机器学习导读
本文记录「机器学习」相关内容,初稿完成于大二下学期。由于本人比较喜欢自顶向下式地动手学习领域知识,而现在的教材大多都是扁平化的平铺知识点,因此本文的组织结构就按照代码逻辑中的 数据、模型、评价 三个方面顺序展开。
考虑到笔记内容的重要性与时效性,本文会不断完善。部分参考内容 1 2 3 见本文文末。
一些衍生内容:
- 课程设计。我与团队成员一起,使用 XGBoost 和 MLP 实现了高糖预测 4;
- 深度学习。详见第五学期的 神经网络与深度学习 课程笔记;
- 强化学习。该领域主要通过建立「策略概率模型」来学习数据的动态变化,从而让智能体做出最佳决策。笔记内容待定。
机器学习的任务
在我看来,机器学习是一种「通过学习数据规律,实现诸如 预测、生成、决策 等实际任务的」研究范式。下表罗列了三类机器学习任务的实际建模策略:
表 1. 机器学习的建模策略
| 概率建模类型 | 核心问题 | 实际应用 |
|---|---|---|
| 条件概率建模 | 给定输入,输出是什么? | 分类、回归、翻译、检测 |
| 联合概率建模 | 数据如何生成? | 生成、修复、异常检测 |
| 策略概率建模 | 如何行动以最大化收益? | 强化学习、资源优化、主动学习 |
由于机器学习领域十分宏大,衍生出的很多子分支也极具研究价值,因此本文仅仅针对传统的机器学习本身展开。深度学习、强化学习等子领域不在本文的讨论范围内。
机器学习的术语
- 计算学习理论:概率近似正确 (Probably Approximately Correct, PAC) 理论。即以很高的概率得到很好的模型 \(P(f(x)- y \le \epsilon) \ge 1 - \delta\);
- P 问题:在多项式时间内计算出答案的解;
- NP 问题:在多项式时间内检验解的正确性;
- 学习任务:监督学习、无监督学习、半监督学习、强化学习;
- 泛化能力:应对未见样本的平均拟合能力;
- 假设空间:所有可能的样本组合构成的集合空间;
- 独立同分布假设:历史和未来的数据来自相同的分布;
- No Free Launch 理论:没有绝对好的算法,只有适合的算法。好的算法来自于对数据的好假设、好偏执。在实际应用时,我们需要大胆假设,小心求证。
机器学习的步骤
- 获取数据。获取数据后我们要对数据进行预处理,例如:数据清洗、特征筛选等;
- 确定模型。有了数据我们需要根据数据特点和任务场景确定好待学习的模型,例如:线性模型、非线性模型等;
- 学习准则。我们还需要根据学习任务确定学习准则,也就是需要确定目标函数/损失函数,例如:交叉熵损失、平均方差等;
- 优化方法。有了损失函数以后我们就可以利用最优化理论中的各种优化方法来迭代求得最佳得模型参数,例如:梯度下降法、动量法等。
机器学习的模型误差
在模型训练的过程中,我们会不断地对其性能进行评价,模型地输出与理想输出之间的差距就被称为误差。
误差类别
针对不同的数据,模型会对应不同的误差。有以下四种:
- 训练误差。针对训练数据而言,即模型在训练集上的预测错误率。训练轮数越多或模型的复杂度越高,训练误差越小;
- 验证误差。针对验证数据而言,即模型在验证集上的预测错误率;
- 测试误差。针对测试数据而言,即模型在测试集上的预测错误率;
- 泛化误差。针对测试数据而言,即模型在多个测试集上「测试误差的期望」。
一般来说,训练误差 \(<\) 验证误差 \(\approx\) 测试误差 \(\approx\) 泛化误差。
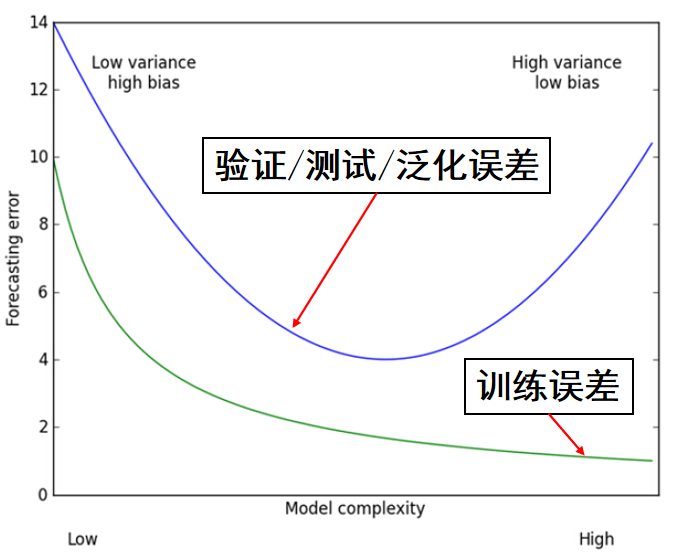
图 1. 训练误差与测试误差随模型复杂度的变化趋势图
可以看到,模型复杂度不够就会欠拟合导致测试误差较高,模型复杂度过高就会过拟合也会导致测试误差较高。
误差规避
为了避免模型发生欠拟合或过拟合,我们需要对模型做出一些约束或者设置一些训练策略。
欠拟合解决方法。欠拟合就说明模型复杂度不够,我们需要增加模型的复杂度,常见的规避欠拟合的方法如下:
-
决策树:增加树的深度;
-
神经网络:增加训练轮数。
过拟合解决方法。与欠拟合相对,常见的规避过拟合的方法如下:
- 早停法 (Early Stopping)。当发现有过拟合现象就停止训练。代码实现上可以体现为取最佳模型为验证误差最小时的模型;
- 增加惩罚 (Penalizing Large Weight)。在经验风险上加一个「正则化」项;
- 集成学习思想 (Ensemble Learning)。用多个弱分类器投票产生结果从而降低模型偏差;
- 剔除部分神经元 (Dropconnection)。在神经网络的全连接层中剔除部分神经元,即让部分神经元存储的值为 \(0\)。
正则化。我们有必要先理清楚正则化项都有哪些以及对应的数学表达式是什么。如下表:
表 2. 正则化项表(2 范数表达式的右下角标可以忽略,因为默认的范数一般都指 2 范数)
| 机器学习中的称呼 | 实际名称 | 数学表达式 |
|---|---|---|
| / | \(p\) 范数的 \(k\) 次方 | \(\displaystyle \|\boldsymbol{x}\|_p^k = \left ( \left ( \sum_{i = 1}^{N}\vert x_i \vert^{p} \right)^{1/p} \right)^k\) |
| \(L_1\) 正则化项 | \(1\) 范数 | \(\displaystyle \|\boldsymbol{x}\|_1 = \sum_{i = 1}^N \vert x_i \vert\) |
| / | \(2\) 范数 | \(\displaystyle \|\boldsymbol{x}\| = \left (\sum_{i = 1}^{N}\vert x_i \vert^{2} \right)^{1/2}\) |
| \(L_2\) 正则化项 | \(2\) 范数的平方 | \(\displaystyle \|\boldsymbol{x}\|_2^2 = \left ( \left ( \sum_{i = 1}^{N}\vert x_i \vert^{2} \right)^{1/2} \right)^2 = \sum_{i = 1}^{N}\vert x_i \vert^{2} = \sum_{i = 1}^{N}x_i^{2}\) |
通过给损失函数添加正则化项,不仅可以防止过拟合,其中的 \(L_1\) 正则化项还可以进行特征选择,因为其使得不重要特征的系数被惩罚得很小,通过特征选择也可以降低计算量从而提升计算效率。
然而给损失函数添加正则化项并非万金油选项。在整个损失函数中正则化项有着举足轻重的意义,一旦正则化项的系数发生了微小的变动,对于整个模型的影响都是巨大的。因此有时添加正则化项并不一定能带来泛化性能的提升。
误差来源
如何从理论上来解释模型的泛化误差呢?我们引入「偏差方差分解」理论。
在此之前我们需要知道偏差、方差和噪声的基本定义:
- 偏差:学习算法的期望输出与真实结果的偏离程度。刻画模型本身的拟合能力;
- 方差:使用同规模的不同训练集进行训练时给模型带来的性能变化。刻画数据扰动给模型带来的影响;
- 噪声:当前任务上任何算法所能达到的期望泛化误差的下界。刻画问题本身的难度。
偏差方差分解。我们尝试对泛化误差的组成进行分解。先进行以下的符号定义:\(x\) 为测试样本,\(y_D\) 为 \(x\) 在数据集中的标签,\(y\) 为 \(x\) 的真实标签,\(f(x;D)\) 为模型在训练集 \(D\) 上学习后的预测输出,\(E(f; D)\) 为模型的泛化误差。以回归任务为例,有以下的变量定义:(\(\mathbb{E}\) 表示期望)
- 模型在测试样本上的期望输出:\(\overline{f}(x) = \mathbb{E}_D[f(x;D)]\)
- 使用相同规模训练集训练出来的不同模型在测试样本上的预测方差:\(var(x) = \mathbb{E}_D[(\overline{f}(x) - f(x;D))^2]\)
- 模型的期望输出与真实标记的偏差:\(bias^2(x) = (\overline{f}(x) - y)^2\)
- 噪声:\(\epsilon ^2 = \mathbb{E}_D[(y_D - y)^2]\)
经过简单的推导就可以得到偏差方差分解的结论:
即模型的泛化误差由偏差、方差和噪声三部分组成。那么模型的泛化性能也就是由学习算法的能力(偏差)、数据的充分性(方差)以及学习任务本身的难度(噪声)共同决定的。因此给定一个学习任务,我们可以从偏差、方差和噪声三个角度优化模型:
- 使偏差尽可能小:选择合适的学习算法充分拟合数据;
- 使方差尽可能小:提升模型的抗干扰能力来减小数据扰动产生的影响;
- 使噪声尽可能小:选择合适的数据增强方法来减小因为数据本身带来的误差。
偏差方差窘境。其实偏差和方差是有冲突的,这被称为偏差方差窘境(bias-variance dilemma)。对于给定的学习任务:
- 模型一开始拟合能力较差,对于不同的训练数据不够敏感,此时泛化误差主要来自偏差;
- 随着训练的不断进行,模型的拟合能力逐渐增强,这会加剧模型对数据的敏感度,从而使得方差主导了泛化误差;
- 在模型过度训练后,数据的轻微扰动都可能导致预测输出发生显著的变化,此时方差就几乎完全主导了泛化误差。
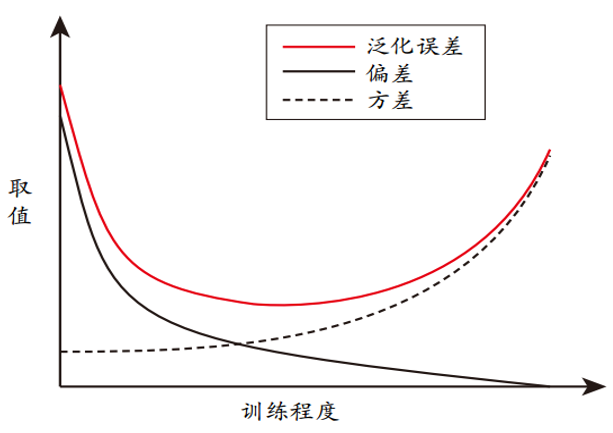
图 2. 泛化误差与偏差、方差的关系示意图
机器学习的超参调优
所谓的调参,是基于超参数进行的。我们知道一个模型有「可训练」的参数和「不可训练」的超参数,调参调的就是这里的超参数。在将数据集划分为训练集、验证集和测试集的情况下,一般使用训练集学习可训练的参数,使用验证集来度量不同超参数组合下的模型性能,得到最佳的超参数组合后才能最终使用测试集进行测试。
常见的超参调优方法 5 有:网格搜索、随机搜索、贝叶斯优化。