 | 2.9375 | 1.0000 |
2.2 特征提取
在经过 2.1 步删除了两个特征后, 还剩 7 个特征需要进行提取. 我们以 5 分钟为一个阶段. 特别的, 为了更好的利用时序数据, 我们让每一个 5 分钟区间都和前一个 5 分钟区间重合 4 分钟 (第一个区间除外). 这样对于一天共 1440 分钟, 我们会得到 1436 个区间. 也就是每个用户一天共有 1436 条样本数据.
对于 7 个特征. 我们尝试提取每一个区间中的均值 (mean) , 最小值 (min), 最大值 (max), 标准差 (std), 中位数 (median), 极差 (pk), 峰值因子 (kurt), 主频 (dominant frequency), 频谱质心 (spectral centroid), 频谱能量 (spectral energy) 和频谱带宽 (spectral bandwidth). 如果提取出来的特征与血糖的互信息计算结果小于临界值, 则认为该特征提取无效, 不加入最终的样本矩阵, 否则将其加入提取后的矩阵. 其中临界值为超参数.
对于血糖属性. 我们构造一个递推式生成函数用于计算每一个区间中发生高糖的先验概率. 具体的, 我们假设第 i 个区间超过阈值 (140 mg/dL) 的概率为 , 频率为 . 由于 数组是唯一确定且容易得到的, 故我们应当考虑 与 之间的关系. 这里主要考虑相邻时刻的关系, 于是得到了如下两个必要条件:
对于第一个式子, 它的目的是保证 与 具有相同的单调性. 对于第二个式子, 我们需要保证概率接近频率, 并且越接近频率的值越可以被接受, 使用 分布可以很好的完成这个任务, 即 . 同时, 为了缩小 之间的差异, 令阈值表示为 , 则有 . 对于任意给定的阈值 , 参数 均可使用二分法求得. 于是又当 时, .
最终可以得到 16 个用户共 16 个 的特征提取结果矩阵. 其中 为提取后的特征数量, 共 35 个.
2.3 特征相关性分析
对于上述 2.2 提取的结果, 我们有必要分析这全新的 个特征是否需要全部保留. 具体的, 如果两个特征之间的相关性超过了临界值, 则认为两个特征可以被其中一个近似代替, 删除其中一个特征即可. 原始的相关性矩阵如下 (以第 9 个用户为示例):
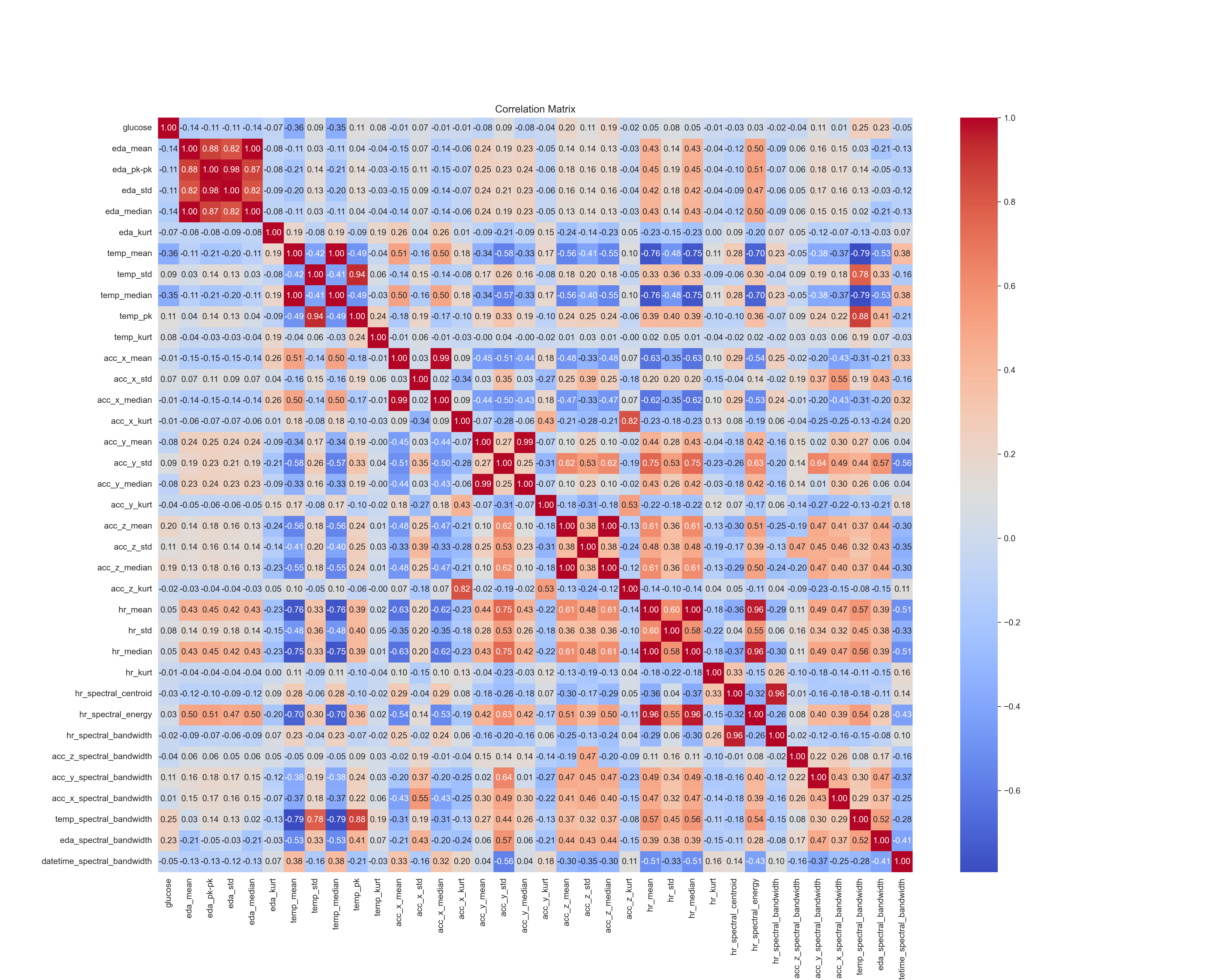
对于相关性超过阈值的两个特征, 我们只保留其中一个. 得到最终的特征相关性矩阵如下 (共 21 个有效特征):
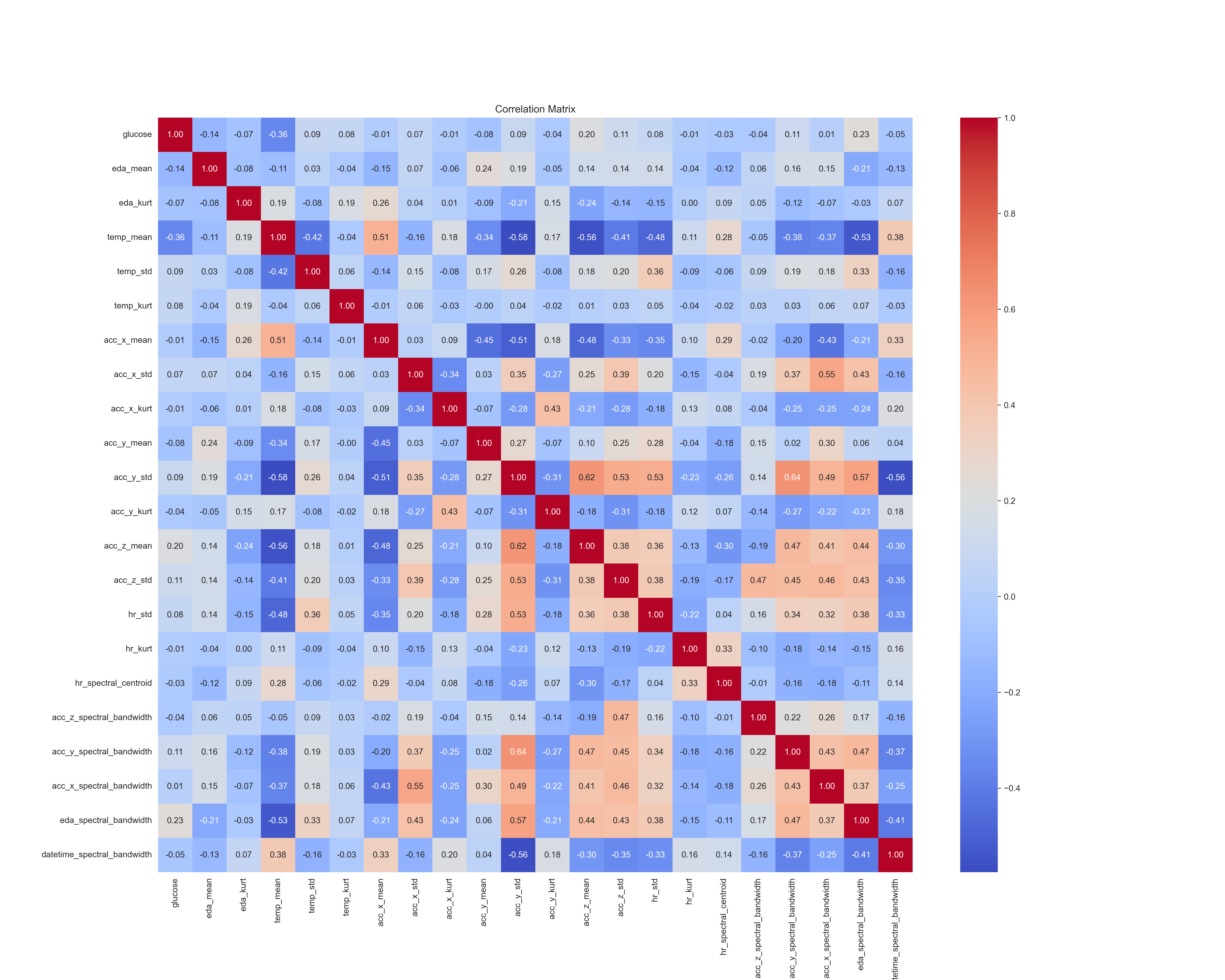
2.4 特征添加
为了更好的利用数据, 我们添加 Demographics.csv 数据文件中的性别 (Gender) 和糖化血红蛋白指数 (HbA1c) 两个特征. 其中性别编码为 0 和 1, 糖化血红蛋白指数按 均值方差 归一化处理. 同时添加了一开始处理出来的时序特征, 即时间戳转化数据 (datetime). 最终有 24 维的特征数据.
三. 模型构建与评估
3.1 正负样本平衡
由于高糖阶段相对于非高糖阶段极少, 因此有必要调整正负样本的比例. 我们定义高糖阶段为正样本, 非高糖阶段为负样本. 引入 过采样方法来提升正例样本的数量. 具体的, 对于每个用户的 1436 条样本数据, 如果高糖概率超过了临界值, 则定义为高糖阶段, 反之为非高糖阶段, 我们提升高糖阶段的样本量. 其中临界值为超参数.
3.2 模型1 XGBoost
我们首先使用机器学习算法中的串行式集成学习模型 XGBoost 进行训练与测试. 具体的, 我们在 个用户的数据集中选择 人的数据作为训练集, 人的数据作为验证集, 训练得到最佳超参数组合. 剩余 人的数据作为测试集, 得到 统计高糖发生次数 的准确率 (Accuracy), 召回率 (Recall), 均方误差 (RMSE) 和 分数的结果如下:
| info | average | min | max |
|---|---|---|---|
| 0.7704 | 0.7211 | 0.8152 | |
| 0.6391 | 0.5689 | 0.7624 | |
| 38.7937 | 29.3371 | 47.3028 | |
| -4.2223 | -8.1471 | -2.1911 |
3.3 模型2 MLP
接着我们使用深度学习算法中的多层感知机模型 MLP 进行训练与测试. 同样的, 我们在 个用户的数据集中选择 人的数据作为训练集, 人的数据作为验证集, 训练得到最佳超参数组合. 剩余 人的数据作为测试集, 得到 统计高糖发生次数 的准确率 (Accuracy), 召回率 (Recall), 均方误差 (RMSE) 和 分数的结果如下:
| info | average | min | max |
|---|---|---|---|
| 0.7703 | 0.7201 | 0.8152 | |
| 0.6414 | 0.5759 | 0.7624 | |
| 38.7937 | 29.3371 | 47.3028 | |
| -4.2094 | -8.1471 | -2.7533 |
四. 项目总结
对于项目所有涉及到的数据文件和 python 文件.
- 在数据预处理中. 我们首先编写了
data_gen.py文件将原始数据中多天的数据映射到了一天得到了./data/merged_data/数据集. 接着对这些以一天为最大单位的文件进行了清洗, 得到了./data/cleaned_data/数据集. - 在特征工程中. 我们首先编写了
data_draw.py文件中的draw_fft()函数可视化筛选出不合适的特征并删除了 bvp 和 ibi 两个特征, 接着编写了data_extractor.py文件得到了初步提取出来的以 5 分钟为一阶段的数据集./data/extraction_data/. 然后编写了data_draw.py文件中的draw_corr_matrix()函数可视化筛选出相关性较低的特征并调用data_extractor.py文件提取上述筛选出来的特征得到了./data/extraction_data_reduced/数据集. 在后续模型调用的逻辑中, 我们还添加了./data/Demographics.csv中的性别和糖化血红蛋白两个特征. - 在模型构建与评估中. 为了平衡正负样本的数量, 我们编写了
data_balance.py文件以过采样正例样本. 最后编写了models.py模型文件建立了机器学习模型 XGBoost 和深度学习模型 MLP 并在main.py中调用这两个模型来训练验证并预测, 得到了最终的预测结果.