语音信号处理
本文记录语音信号处理的入门学习笔记。部分参考内容如下:
- 理论:《现代语音信号处理(Python版)》1、配套代码、全书目录
- 实践:Audio Course - huggingface.co。
成绩组成:出勤+测验(*2)+期末大项目。
语音数据处理
数据类型
语音信号数字化。原始的模拟信号首先被麦克风捕捉,并由声音信号转化为电信号。接下来,电信号会由模数转换器 (Analog-to-Digital Converter, ADC) 经由采样过程转换为数字化表示。
人类可感知的声音频率范围:20 Hz - 20 kHz,声音强度范围:0 dB - 130 dB。
语音信号大约有三种表示方法:时域表示(时谱图)、频域表示(频谱图)、时频域表示(语谱图)。其余的表示方法都是在前三者的基础之上进行一定的变换得来,但本质不变。具体地:
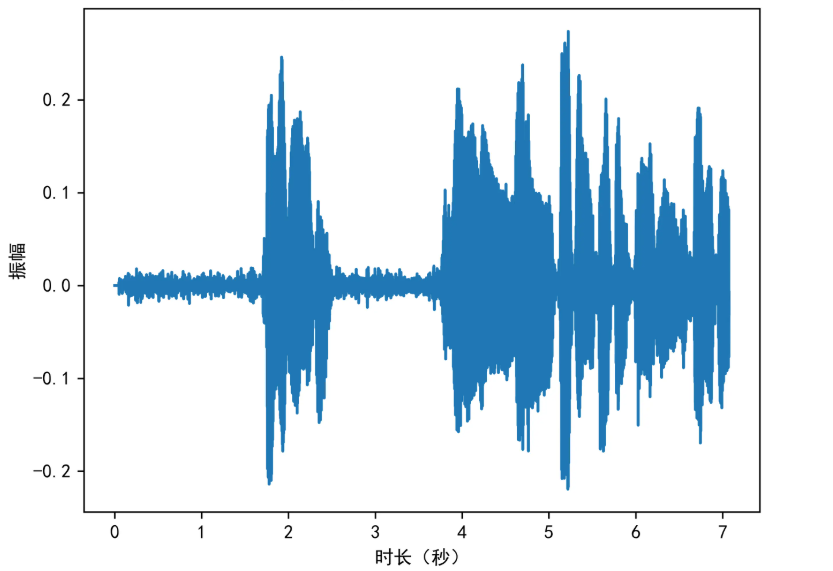 |
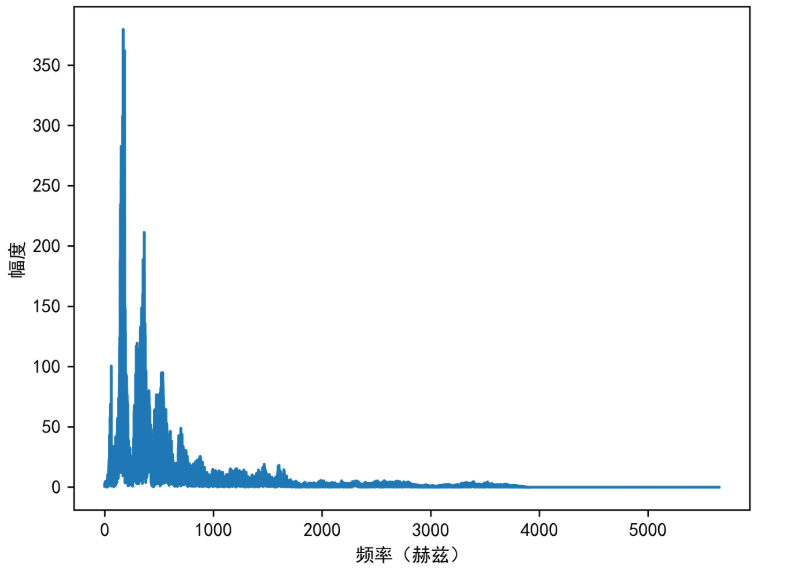 |
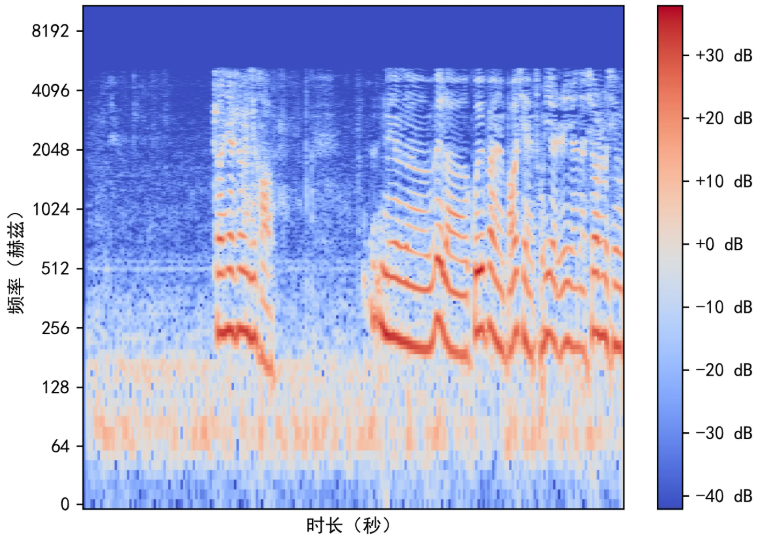 |
|---|---|---|
| 时谱图 | 频谱图 | 语谱图 |
特征工程
频域宽度、过零率等。
Tip
接下来将会介绍深度学习在语音数据上的高阶应用,一些基础的语音技术比如:语音增强、回声消除、声源定位等内容本文不展开。
语音分类
一些细分场景比如:说话人识别(不限于人类,能发出声音的都行)、情感分析(根据声音判断你的情感状态)。
语音转文本
文本转语音
-
梁瑞宇, 王青云, 谢跃, 唐闺臣. 现代语音信号处理(Python版)[M]. 北京: 机械工业出版社, 2022. ↩