目标检测

目标检测最终效果图(三要素:框、类别、置信度)
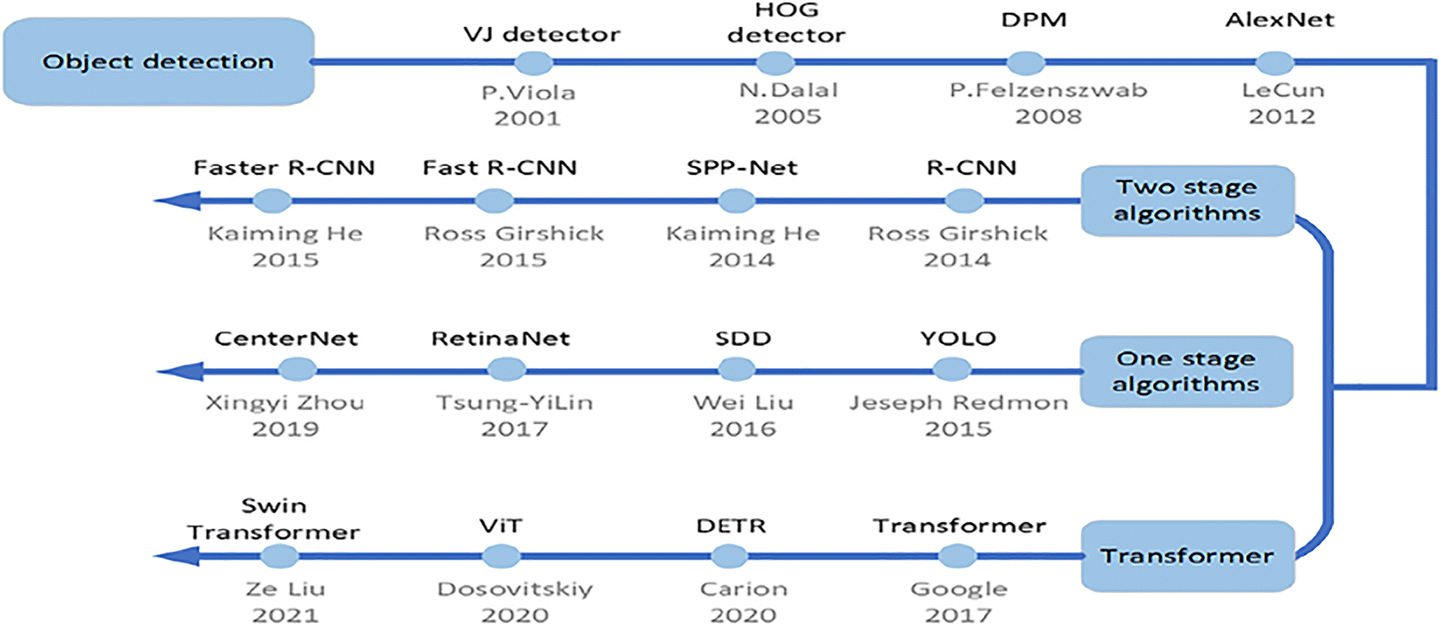
目标检测发展图 1
本文介绍计算机视觉中的目标检测 (Object Detection) 任务。部分内容参考:
- A survey: object detection methods from CNN to transformer 1
- Object Detection in 20 Years: A Survey 2
基本原理
目标检测可以分解为「定位 + 分类」两个子任务。考虑到图像分类已经在上一章介绍过了,因此本章我们重点关注目标定位。
各种框
框有各种称呼,比如:真实框、检测框、边界框、锚框等等。但无论哪种说法,本质上就是一个包裹对象的矩形边界罢了。当然其中的锚框一般定义为以某个像素为中心的框。一个框一般可以用以下两种方式定义:
- 中心点坐标 \((x,y)\) 与框的宽 \(w\) 与高 \(h\),用四元组表示为 \((x,y,w,h)\);
- 左上角的点坐标 \((x_1,y_1)\) 与右下角的点坐标 \((x_2,y_2)\),用四元组表示为 \((x_1,y_1,x_2,y_2)\)。
交并比
为了量化预测框与真实框之间的差异,定义了交并比 (Intersection over Union, IoU) 这个概念。一图胜千言:
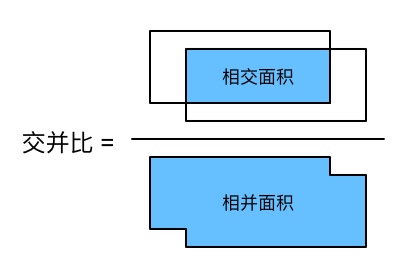
图 1. 交并比计算示意图
非极大值抑制
在对一张图像进行目标检测时,模型可能会输出很多预测框,为了简化输出,我们需要筛选出最合适的预测框,为此我们引入非极大值抑制 (non‐maximum suppression, NMS) 算法。
定义待输出的预测框列表为 \(L\),定义每个预测框中类别的预测概率为置信度。算法输入为检测框列表、置信度列表和 IoU 阈值,算法输出为最终的检测框列表与置信度列表。NMS 算法流程如下:
- 给 \(L\) 按照置信度降序排序;
- 取出 \(L\) 中置信度最大的预测框 \(B_1\),枚举剩余所有的预测框 \(B_i (i\neq 1)\),从 \(L\) 中去除与 \(B_1\) 的交并比超过阈值 \(T\) 的检测框;
- 重复步 \(2\) 直到所有检测框都被遍历到。
一句话总结就是:只保留交并比相近的检测框中,置信度最大的那一个。
性能度量
目标检测任务需要人为预先标记真实框 (ground-truth bounding box),那么就可以很方便地与模型输出的预测框进行对比,从而量化模型的性能。综合性比较强的度量指标为平均精度 (Average Precision, AP),其中的四个组成部分与二分类的混淆矩阵类似,只不过定义略有不同:
- TP:预测框与真实框的 IoU 达到了阈值,预测类别与真实类别相同;
- FP:预测框与真实框的 IoU 没达到阈值,预测类别与真实类别相同;
- FN:没有被匹配的真实框数量;
- TN:不包含目标的预测框数量(由于这类数量很多,一般不看)。
可以看出 AP 其实就是一个类别的 ROC 曲线下的 AUC 面积。最后可以给所有类别的 AP 取一个均值得到平均精度均值 (mean Average Precision, mAP)。
两阶段目标检测
Seletive Search
锚框搜索算法。
RCNN
TODO
SPPNet
为了解决输入图像尺寸受限的问题,SPP-Net 提出了空间金字塔池化 (Spatial Pyramid Pooling, SPP) 的网络层。
Fast R-CNN
TODO
Faster R-CNN
该算法对应论文为:Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks 4。本部分的一些解读参考:《一文读懂 Faster RCNN》5。
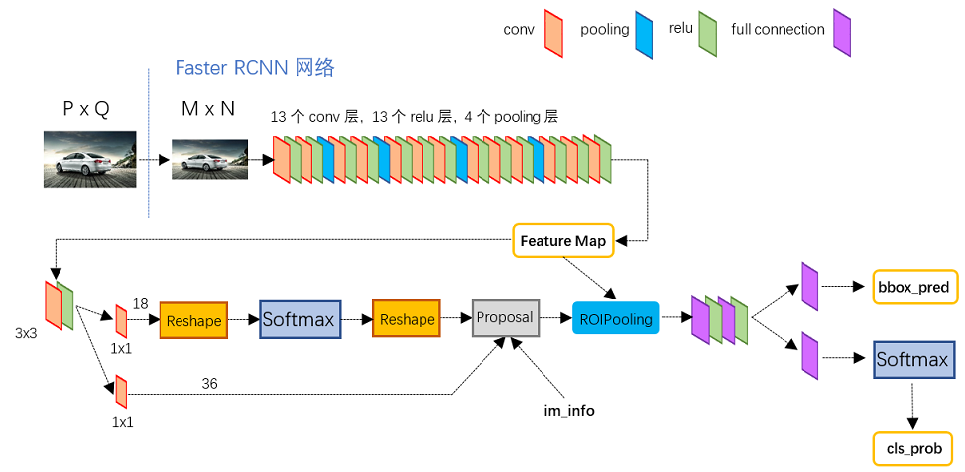
图 2. Faster RCNN 网络结构
Faster R-CNN 提出了区域候选网络 (Region Proposal Network, RPN) 策略,用以替代 SS 算法。RPN 提出了锚点的概念:特征图中的「一个元素」都对应了原始图像的「一个感受野区域」,该区域的中心像素称为锚点 (Anchor) ,以锚点为中心按一定的纵横比 (ratio) 和尺度 (scale) 绘制的框称为锚框 (Anchor box)。
单阶段目标检测
YOLO
我们重点关注 YOLO v1 网络。
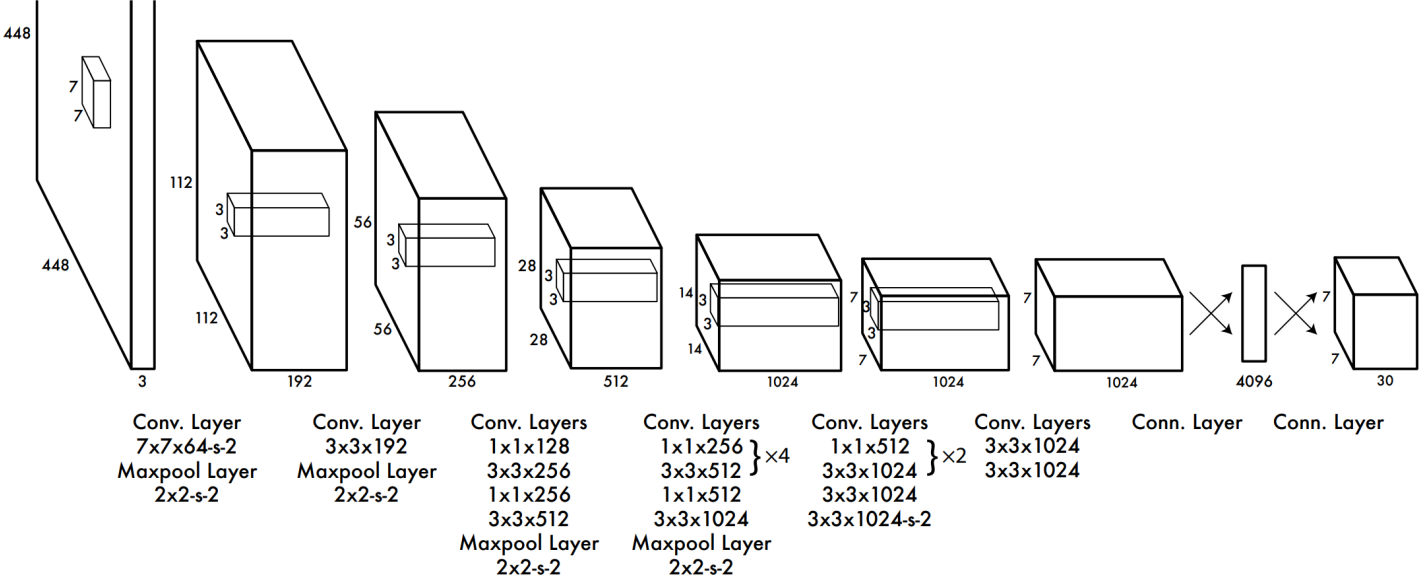
图 3. YOLO v1 网络结构
模型损失。解释一下最后输出的 \(7 \times 7 \times 30\) 的张量。该模型在 VOC 2007 上进行的训练与测试,该数据集有 \(20\) 个类别。YOLO v1 算法给每一个网格生成 2 个检测框,每一个检测框用 \([x,y,w,h,c]\) 共 \(5\) 个变量来表示,分别表示检测框的位置和检测框的置信度,置信度的计算就用 IOU 来量化。因此最后输出的 \(30\) 维的通道中,前 \(10\) 维就是两个检测框共 \(10\) 个变量,后 \(20\) 维表示网格包含类对象的条件概率。因此最后就变成了一个回归问题:
模型特点:
- 优点:检测速度快,完全达到了实时检测的效果;可以实现端到端的方式训练网络;
- 缺点:每个网格只对应一个类,所以目标密集或目标较小时,检测效果不佳;定位的误差较大,导致精度不如双阶段目标检测模型。
SSD
单镜头多框检测 (Single Shot multibox Detector, SSD) 6。
模型特点:
- 优点:SSD 几乎适用于任意规则物体的目标检测任务。
- 缺点:SSD 在小物体的目标检测任务上仍差于 Faster R-CNN;大量的参数需要人工设置。
基于 Transformer 的目标检测
DETR
首篇基于 Transformer 的目标检测算法。
模型特点:
- 优点:在较大目标上的检测效果很好;提出了新的目标检测 pipeline,需要更少的先验信息;从图像输入到检测框输出的端到端模型;不需要特别设计的层,易于进一步修改。
- 缺点:框架并不完美,存在收敛速度慢、小目标检测效果差等缺陷。
小目标检测
对于小目标 (Small Object) 的判断通常采用以下两种方式:
- 相对小目标:目标的尺寸低于原图尺寸的 \(10\%\);
- 绝对小目标:目标的尺寸小于 \(32\times 32\) 像素(MS-COCO 数据集)。
当小目标的面积小于一定阈值(\(1\) 像素),则失去了检测的意义。
小目标检测任务的难点:1)小目标的视觉表现不明显,可利用信息少,更难提取有效的特征;2)更易受到光照、遮挡、聚集等因素的干扰;3)数据集短缺,常用数据集中小目标的占比不足,导致模型对小目标的泛化能力弱。
针对小目标检测存在的难点,现有小目标检测方法可分为如下几种:
- 从数据入手:把小目标拷贝多份到原始图像上 7;
- 从特征入手:把各个阶段的特征融合到一起 3、针对每一个阶段的特征都训练一个分类回归器 6、基于 GAN 网络将低分辨率图像超分辨并利用上超分辨后的图像特征 8。
开放词汇目标检测
YOLO-World 9 借鉴了 CLIP 的跨模态对比学习方法进行预训练,使得下游任务可以进行 zero-shot learning。
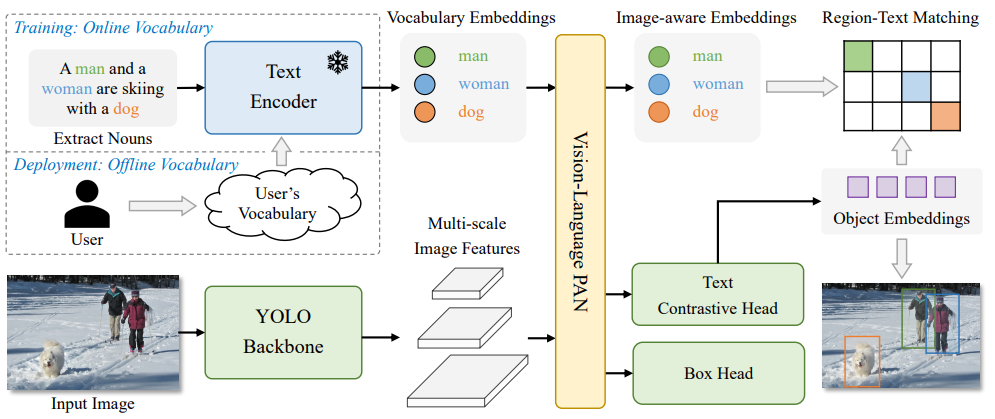
图 4. YOLO-World: Real-Time Open-Vocabulary Object Detection
-
A survey: object detection methods from CNN to transformer | MTA 2022 - (link.springer.com) ↩↩
-
Object Detection in 20 Years: A Survey | IEEE 2023 - (arxiv.org) ↩
-
He K, Zhang X, Ren S, et al. Spatial pyramid pooling in deep convolutional networks for visual recognition[J]. IEEE transactions on pattern analysis and machine intelligence, 2015, 37(9): 1904-1916. ↩
-
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks | NeurIPS 2015 - (arxiv.org) ↩
-
Liu W, Anguelov D, Erhan D, et al. Ssd: Single shot multibox detector[C]//Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11–14, 2016, Proceedings, Part I 14. Springer International Publishing, 2016: 21-37. ↩↩
-
Bosquet, Brais, et al. "A full data augmentation pipeline for small object detection based on generative adversarial networks." Pattern Recognition 133 (2023): 108998. ↩
-
Li J, Liang X, Wei Y, et al. Perceptual generative adversarial networks for small object detection[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2017: 1222-1230. ↩
-
Cheng T, Song L, Ge Y, et al. Yolo-world: Real-time open-vocabulary object detection[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024: 16901-16911. ↩