自然语言处理导读
本文记录自然语言处理的入门笔记。部分内容参考:
- 理论:
- 实践:
成绩组成
平时 10%,作业+实验 40%,期末 50%。
基本概念
自然语言处理 (Natural Language Processing, NLP) 是一个人工智能研究领域,也可以理解为一种技术,主要用于处理人类自然语言「文本数据」从而完成「预测、生成」等下游任务。
研究内容
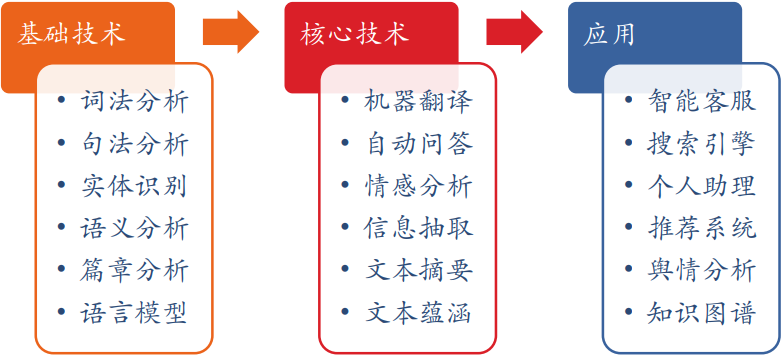
图 1. NLP 的主要研究内容(源自上课期间对课件的快照)
编排逻辑
与计算机视觉领域「任务少、模型多」的特点相比,自然语言处理领域更多偏向于「任务多、模型少」的特点。但为了统一文章的结构安排,我还是以「任务 \(\to\) 模型」的逻辑进行内容编排。
为了简化理解难度,我将 NLP 任务抽象为了以下两类:
掌握了这两类任务对应的模型结构后,在遇到自然语言问题时,如果可以将其建模为分类/生成任务,那么定义好任务的输入与输出后就可以套用这些模型从而解决问题。
注意:相较于图像/视频数据只是简单的像素点的叠加,序列(自然语言)数据很复杂,涉及到了很多语言本身的规则。因此每篇文章会在开始介绍各种模型之前先补充「将自然语言任务转化到序列分类/生成任务」的理论基础。