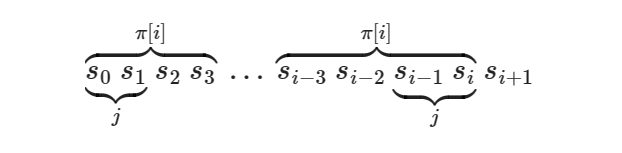代码模板 (Python)
前言
此模板包含 Python 常用代码模板、示例,以及经典问题的题解和链接。
有不严谨和错误的地方还望评论区斧正。
常用数据结构 API
列表
int 转 list
num = 123
nums = list ( map ( int , str ( num )))
list(int) 转 int
nums = [ 1 , 2 , 3 ]
num = int ( '' . join ( map ( str , nums )))
def lst_int ( nums ):
return int ( '' . join ( map ( str , nums )))
列表特性
比较大小的时候,不管长度如何,依次比较到第一个元素不相等的位置
比如 [1, 2, 3] < [2, 3] 因为在比较 1 < 2 的时候就终止。
嵌套列表推导:展平二维数组
nums = [ e for row in matrix for e in row ]
队列
from collections import deque
list1 = [ 0 , 1 , 2 , 3 ]
q = deque ( list1 )
q . append ( 4 ) # 向右侧加
q . appendleft ( - 1 ) # 向左侧加
q . extend ( 可迭代元素 ) # 向右侧添加可迭代元素
q . extendleft ( 可迭代元素 )
q = q . pop () # 移除最右端并返回元素值
l = q . popleft () # 移除最左端
q . count ( 1 ) # 统计元素个数 1
# 返回 string 指定范围中 str 首次出现的位置
string . index ( str , beg = 0 , end = len ( string ))
string . index ( " " )
list ( map ( s . index , s )) # 返回字符索引数组,如 "abcba"-> [0,1,2,1,0]
字典
d . pop ( key ) #返回 key 对应的 value 值,并在字典中删除这个键值对
d . get ( key , default_value = None ) #获取 key 对应的值,如果不存在返回 default_value
d . keys () #键构成的可迭代对象
d . values () #值构成的可迭代对象
d . items () #键值对构成的可迭代对象
d = defaultdict ( list ) # 指定了具有默认值空列表的字典
d [ key ] = value
字典推导器:字母表对应下标
dic = { chr ( i ) : i - ord ( 'a' ) + 1 for i in range ( ord ( 'a' ), ord ( 'z' ) + 1 )}
也可以使用 zip 初始化 dict
2606. 找到最大开销的子字符串 - 力扣(LeetCode)
dic = dict ( zip ( chars , vals ))
for x in s :
y = dic . get ( x , ord ( x ) - ord ( 'a' ) + 1 )
Counter
from collections import Counter
list1 = [ "a" , "a" , "a" , "b" , "c" , "c" , "f" , "g" , "g" , "g" , "f" ]
dic = Counter ( list1 )
print ( dic )
#Counter({'a': 3, 'g': 3, 'c': 2, 'f': 2, 'b': 1})
list1 = [ "a" , "a" , "a" , "b" , "c" , "f" , "g" , "g" , "c" , "11" , "g" , "f" , "10" , "2" ]
print ( Counter ( list1 ) . most_common ( 3 ))
#结果:[('a', 3), ('g', 3), ('c', 2)]
list1 = [ "a" , "a" , "a" , "b" , "c" , "f" , "g" , "g" , "c" , "11" , "g" , "f" , "10" , "2" ]
print ( Counter ( list1 ) . most_common ( 1 ))
#结果:[('a', 3)]
most_common(k) 时间复杂度 O ( n log k ) O(n \log k) O ( n log k )
map 映射函数
用法:
map ( function , iterable , ... )
def square ( x ) : # 计算平方数
return x ** 2
map ( square , [ 1 , 2 , 3 , 4 , 5 ]) # 计算列表各个元素的平方
# [1, 4, 9, 16, 25]
map ( lambda x : x ** 2 , [ 1 , 2 , 3 , 4 , 5 ]) # 使用 lambda 匿名函数
# [1, 4, 9, 16, 25]
# 提供了两个列表,对相同位置的列表数据进行相加
map ( lambda x , y : x + y , [ 1 , 3 , 5 , 7 , 9 ], [ 2 , 4 , 6 , 8 , 10 ])
# [3, 7, 11, 15, 19]
自定义 set 规则
class MySet ( set ):
def add ( self , element ):
sorted_element = tuple ( sorted ( element ))
if not any ( sorted_element == e for e in self ):
super () . add ( sorted_element )
I/O
快读快写
import sys
sys . setrecursionlimit ( 1000000 )
input = lambda : sys . stdin . readline () . strip ()
write = lambda x : sys . stdout . write ( str ( x ) + ' \n ' )
读到文件结尾
import sys
for line in sys . stdin :
line = line . strip ()
3701. 非素数个数 - AcWing 题库
import sys
n = 10 ** 7
primes = []
is_prime = [ 1 ] * ( n + 1 )
is_prime [ 0 ] = is_prime [ 1 ] = 0
for i in range ( 2 , n + 1 ):
if is_prime [ i ]: primes . append ( i )
for p in primes :
if i * p > n : break
is_prime [ i * p ] = 0
if i % p == 0 : break
a = [ 0 ] * ( n + 1 )
for i in range ( 2 , n + 1 ):
a [ i ] = a [ i - 1 ] + ( 1 if not is_prime [ i ] else 0 )
for line in sys . stdin :
input = line . strip ()
l , r = map ( int , input . split ())
print ( a [ r ] - a [ l - 1 ])
有序列表 / 有序集合
SortedList
from sortedcontainers import SortedList
SortedList 相当于 multiset
添加元素:O ( log n ) O(\log ~n) O ( log n ) s.add(val)
添加一组可迭代元素:O ( k log n ) O(k \log n) O ( k log n ) s.upadte(*iterable*)
查找元素:O ( log n ) O(\log n) O ( log n ) s.count(val),返回元素的个数
删除元素:O ( log n ) O(\log n) O ( log n ) s . r e m o v e ( v a l ) s.remove(val) s . re m o v e ( v a l )
删除指定下标元素:s . p o p ( i n d e x = − 1 ) s.pop(index =- 1) s . p o p ( in d e x = − 1 )
class SortedList :
def __init__ ( self , iterable = [], _load = 200 ):
"""Initialize sorted list instance."""
values = sorted ( iterable )
self . _len = _len = len ( values )
self . _load = _load
self . _lists = _lists = [ values [ i : i + _load ] for i in range ( 0 , _len , _load )]
self . _list_lens = [ len ( _list ) for _list in _lists ]
self . _mins = [ _list [ 0 ] for _list in _lists ]
self . _fen_tree = []
self . _rebuild = True
def _fen_build ( self ):
"""Build a fenwick tree instance."""
self . _fen_tree [:] = self . _list_lens
_fen_tree = self . _fen_tree
for i in range ( len ( _fen_tree )):
if i | i + 1 < len ( _fen_tree ):
_fen_tree [ i | i + 1 ] += _fen_tree [ i ]
self . _rebuild = False
def _fen_update ( self , index , value ):
"""Update `fen_tree[index] += value`."""
if not self . _rebuild :
_fen_tree = self . _fen_tree
while index < len ( _fen_tree ):
_fen_tree [ index ] += value
index |= index + 1
def _fen_query ( self , end ):
"""Return `sum(_fen_tree[:end])`."""
if self . _rebuild :
self . _fen_build ()
_fen_tree = self . _fen_tree
x = 0
while end :
x += _fen_tree [ end - 1 ]
end &= end - 1
return x
def _fen_findkth ( self , k ):
"""Return a pair of (the largest `idx` such that `sum(_fen_tree[:idx]) <= k`, `k - sum(_fen_tree[:idx])`)."""
_list_lens = self . _list_lens
if k < _list_lens [ 0 ]:
return 0 , k
if k >= self . _len - _list_lens [ - 1 ]:
return len ( _list_lens ) - 1 , k + _list_lens [ - 1 ] - self . _len
if self . _rebuild :
self . _fen_build ()
_fen_tree = self . _fen_tree
idx = - 1
for d in reversed ( range ( len ( _fen_tree ) . bit_length ())):
right_idx = idx + ( 1 << d )
if right_idx < len ( _fen_tree ) and k >= _fen_tree [ right_idx ]:
idx = right_idx
k -= _fen_tree [ idx ]
return idx + 1 , k
def _delete ( self , pos , idx ):
"""Delete value at the given `(pos, idx)`."""
_lists = self . _lists
_mins = self . _mins
_list_lens = self . _list_lens
self . _len -= 1
self . _fen_update ( pos , - 1 )
del _lists [ pos ][ idx ]
_list_lens [ pos ] -= 1
if _list_lens [ pos ]:
_mins [ pos ] = _lists [ pos ][ 0 ]
else :
del _lists [ pos ]
del _list_lens [ pos ]
del _mins [ pos ]
self . _rebuild = True
def _loc_left ( self , value ):
"""Return an index pair that corresponds to the first position of `value` in the sorted list."""
if not self . _len :
return 0 , 0
_lists = self . _lists
_mins = self . _mins
lo , pos = - 1 , len ( _lists ) - 1
while lo + 1 < pos :
mi = ( lo + pos ) >> 1
if value <= _mins [ mi ]:
pos = mi
else :
lo = mi
if pos and value <= _lists [ pos - 1 ][ - 1 ]:
pos -= 1
_list = _lists [ pos ]
lo , idx = - 1 , len ( _list )
while lo + 1 < idx :
mi = ( lo + idx ) >> 1
if value <= _list [ mi ]:
idx = mi
else :
lo = mi
return pos , idx
def _loc_right ( self , value ):
"""Return an index pair that corresponds to the last position of `value` in the sorted list."""
if not self . _len :
return 0 , 0
_lists = self . _lists
_mins = self . _mins
pos , hi = 0 , len ( _lists )
while pos + 1 < hi :
mi = ( pos + hi ) >> 1
if value < _mins [ mi ]:
hi = mi
else :
pos = mi
_list = _lists [ pos ]
lo , idx = - 1 , len ( _list )
while lo + 1 < idx :
mi = ( lo + idx ) >> 1
if value < _list [ mi ]:
idx = mi
else :
lo = mi
return pos , idx
def add ( self , value ):
"""Add `value` to sorted list."""
_load = self . _load
_lists = self . _lists
_mins = self . _mins
_list_lens = self . _list_lens
self . _len += 1
if _lists :
pos , idx = self . _loc_right ( value )
self . _fen_update ( pos , 1 )
_list = _lists [ pos ]
_list . insert ( idx , value )
_list_lens [ pos ] += 1
_mins [ pos ] = _list [ 0 ]
if _load + _load < len ( _list ):
_lists . insert ( pos + 1 , _list [ _load :])
_list_lens . insert ( pos + 1 , len ( _list ) - _load )
_mins . insert ( pos + 1 , _list [ _load ])
_list_lens [ pos ] = _load
del _list [ _load :]
self . _rebuild = True
else :
_lists . append ([ value ])
_mins . append ( value )
_list_lens . append ( 1 )
self . _rebuild = True
def discard ( self , value ):
"""Remove `value` from sorted list if it is a member."""
_lists = self . _lists
if _lists :
pos , idx = self . _loc_right ( value )
if idx and _lists [ pos ][ idx - 1 ] == value :
self . _delete ( pos , idx - 1 )
def remove ( self , value ):
"""Remove `value` from sorted list; `value` must be a member."""
_len = self . _len
self . discard ( value )
if _len == self . _len :
raise ValueError ( ' {0!r} not in list' . format ( value ))
def pop ( self , index =- 1 ):
"""Remove and return value at `index` in sorted list."""
pos , idx = self . _fen_findkth ( self . _len + index if index < 0 else index )
value = self . _lists [ pos ][ idx ]
self . _delete ( pos , idx )
return value
def bisect_left ( self , value ):
"""Return the first index to insert `value` in the sorted list."""
pos , idx = self . _loc_left ( value )
return self . _fen_query ( pos ) + idx
def bisect_right ( self , value ):
"""Return the last index to insert `value` in the sorted list."""
pos , idx = self . _loc_right ( value )
return self . _fen_query ( pos ) + idx
def count ( self , value ):
"""Return number of occurrences of `value` in the sorted list."""
return self . bisect_right ( value ) - self . bisect_left ( value )
def __len__ ( self ):
"""Return the size of the sorted list."""
return self . _len
def __getitem__ ( self , index ):
"""Lookup value at `index` in sorted list."""
pos , idx = self . _fen_findkth ( self . _len + index if index < 0 else index )
return self . _lists [ pos ][ idx ]
def __delitem__ ( self , index ):
"""Remove value at `index` from sorted list."""
pos , idx = self . _fen_findkth ( self . _len + index if index < 0 else index )
self . _delete ( pos , idx )
def __contains__ ( self , value ):
"""Return true if `value` is an element of the sorted list."""
_lists = self . _lists
if _lists :
pos , idx = self . _loc_left ( value )
return idx < len ( _lists [ pos ]) and _lists [ pos ][ idx ] == value
return False
def __iter__ ( self ):
"""Return an iterator over the sorted list."""
return ( value for _list in self . _lists for value in _list )
def __reversed__ ( self ):
"""Return a reverse iterator over the sorted list."""
return ( value for _list in reversed ( self . _lists ) for value in reversed ( _list ))
def __repr__ ( self ):
"""Return string representation of sorted list."""
return 'SortedList( {0} )' . format ( list ( self ))
字符串
KMP
暴力匹配所有起始位置
时间复杂度:O ( m n ) O(mn) O ( mn )
for i in range ( len_s - len_p + 1 ):
ii , j = i , 0
while j < len_p :
if s [ ii ] == p [ j ]: ii , j = ii + 1 , j + 1
else : break
if j == len_p : res . append ( i )
前缀函数 / next 数组
时间复杂度:O ( n ) O(n) O ( n )
对于一个长度为 n n n n n n π \pi π π ( i ) \pi(i) π ( i ) s [ 0 ] ∼ s [ i ] s[0] \sim s[i] s [ 0 ] ∼ s [ i ] π [ 0 ] = 0 \pi[0]=0 π [ 0 ] = 0
例如:'aabaaab' 的 π \pi π
求解前缀函数:
相邻的前缀函数值,至多 + 1。π ( i − 1 ) \pi(i-1) π ( i − 1 ) s [ i ] = s [ π ( i − 1 ) ] s[i]=s[\pi(i-1)] s [ i ] = s [ π ( i − 1 )] π ( i ) = π ( i − 1 ) + 1 \pi(i) = \pi(i-1)+1 π ( i ) = π ( i − 1 ) + 1
考虑 s [ i ] ≠ s [ π ( i − 1 ) ] s[i] \ne s[\pi(i-1)] s [ i ] = s [ π ( i − 1 )] s [ 0 ] ∼ s [ i − 1 ] s[0] \sim s[i-1] s [ 0 ] ∼ s [ i − 1 ] π [ i − 1 ] \pi[i-1] π [ i − 1 ] j j j i − 1 i-1 i − 1 s [ 0 ] ∼ s [ j − 1 ] = s [ i − j ] ∼ s [ i − 1 ] s[0] \sim s[j-1] = s[i-j] \sim s[i-1] s [ 0 ] ∼ s [ j − 1 ] = s [ i − j ] ∼ s [ i − 1 ]
实际上,第二长真后缀也完整存在于 当前真前缀 s [ 0 ] ∼ s [ j − 1 ] s[0] \sim s[j-1] s [ 0 ] ∼ s [ j − 1 ] j ( n − 1 ) = π ( j n − 1 ) j^{(n-1)}=\pi(j^n-1) j ( n − 1 ) = π ( j n − 1 ) s [ i ] = s [ j ′ ] s[i]=s[j'] s [ i ] = s [ j ′ ] j ′ = 0 j'=0 j ′ = 0 s [ i ] s[i] s [ i ] s [ j ′ ] s[j'] s [ j ′ ] j ′ + 1 j'+1 j ′ + 1 s [ i ] = s [ j ′ ] s[i]=s[j'] s [ i ] = s [ j ′ ]
def get_pi ( s ):
n = len ( s )
pi = [ 0 ] * n
for i in range ( 1 , n ):
j = pi [ i - 1 ]
while j > 0 and s [ i ] != s [ j ]:
j = pi [ j - 1 ]
if s [ i ] == s [ j ]: j += 1
pi [ i ] = j
return pi
KMP 算法:找出 p p p s s s
时间复杂度:O ( n + m ) O(n+m) O ( n + m ) m = l e n ( p ) , n = l e n ( s ) m=len(p),~n=len(s) m = l e n ( p ) , n = l e n ( s )
构造字符串 t = p # s t=p\#s t = p # s π \pi π π [ m + 1 ] ∼ π [ n + m ] \pi[m+1]\sim \pi[n+m] π [ m + 1 ] ∼ π [ n + m ] π ( i ) = m \pi(i)=m π ( i ) = m p p p i i i t t t s s s i − m + 1 − m − 1 = i − 2 ∗ m i-m+1-m-1 = i - 2 * m i − m + 1 − m − 1 = i − 2 ∗ m
def kmp ( p , s ):
res = []
m , n = len ( p ), len ( s )
pi = get_pi ( p + '#' + s )
for i in range ( m + 1 , len ( pi )):
if pi [ i ] == m : res . append ( i - 2 * m )
return res
字符串排序
sorted ( str ) #返回按照字典序排序后的列表,如 "eda"-> ['a','d','e']
s_sorted = '' . join ( sorted ( str )) #把字符串列表组合成一个完整的字符串
Z 函数 (扩展 KMP)
对于字符串 s,函数 z [ i ] z[i] z [ i ] s s s s [ i : ] s[i:] s [ i : ] ( L C P ) (LCP) ( L CP ) z [ 0 ] = 0 z[0] = 0 z [ 0 ] = 0
z [ i ] = l e n ( L C P ( s , s [ i : ] ) )
z [i] = len(LCP(s, s [i:]))
z [ i ] = l e n ( L CP ( s , s [ i : ]))
例如, z ( a b a c a b a ) = [ 0 , 0 , 1 , 0 , 3 , 0 , 1 ] z(abacaba) = [0, 0, 1, 0, 3, 0, 1] z ( aba c aba ) = [ 0 , 0 , 1 , 0 , 3 , 0 , 1 ]
可视化:Z Algorithm (JavaScript Demo) (utdallas.edu)
# s = 'aabcaabxaaaz'
n = len ( s )
z = [ 0 ] * n
l = r = 0
for i in range ( 1 , n ):
if i <= r : # 在 Z-box 范围内
z [ i ] = min ( z [ i - l ], r - i + 1 )
while i + z [ i ] < n and s [ z [ i ]] == s [ i + z [ i ]]:
l , r = i , i + z [ i ]
z [ i ] += 1
# print(z) # [0, 1, 0, 0, 3, 1, 0, 0, 2, 2, 1, 0]
判断子序列
判断 p 在删除 ss 中下标元素后,是否仍然满足 s 是 p 的子序列。
ss = set ( removable [: x ])
i = j = 0
n , m = len ( s ), len ( p )
while i < n and j < m :
if i not in ss and s [ i ] == p [ j ]:
j += 1
i += 1
return j == m
字符串哈希
49. 字母异位词分组 - 力扣(LeetCode)
2430. 对字母串可执行的最大删除数 - 力扣(LeetCode)
字符串 API
s1.startswith(s2, beg = 0, end = len(s2))
用于检查字符串 s1 是否以字符串 s2 开头。是则返回 True。如果指定 beg 和 end,则在 s1 [beg: end] 范围内查找。
使用 ascii_lowercase 遍历 26 个字母。
from string import ascii_lowercase
cnt = { ch : 0 for ch in ascii_lowercase }
区间问题
区间选点问题 / 最大不相交区间数量
射气球问题 :给定 n n n
区间选点问题 :给定 n n n
最大不相交区间问题 :给定 n n n
这几个问题是等价的,最大不相交区间问题中,将区间集合 U U U S S S U − S U-S U − S U − S U-S U − S S S S ∣ S ∣ |S| ∣ S ∣
对于 m x r mxr m x r l , r l, r l , r
综上,只需要在 l > m x r l > mxr l > m x r r e s , m x r res, mxr res , m x r r < m x r r < mxr r < m x r m x r mxr m x r
复杂度:O ( n ) O(n) O ( n )
452. 用最少数量的箭引爆气球 - 力扣(LeetCode)
905. 区间选点 - AcWing 题库
908. 最大不相交区间数量 - AcWing 题库
def solve ( nums ):
nums . sort ()
mxr = - inf
res = 0
for l , r in nums :
if l > mxr :
res , mxr = res + 1 , r
elif r < mxr :
mxr = r
# 或者 mxr = min(mxr, r)
return res
区间分组
给定 n n n
维护所有分组的 m x r mxr m x r m x r min mxr_{\min} m x r m i n l l l
l > m x r min l > mxr_{\min} l > m x r m i n l ≤ m x r min l \le mxr_{\min} l ≤ m x r m i n r r r
时间复杂度:O ( n log n ) O(n \log n) O ( n log n )
906. 区间分组 - AcWing 题库
def solve ( nums ):
nums . sort ()
hq = []
for l , r in nums :
if hq and l > hq [ 0 ]:
heappop ( hq )
heappush ( hq , r )
return len ( hq )
区间覆盖
给定 n n n [ L , R ] [L, R] [ L , R ] [ L , R ] [L,R] [ L , R ]
907. 区间覆盖 - AcWing 题库
考察当前已经覆盖到的最远端 m x r mxr m x r l ≤ m x r l \le mxr l ≤ m x r l > m x r l > mxr l > m x r [ m x r + 1 , ] [mxr+1,] [ m x r + 1 , ] n m x r nmxr nm x r m x r mxr m x r R R R
def solve ( L , R , nums ):
n = len ( nums )
nums . sort ()
mxr = L
i = res = 0
while i < n :
l , r = nums [ i ]
if l > mxr : return - 1
nmxr = r
while i + 1 < n and nums [ i + 1 ][ 0 ] <= mxr :
nmxr = max ( nmxr , nums [ i + 1 ][ 1 ])
i += 1
res += 1
mxr = nmxr
if mxr >= R : return res
i += 1
return - 1
合并区间
先排序。
class Solution :
def merge ( self , intervals : List [ List [ int ]]) -> List [ List [ int ]]:
intervals . sort ()
res = []
l , r = intervals [ 0 ][ 0 ], intervals [ 0 ][ 1 ]
for interval in intervals :
il , ir = interval [ 0 ], interval [ 1 ]
if il > r :
res . append ([ l , r ])
l = il
r = max ( r , ir )
res . append ([ l , r ])
return res
2580. 统计将重叠区间合并成组的方案数 - 力扣(LeetCode)
def countWays ( self , ranges : List [ List [ int ]]) -> int :
ranges . sort ( key = lambda x : x [ 0 ])
l , r = ranges [ 0 ][ 0 ], ranges [ 0 ][ 1 ]
nranges = []
for il , ir in ranges :
if il > r :
nranges . append ([ l , r ])
l = il
r = max ( ir , r )
区间交集
Problem - C - Codeforces
L o , H i Lo,Hi L o , H i [ L o − d t , H i + d t ] [Lo-dt,~Hi+dt] [ L o − d t , H i + d t ] [ l o , h i ] [lo, hi] [ l o , hi ]
def solve ():
n , m = map ( int , input () . split ())
tem = [( 0 , m , m )]
for _ in range ( n ):
at , lo , hi = map ( int , input () . split ())
tem . append (( at , lo , hi ))
Lo = Hi = m
for i in range ( 1 , n + 1 ):
at , lo , hi = tem [ i ]
dt = at - tem [ i - 1 ][ 0 ]
Lo , Hi = Lo - dt , Hi + dt
if Lo > hi or Hi < lo : return 'NO'
Lo , Hi = max ( Lo , lo ), min ( Hi , hi )
return 'YES'
回溯 / 递归 / 分治
子集型回溯
枚举子集,O ( n ⋅ 2 n ) O(n\cdot2^n) O ( n ⋅ 2 n )
78. 子集 - 力扣(LeetCode)
回溯方法 1:选 / 不选
def subsets ( self , nums : List [ int ]) -> List [ List [ int ]]:
n = len ( nums )
res , path = [], []
def dfs ( i ):
if i == n :
res . append ( path . copy ())
return
path . append ( nums [ i ])
dfs ( i + 1 )
path . pop ()
dfs ( i + 1 )
dfs ( 0 )
return res
方回溯法 2:枚举选哪个数 + 记录可以选的范围
d f s ( i ) dfs(i) df s ( i ) p a t h path p a t h p a t h path p a t h i i i d f s dfs df s
def subsets ( self , nums : List [ int ]) -> List [ List [ int ]]:
res , path = [], []
n = len ( nums )
def dfs ( i ):
res . append ( path . copy ())
for j in range ( i , n ):
path . append ( nums [ j ])
dfs ( j + 1 )
path . pop ()
dfs ( 0 )
return res
位运算写法:
def subsets ( self , nums : List [ int ]) -> List [ List [ int ]]:
n = len ( nums )
s = ( 1 << n ) - 1
res = [[]]
sub = s
while sub :
res . append ([ nums [ j ] for j in range ( n ) if (( sub >> j ) & 1 )])
sub = ( sub - 1 ) & s
return res
组合型回溯
枚举所有长度为 k k k
77. 组合 - 力扣(LeetCode)
回溯方法 1:选 / 不选方法
时间复杂度 :O ( n ⋅ 2 n ) O(n \cdot2^n) O ( n ⋅ 2 n )
def combine ( self , n : int , k : int ) -> List [ List [ int ]]:
nums = list ( range ( 1 , n + 1 ))
res , path = [], []
def dfs ( i ):
if i == n :
if len ( path ) == k : res . append ( path . copy ())
return
# 不选
dfs ( i + 1 )
# 选
path . append ( nums [ i ])
dfs ( i + 1 )
path . pop ()
dfs ( 0 )
return res
回溯方法 2:枚举当前选哪个数,以及记录可以选择的范围,每一个状态的合法情况需要记录。
剪枝操作 (1):确保所有子集长度不会超过 k k k k k k k k k
倒序枚举时, d f s ( i ) dfs(i) df s ( i ) n u m s [ 0 ] ∼ n u m s [ i ] nums[0] \sim nums[i] n u m s [ 0 ] ∼ n u m s [ i ] i + 1 i+1 i + 1 j − 1 j-1 j − 1 j j j j ≥ k − l e n ( p a t h ) − 1 j \ge k - len(path)-1 j ≥ k − l e n ( p a t h ) − 1
时间复杂度:O ( k ⋅ C ( n , k ) ) O(k \cdot C(n,k)) O ( k ⋅ C ( n , k )) C ( n , k ) C(n,k) C ( n , k ) k k k
# 倒叙枚举
def combine ( self , n : int , k : int ) -> List [ List [ int ]]:
nums = list ( range ( 1 , n + 1 ))
res , path = [], []
def dfs ( i ):
if k == len ( path ):
res . append ( path . copy ())
return
for j in range ( i , k - len ( path ) - 2 , - 1 ):
path . append ( nums [ j ])
dfs ( j - 1 )
path . pop ()
dfs ( n - 1 )
return res
位运算写法 + Gosper's Hack:
时间复杂度:O ( n ⋅ C ( n , k ) ) O(n \cdot C(n,k)) O ( n ⋅ C ( n , k ))
def combine ( self , n : int , k : int ) -> List [ List [ int ]]:
nums = list ( range ( 1 , n + 1 ))
s = ( 1 << n ) - 1
sub = ( 1 << k ) - 1
res = []
def next_sub ( x ):
lb = x & - x
left = x + lb
right = (( left ^ x ) >> 2 ) // lb
return left | right
while sub <= s :
res . append ([ nums [ i ] for i in range ( n ) if ( sub >> i ) & 1 ])
sub = next_sub ( sub )
return res
完全背包型组合
每个元素可以无限重复选择,需要找出目标值等于 t a r g e t target t a r g e t t a r g e t target t a r g e t
先排序,利于提前剪枝优化跳出循环。枚举当前选哪个 + 记录可以选择的范围型回溯,记录当前的和。由于可以重复选择,所以当前选择 j j j j j j
39. 组合总和 - 力扣(LeetCode)
def combinationSum ( self , candidates : List [ int ], target : int ) -> List [ List [ int ]]:
candidates . sort ()
n , res , path = len ( candidates ), [], []
# 枚举当前选哪个,以及记录可以选择的范围;以及当前的和
def dfs ( i , s ):
if s == target :
res . append ( path . copy ())
return
for j in range ( i , n ):
x = candidates [ j ]
if x + s <= target :
path . append ( x )
dfs ( j , s + x ) # 体现可重复选择
path . pop ()
else : break
dfs ( 0 , 0 )
return res
括号生成问题:带限制组合型回溯
22. 括号生成 - 力扣(LeetCode)
选 / 不选型回溯:枚举当前左 / 右括号,记录当前左括号的个数。记 l c lc l c r c rc rc
限制 1:l c lc l c r c rc rc
限制 2:l c lc l c n / 2 n/2 n /2
限制 3:当 l c = r c lc=rc l c = rc
class Solution :
def generateParenthesis ( self , n : int ) -> List [ str ]:
# 枚举当前左 / 右括号,记录当前左括号的个数
n <<= 1
path = [ None ] * n
res = []
def dfs ( i , lc ):
rc = i - lc
if rc > lc or lc > n // 2 : return
if i == n :
res . append ( '' . join ( path ))
return
path [ i ] = '('
dfs ( i + 1 , lc + 1 )
if rc < lc : # 可以选右
path [ i ] = ')'
dfs ( i + 1 , lc )
dfs ( 0 , 0 )
return res
时间复杂度:由于状态个数是卡特兰数列,即 O ( C n ) ∼ O ( 4 n n 3 2 ⋅ π ) O(C_n) \sim O(\frac{4^n}{n^{\frac{3}{2}} \cdot\sqrt \pi}) O ( C n ) ∼ O ( n 2 3 ⋅ π 4 n )
排列型回溯
全排列:排列元素无重复
46. 全排列 - 力扣(LeetCode)
写法 1:d f s ( i , S ) dfs(i, S) df s ( i , S ) i i i S S S p a t h path p a t h
其中 p a t h path p a t h p a t h [ i ] = j path[i] = j p a t h [ i ] = j a p p e n d / p o p append / pop a pp e n d / p o p
时间复杂度:当有 N N N M = A N N + A N N − 1 + ⋯ + A N 0 = ∑ k = 0 N N ! k ! = N ! ⋅ ∑ k = 0 N 1 k ! = e ⋅ N ! M = A_N^N+A_N^{N-1}+~\cdots~+A_N^0=\sum_{k=0}^{N}\frac{N!}{k!} =N! \cdot \sum_{k=0}^{N}\frac{1}{k!}= e\cdot N! M = A N N + A N N − 1 + ⋯ + A N 0 = ∑ k = 0 N k ! N ! = N ! ⋅ ∑ k = 0 N k ! 1 = e ⋅ N ! O ( n ) O(n) O ( n ) O ( N ⋅ N ! ) O(N \cdot N!) O ( N ⋅ N !)
def permute ( self , nums : List [ int ]) -> List [ List [ int ]]:
n = len ( nums )
path = [ 0 ] * n
res = []
# 当前枚举到 位置 i,没有枚举过的集合为 S
def dfs ( i , S ):
if i == n :
res . append ( path . copy ())
return
for j in S :
path [ i ] = j
dfs ( i + 1 , S - { j })
dfs ( 0 , set ( nums ))
return res
写法 2:更偏向于回溯。外层 p a t h path p a t h o n _ p a t h on\_path o n _ p a t h
def permute ( self , nums : List [ int ]) -> List [ List [ int ]]:
n = len ( nums )
path = []
on_path = [ False ] * n
res = []
# 当前枚举到 位置 i,on_path 记录是否已经出现在回溯路径 path 中
def dfs ( i ):
if i == n :
res . append ( path . copy ())
return
for pj , on in enumerate ( on_path ):
if not on :
on_path [ pj ] = True
path . append ( nums [ pj ])
dfs ( i + 1 )
on_path [ pj ] = False
path . pop ()
dfs ( 0 )
return res
全排列:排列元素有重复:只能用 o n _ p a t h on\_path o n _ p a t h
47. 全排列 II - 力扣(LeetCode)
相同元素,在 i i i
def permuteUnique ( self , nums : List [ int ]) -> List [ List [ int ]]:
n , res = len ( nums ), []
path , on_path = [ 0 ] * n , [ 0 ] * n
def dfs ( i ):
if i == n :
res . append ( path . copy ())
return
S = set () # 相同元素,在 i 处视为一个
for j , on in enumerate ( on_path ):
if not on and nums [ j ] not in S :
S . add ( nums [ j ])
path [ i ] = nums [ j ]
on_path [ j ] = 1
dfs ( i + 1 )
on_path [ j ] = 0
dfs ( 0 )
return res
996. 正方形数组的数目 - 力扣(LeetCode)
相同值的排列视为同一个:在枚举 i i i
def numSquarefulPerms ( self , nums : List [ int ]) -> int :
n = len ( nums )
res = 0
def is_sqr ( x ):
return x == int ( sqrt ( x )) ** 2
def dfs ( i , S , pre ):
nonlocal res
if i == n :
res += 1
return
# i 位置放谁
s = set ()
for j in range ( n ):
x = nums [ j ]
if ( S >> j ) & 1 == 1 or x in s : continue
s . add ( x )
if pre == None or is_sqr ( pre + x ):
dfs ( i + 1 , S | ( 1 << j ), x )
dfs ( 0 , 0 , None )
return res
2850. 将石头分散到网格图的最少移动次数 - 力扣(LeetCode)
暴力枚举可重复全排列匹配 + 位运算压缩。用石头个数大于 1 和 没有石头的位置,构造两个列表,进行全排列暴力匹配。
def minimumMoves ( self , grid : List [ List [ int ]]) -> int :
frm , to = [], []
for i , row in enumerate ( grid ):
for j , x in enumerate ( grid [ i ]):
if x == 0 : to . append (( i , j ))
elif x > 1 : frm . extend (( i , j ) for _ in range ( x - 1 ))
res = inf
n = len ( frm )
path = [ None ] * n
def dfs ( i , S ):
nonlocal res
if i == n :
cst = sum ( abs ( x1 - x2 ) + abs ( y1 - y2 ) for ( x1 , y1 ), ( x2 , y2 ) in zip ( path , to ))
res = min ( res , cst )
return
for j in range ( n ):
if ( S >> j ) & 1 :
path [ i ] = frm [ j ]
dfs ( i + 1 , S ^ ( 1 << j ))
dfs ( 0 , ( 1 << n ) - 1 )
return res
N 皇后问题
皇后之间不同行,不同列,且不能在同一斜线。如果只满足不同行不同列,等价于每行每列恰好一个皇后。如果用 c o l col co l c o l [ i ] col[i] co l [ i ] i i i c o l [ i ] col[i] co l [ i ] c o l col co l
加上斜线上不能有皇后的条件,如果从上往下枚举,则左上方向、右上方向不能有皇后。所以问题变成,当前枚举到 第 i i i S S S j ∈ S j \in S j ∈ S ∀ r ∈ [ 0 , i − 1 ] \forall r \in [0 ,~ i-1] ∀ r ∈ [ 0 , i − 1 ] c = c o l [ r ] c = col[r] c = co l [ r ] i + j = r + c i+j=r+c i + j = r + c i − j = r − c i-j=r-c i − j = r − c
写法 1:d f s ( i , S ) dfs(i, S) df s ( i , S ) i i i i i i S S S
def solveNQueens ( self , n : int ) -> List [ List [ str ]]:
res = []
path = [ 0 ] * n
# 当前枚举到第 i 行,可以继续枚举的列号集合是 S
def valid ( i , j ):
for r in range ( i ):
c = path [ r ]
if r + c == i + j or r - c == i - j :
return False
return True
def dfs ( i , S ):
if i == n :
res . append ([ '.' * j + 'Q' + ( n - j - 1 ) * '.' for j in path ])
return
for j in S :
if valid ( i , j ):
path [ i ] = j
dfs ( i + 1 , S - { j })
dfs ( 0 , set ( range ( n )))
return res
写法 2:回溯全排列 + 位运算 + 集合优化 O ( 1 ) O(1) O ( 1 )
由于判断 i + j i+j i + j i − j i - j i − j O ( n ) O(n) O ( n ) i + j i+j i + j i − j i - j i − j i + j i+j i + j i − j i-j i − j l u lu l u r u ru r u i − j i-j i − j i − j + 10 i-j+10 i − j + 10
def solveNQueens ( self , n : int ) -> List [ List [ str ]]:
res = []
path = [ 0 ] * n
lu = ru = 0
# 当前枚举到第 i 行,可以继续枚举的列号集合是 S
def dfs ( i , S ):
nonlocal lu , ru
if i == n :
res . append ([ '.' * j + 'Q' + ( n - j - 1 ) * '.' for j in path ])
return
for j in range ( n ):
if ( S >> j ) & 1 and ( lu >> ( i + j )) & 1 == 0 and ( ru >> ( i - j + 10 )) & 1 == 0 :
path [ i ] = j
lu , ru = lu | ( 1 << ( i + j )), ru | ( 1 << ( i - j + 10 ))
dfs ( i + 1 , S & ~ ( 1 << j ))
lu , ru = lu ^ ( 1 << ( i + j )), ru ^ ( 1 << ( i - j + 10 ))
dfs ( 0 , ( 1 << n ) - 1 )
return res
回溯分割字符串
记录当前切割到的位置,枚举下一个切割位置,判断切割合法性。
LCR 086. 分割回文串 - 力扣(LeetCode)
def partition ( self , s : str ) -> List [ List [ str ]]:
n , path , res = len ( s ), [], []
# 当前分割的位置,枚举下次分割位置
def dfs ( i ):
if i == n :
res . append ( path . copy ())
return
for j in range ( i + 1 , n + 1 ):
t = s [ i : j ]
if t == t [:: - 1 ]:
path . append ( t )
dfs ( j )
path . pop ()
dfs ( 0 )
return res
93. 复原 IP 地址 - 力扣(LeetCode)
增加了字符串段数限制:恰好等于 4。时间复杂度:O ( n × C ( n , 3 ) ) O(n \times C(n,3)) O ( n × C ( n , 3 ))
def restoreIpAddresses ( self , s : str ) -> List [ str ]:
n , path , res = len ( s ), [], []
# 记录当前分割位置,枚举下一个分割位置
def dfs ( i ):
if len ( path ) == 4 :
if i == n :
res . append ( '.' . join ( path ))
return
for j in range ( i + 1 , n + 1 ):
t = s [ i : j ]
if t == '0' or '0' not in t [ 0 ] and int ( t ) <= 255 :
path . append ( t )
dfs ( j )
path . pop ()
dfs ( 0 )
return res
2698. 求一个整数的惩罚数 - 力扣(LeetCode)
判断一个数,其平方是否可能划分成若干字符串,其各段对应数字之和等于本身。例如 36 × 36 = 1296 , 1 + 29 + 6 = 36 36\times36=1296,1+29+6=36 36 × 36 = 1296 , 1 + 29 + 6 = 36
def check ( x ):
sx = str ( x * x )
n = len ( sx )
def dfs ( i , s ):
if i == n : return s == x
t = 0
for j in range ( i + 1 , n + 1 ):
t = t * 10 + int ( sx [ j - 1 ])
if t + s <= x and dfs ( j , s + t ):
return True
return False
return dfs ( 0 , 0 )
分治
395. 至少有 K 个重复字符的最长子串 - 力扣(LeetCode)
f ( s ) f(s) f ( s ) k k k s s s k k k s s s
时间复杂度:O ( 26 N ) O(26N) O ( 26 N ) O ( N ) O(N) O ( N ) O ( 26 N ) O(26N) O ( 26 N )
def longestSubstring ( self , s1 : str , k : int ) -> int :
# s1 中所有字符数量 >= k 个最长子串
def f ( s1 ):
cnt = Counter ( s1 )
for ch , c in cnt . items ():
if c < k :
return max ( f ( sub ) for sub in s1 . split ( ch ))
return len ( s1 )
return f ( s1 )
1763. 最长的美好子字符串 - 力扣(LeetCode)
f ( s ) f(s) f ( s ) s s s s 1 s1 s 1 O ( 26 × n ) O(26 \times n) O ( 26 × n ) O ( n ) O(n) O ( n )
from collections import *
from string import ascii_lowercase , ascii_uppercase
L , U = ascii_lowercase , ascii_uppercase
def f ( s1 ):
s = set ( s1 )
for l , u in zip ( L , U ):
if ( l in s ) != ( u in s ):
ss = s1 . split ( l if l in s else u )
res = ''
for sub in ss :
cur = f ( sub )
if len ( cur ) > len ( res ): res = cur
return res
return s1
class Solution :
def longestNiceSubstring ( self , s : str ) -> str :
return f ( s )
搜索 / DFS / BFS
枚举 DFS
5.最大数字 - 蓝桥云课 (lanqiao.cn)
思路
贪心,从左到右,尽可能构造 9。
对每一位数字,只会用一种操作。
记 d f s ( i , n , a , b ) dfs(i, n, a, b) df s ( i , n , a , b ) i i i a a a b b b n n n
对于操作 1,考虑 d = m i n ( 9 − x , a ) d=min(9-x,a) d = min ( 9 − x , a )
则 n ← n × 10 + ( x + d ) n ← n \times 10 + (x + d) n ← n × 10 + ( x + d ) a ← a − d a ← a - d a ← a − d
对于操作 2,考虑 b b b x + 1 x + 1 x + 1 b ← b − ( x + 1 ) b ← b - (x + 1) b ← b − ( x + 1 )
import sys
input = lambda : sys . stdin . readline () . strip ()
N , A , B = map ( int , input () . split ())
sN = str ( N )
res = 0
def dfs ( i , n , a , b ):
global res
if i >= len ( sN ):
res = max ( res , n )
return
x = int ( sN [ i ])
d = min ( 9 - x , a )
dfs ( i + 1 , n * 10 + ( x + d ), a - d , b )
if b >= x + 1 :
dfs ( i + 1 , n * 10 + 9 , a , b - ( x + 1 ))
dfs ( 0 , 0 , A , B )
print ( res )
图上 DFS
1.小朋友崇拜圈 - 蓝桥云课 (lanqiao.cn)
语言整理
一个有向图,每个节点 u u u u → v u→v u → v g g g g [ u ] = v g[u]=v g [ u ] = v
求图中最长环的长度。
思路
d f s ( u ) dfs(u) df s ( u ) u u u s s s 如果 u u u s s s
如果 u u u s s s d f s ( g [ u ] ) dfs(g[u]) df s ( g [ u ])
遍历所有节点,确保考虑到所有连通分量。
类似代码:
s = set
def dfs ( u ):
if u in s : return # 找到了环
s . add ( u )
dfs ( g [ u ])
for u in range ( 1 , n + 1 ):
dfs ( u )
思路
时间戳思想,额外记录每次访问节点 u u u i d x idx i d x d d d u : i d x u:idx u : i d x
如果 u u u d d d u u u i d x − d [ u ] idx - d[u] i d x − d [ u ]
如果 u u u d d d d f s ( g [ u ] , i d x + 1 ) dfs(g[u], idx + 1) df s ( g [ u ] , i d x + 1 )
遍历所有节点,确保考虑所有连通分量
在外层用 r e s res res
正解代码:
import sys
input = lambda : sys . stdin . readline () . strip ()
sys . setrecursionlimit ( 10000 ) # 增加递归深度至少大于 n,因为 python 默认为 1000
n = int ( input ())
g = [ 0 ] + list ( map ( int , input () . split ()))
res = 0
d = {}
def dfs ( u , idx ):
global res
if d . get ( u ) is not None :
res = max ( res , idx - d [ u ]) # 找到闭环,序号差就是环长
return
d [ u ] = idx
dfs ( g [ u ], idx + 1 )
for u in range ( 1 , n + 1 ): # 确保访问所有连通分量
dfs ( u , 1 )
print ( res )
模拟 BFS
网格图模拟 BFS
是给定一个二维网格,以及一些初始位置,并说明初始位置的蔓延条件。
通过队列 q q q
每次考虑当前位置 ( x , y ) (x,y) ( x , y )
网格图 BFS 模板。
# 设置 q 的初始值,如 q.append(...)
q = deque ([( 3 , 4 )]) # 或者 q = deque() 之后,q.append((3, 4))
g [ 3 ][ 4 ] = 0 # 标记访问过
di = [( 0 , 1 ), ( 0 , - 1 ), ( 1 , 0 ), ( - 1 , 0 )]
while q :
x , y = q . popleft () # 弹出队首
for dx , dy in di : # 遍历四个方向,尝试蔓延
nx , ny = x + dx , y + dy
if 0 <= nx < n and 0 <= ny < m and g [ nx ][ ny ] == 1 : # 判断蔓延是否合法
q . append (( nx , ny )) # 加到队尾,表示后续开始蔓延的位置
g [ nx ][ ny ] = 0 # 标记访问过
# 其他操作
695. 岛屿的最大面积 - 力扣(LeetCode)
思路
枚举每个连通的岛屿,通过将访问过的位置设置为 0,即 g r i d [ i ] [ j ] = 0 grid[i][j] = 0 g r i d [ i ] [ j ] = 0
每个岛屿的“登陆点”即为 q q q
每次将 q q q
重复操作,直到 q q q
class Solution :
def maxAreaOfIsland ( self , g : List [ List [ int ]]) -> int :
n , m = len ( g ), len ( g [ 0 ])
q = deque ()
res = 0
di = [( 0 , 1 ), ( 0 , - 1 ), ( 1 , 0 ), ( - 1 , 0 )]
def bfs ( i , j ): # 考虑登陆点为 (i, j)的岛屿
ans = 1
q = deque ([( i , j )])
g [ i ][ j ] = 0 # 登陆点设置为 0,表示已经访问过
while q :
x , y = q . popleft () # 弹出队首
for dx , dy in di : # 遍历四个方向,考虑是否有陆地
nx , ny = x + dx , y + dy
if 0 <= nx < n and 0 <= ny < m and g [ nx ][ ny ]:
q . append (( nx , ny )) # 有陆地,加到队尾,表示后续需要考虑的位置
ans += 1
g [ nx ][ ny ] = 0 # 标记访问
return ans
for i , row in enumerate ( g ):
for j , x in enumerate ( row ):
if x == 1 : # 遍历所有连通分量
res = max ( res , bfs ( i , j ))
return res
1.长草 - 蓝桥云课 (lanqiao.cn)
import sys
from collections import deque
input = lambda : sys . stdin . readline () . strip ()
n , m = map ( int , input () . split ())
g = [[ 0 ] * m for _ in range ( n )]
di = [( 0 , 1 ), ( 0 , - 1 ), ( 1 , 0 ), ( - 1 , 0 )]
q = deque ()
for i in range ( n ):
r = input ()
for j , x in enumerate ( r ):
if x == 'g' :
g [ i ][ j ] = 1
q . append (( i , j ))
k = int ( input ())
while q and k :
for _ in range ( len ( q )):
x , y = q . popleft ()
for dx , dy in di :
nx , ny = x + dx , y + dy
if 0 <= nx < n and 0 <= ny < m and g [ nx ][ ny ] == 0 :
g [ nx ][ ny ] = 1
q . append (( nx , ny ))
k -= 1
for row in g :
print ( '' . join ( 'g' if x else '.' for x in row ))
排序
次最值问题
1289. 下降路径最小和 II - 力扣(LeetCode)
其中需要维护上一层的最小值、次小值及其对应的坐标。
mn = mn_2 = ( inf , - 1 )
if y < mn [ 0 ]: mn_2 , mn = mn , ( y , j )
elif y == mn [ 0 ]: mn_2 = ( y , j )
elif y < mn_2 [ 0 ]: mn_2 = ( y , j )
计数排序
带修求第 k k k
使用哈希表维护每个数值出现次数,适用于数值的值域较小的情况。
例如:当 n u m s [ i ] ∈ [ a , b ] nums[i] \in [a,~b] n u m s [ i ] ∈ [ a , b ] O ( b − a ) O(b-a) O ( b − a ) k k k
def get_min_k ( cnt , k ):
cur = 0
for x in range ( a , b ):
if cnt [ x ] == 0 : continue
cur += cnt [ x ]
if cur >= k : return x
return b
2653. 滑动子数组的美丽值 - 力扣(LeetCode)
定长滑动窗口 + 哈希维护计数 + 计数排序。时间复杂度:O ( n U ) , U O(nU),U O ( n U ) , U
def getSubarrayBeauty ( self , nums : List [ int ], k : int , x : int ) -> List [ int ]:
n = len ( nums )
cnt = Counter ( nums [: k ])
def get_min_k ():
cur = 0
for y in range ( - 50 , 0 ):
cur += cnt [ y ]
if cur >= x : return y
return 0
res = [ get_min_k ()]
for r in range ( k , n ):
nl , nr = nums [ r - k ], nums [ r ]
cnt [ nr ] += 1
cnt [ nl ] -= 1
if cnt [ nl ] == 0 : cnt . pop ( nl )
res . append ( get_min_k ())
return res
二分查找 / 二分答案
二分查找数学模型
无特殊说明,均为整数。
二分查找基本模型:给定一个单调不减的数组 a a a 大于 x x x
给定一个单调不减的数组 a a a 大于 x x x
给定一个单调不减的数组 a a a a [ i ] > x a[i] > x a [ i ] > x i i i
记为 b i s e c t ( a , x ) bisect(a, x) bi sec t ( a , x )
a = [1, 9, 9, 9, 200, 500]
b i s e c t ( a , 3 ) bisect(a, 3) bi sec t ( a , 3 )
b i s e c t ( a , 1 ) bisect(a, 1) bi sec t ( a , 1 )
b i s e c t ( a , − 99 ) bisect(a, -99) bi sec t ( a , − 99 )
b i s e c t ( a , 9 ) bisect(a, 9) bi sec t ( a , 9 )
b i s e c t ( a , 7000 ) bisect(a, 7000) bi sec t ( a , 7000 )
二分查找变形:给定一个单调不减的数组 a a a 大于等于 x x x
等价为返回恰好 大于 x − 1 x-1 x − 1
即 b i s e c t ( a , x − 1 ) bisect(a, x - 1) bi sec t ( a , x − 1 )
a = [1, 9, 9, 9, 200, 500]
恰好大于等于 9 的位置
b i s e c t ( a , 9 − 1 ) bisect(a, 9 -1) bi sec t ( a , 9 − 1 )
恰好大于等于 200 的位置
b i s e c t ( a , 200 − 1 ) bisect(a, 200 - 1) bi sec t ( a , 200 − 1 )
二分查找变形 1:给定一个单调不减的数组 a a a 小于等于 x x x
等价为返回恰好大于 x x x − 1 -1 − 1
即 b i s e c t ( a , x ) − 1 bisect(a, x) - 1 bi sec t ( a , x ) − 1
a = [1, 9, 9, 9, 200, 500]
恰好小于等于 9 的位置
b i s e c t ( a , 9 ) − 1 bisect(a, 9) - 1 bi sec t ( a , 9 ) − 1
恰好小于等于 500 的位置
b i s e c t ( a , 500 ) bisect(a, 500 ) bi sec t ( a , 500 )
二分查找变形 2:给定一个 单调不增 的数组 a a a 小于 x x x
处理方法:a ′ = [ − x for x in a ] a' = [-x \text{ for } x \text{ in }a] a ′ = [ − x for x in a ]
等价于 b i s e c t ( a ′ , − x ) bisect(a', -x) bi sec t ( a ′ , − x )
也可以用逆序做,更推荐用相反数做;
a = [ 500 , 200 , 9 , 9 , 9 , 1 ] a = [500, 200, 9, 9, 9, 1] a = [ 500 , 200 , 9 , 9 , 9 , 1 ]
a ′ = [ − 500 , − 200 , − 9 , − 9 , − 9 , − 1 ] a' = [-500, -200, -9, -9, -9, -1] a ′ = [ − 500 , − 200 , − 9 , − 9 , − 9 , − 1 ]
bisect 库二分
bisect(a, x, lo = 0, hi = len(nums))
给定一个单调不减的数组 a a a [ l o , h i ] [lo, hi] [ l o , hi ] x x x
时间复杂度 O ( log n ) O( \log n) O ( log n )
bisect.bisect 和 bisect.bisect_right 是完全相同且同时支持的函数,为了方便,我们不写 bisect_right;
同时为了防止混淆,我们也不提 bisect_left,大家需要灵活学习如果用一个 bisect 实现所有变形;
from bisect import *
# 示例数组
# 0 1 2 3 4 5
arr = [ 1 , 9 , 9 , 9 , 200 , 500 ]
# 查找插入位置
print ( bisect ( arr , 3 )) # 输出: 1 (第一个大于 3 的索引)
print ( bisect ( arr , 1 )) # 输出: 1 (第一个大于 1 的索引)
print ( bisect ( arr , - 99 )) # 输出: 0 (第一个大于 -99 的索引)
print ( bisect ( arr , 9 )) # 输出: 4 (第一个大于 9 的索引)
print ( bisect ( arr , 7000 )) # 输出: 6 (第一个大于 7000 的索引,此时等于数组长度)
arr = [ 1 , 9 , 9 , 9 , 200 , 500 ]
# 如果需要找第一个大于等于 x 的位置索引
# bisect(nums, x - 1) ?
print ( bisect ( arr , 9 - 1 )) # 输出: 1 (第一个大于等于 9 的索引)
print ( bisect ( arr , 200 - 1 )) # 输出: 4 (第一个大于等于 200 的索引)
# 逆序数组,找到第一个小于 x 的位置索引
# 0 1 2 3 4 5
arr = [ 500 , 200 , 9 , 9 , 9 , 1 ]
arr = [ - x for x in arr ]
print ( bisect ( arr , - 9 )) # 输出: 5 (第一个小于 9 的位置索引)
P2249 【深基 13.例 1】查找 - 洛谷 (luogu.com.cn)
题目描述
输入 n n n 10 9 10^9 1 0 9 a 1 , a 2 , … , a n a_1,a_2,\dots,a_{n} a 1 , a 2 , … , a n m m m q q q − 1 -1 − 1
输入格式
第一行 2 2 2 n n n m m m
第二行 n n n
第三行 m m m 1 1 1
输出格式
输出一行,m m m
输入输出样例 #1
输入 #1
输出 #1
说明/提示
数据保证,1 ≤ n ≤ 10 6 1 \leq n \leq 10^6 1 ≤ n ≤ 1 0 6 0 ≤ a i , q ≤ 10 9 0 \leq a_i,q \leq 10^9 0 ≤ a i , q ≤ 1 0 9 1 ≤ m ≤ 10 5 1 \leq m \leq 10^5 1 ≤ m ≤ 1 0 5
本题输入输出量较大,请使用较快的 IO 方式。
from bisect import *
import sys
input = lambda : sys . stdin . readline () . strip ()
n , m = map ( int , input () . split ())
nums = list ( map ( int , input () . split ()))
Q = list ( map ( int , input () . split ()))
s = set ( nums ) # nums 构成的集合,如果待查询数组 q not in s,直接返回-1
for q in Q :
if q not in s : print ( - 1 , end = " " )
else : # q 一定出现在 nums 中, 利用技巧将“大于等于 x”转化成“大于 x-1”
print ( bisect ( nums , q - 1 ) + 1 , end = " " )
2563. 统计公平数对的数目 - 力扣(LeetCode) 同 Problem - 1538C - Codeforces
由于求符合条件的数对个数,与顺序无关,先排序
对 lower ≤ x + y ≤ upper \text{lower} \le x + y \le \text{upper} lower ≤ x + y ≤ upper lower − x ≤ y ≤ upper − x \text{lower} - x \le y \le \text{upper} - x lower − x ≤ y ≤ upper − x
即对一个 x x x [ i + 1 , n ) [i + 1, n) [ i + 1 , n ) [ lower − x , upper − x ] [\text{lower} - x, \text{upper} - x] [ lower − x , upper − x ]
即求 L = b i s e c t ( a , [ l o w e r ] − x − 1 ) L = bisect(a, \text[lower] - x - 1) L = bi sec t ( a , [ l o w er ] − x − 1 ) R = b i s e c t ( a , upper − x ) − 1 R = bisect(a, \text{upper} - x) - 1 R = bi sec t ( a , upper − x ) − 1
答案等于 R − L + 1 R-L + 1 R − L + 1
from bisect import *
class Solution :
def countFairPairs ( self , a : List [ int ], lower : int , upper : int ) -> int :
a . sort ()
res = 0
for i , x in enumerate ( a ):
L = bisect ( a , lower - x - 1 , i + 1 )
R = bisect ( a , upper - x , i + 1 ) - 1
res += R - L + 1
return res
朴素二分
内置 b i s e c t bisect bi sec t a [ i ] > x a[i] > x a [ i ] > x i i i
给定一个单调不减的数组 a a a a [ i ] a[i] a [ i ] c h e c k check c h ec k c h e c k ( a [ i ] ) > x check(a[i]) > x c h ec k ( a [ i ]) > x i i i
例如,c h e c k ( a [ i ] ) = ( a [ i ] ) 3 + 2 ⋅ a [ i ] + 1 check(a[i]) = {(a[i])} ^ 3 + 2 \cdot a[i] + 1 c h ec k ( a [ i ]) = ( a [ i ]) 3 + 2 ⋅ a [ i ] + 1 i i i c h e c k ( a [ i ] ) > x check(a[i]) > x c h ec k ( a [ i ]) > x
可以发现,前文提及的数学模型,对应的 c h e c k ( a [ i ] ) check(a[i]) c h ec k ( a [ i ]) a [ i ] a[i] a [ i ]
在 python3.8 版本不支持 bisect 传递比较规则,即无法传递 c h e c k check c h ec k
基本模型实现思路:
对于区间 [ l o , h i ] [lo, hi] [ l o , hi ] [ l o , l o + h i 2 ) [lo, \frac{lo + hi}{2}) [ l o , 2 l o + hi ) [ l o + h i 2 , h i ) [\frac{lo + hi}{2}, hi) [ 2 l o + hi , hi )
区间中点 i = l o + h i 2 i = \frac{lo + hi}{2} i = 2 l o + hi a [ i ] > x a[i] > x a [ i ] > x
是,区间更新为左半部,h i ← i hi ← i hi ← i
否,则由于 a [ i ] ≤ x a[i] \le x a [ i ] ≤ x i i i l o ← i + 1 lo ← i + 1 l o ← i + 1
当 l o = h i lo = hi l o = hi l o < h i lo < hi l o < hi
不会出现 l o > h i lo > hi l o > hi
# 【朴素二分】实现 bisect
def bisect ( a , x , lo = 0 , hi = None ):
if hi is None : hi = len ( a )
while lo < hi :
i = ( lo + hi ) >> 1
if a [ i ] > x :
hi = i
else :
lo = i + 1
return lo
# 示例用法
a = [ 1 , 9 , 9 , 9 , 200 , 500 ]
print ( bisect ( a , 9 )) # 输出: 4
print ( bisect ( a , 7000 )) # 输出: 6
c h e c k check c h ec k
对于区间 [ l o , h i ] [lo, hi] [ l o , hi ] [ l o , l o + h i 2 ) [lo, \frac{lo + hi}{2}) [ l o , 2 l o + hi ) [ l o + h i 2 , h i ) [\frac{lo + hi}{2}, hi) [ 2 l o + hi , hi )
区间中点 i = l o + h i 2 i = \frac{lo + hi}{2} i = 2 l o + hi c h e c k ( a [ i ] ) > x check(a[i]) > x c h ec k ( a [ i ]) > x
是,区间更新为左半部,h i ← i hi ← i hi ← i
否,则由于 a [ i ] ≤ x a[i] \le x a [ i ] ≤ x i i i l o ← i + 1 lo ← i + 1 l o ← i + 1
当 l o = h i lo = hi l o = hi l o < h i lo < hi l o < hi
# 【朴素二分】实现 bisect,支持传递 check 函数
def bisect ( a , x , lo = 0 , hi = None , check = lambda y : y ):
if hi is None : hi = len ( a )
while lo < hi :
i = ( lo + hi ) >> 1
if check ( a [ i ]) > x :
hi = i
else :
lo = i + 1
return lo
# 示例用法
a = [ 1 , 9 , 9 , 9 , 200 , 500 ]
# 找到 a [i] ** 3 + a [i] * 2 + 1 恰好大于 x 的位置
x = 1000
print ( bisect ( a , x , check = lambda y : y ** 3 + y * 2 + 1 )) #4
多维二分
a = [( 1 , 20 ), ( 2 , 19 ), ( 4 , 15 ), ( 7 , 12 )]
idx = bisect_left ( a , ( 2 , )) # 1
二分答案
二分答案一般满足条件:
求最值 / 最优问题
答案 r e s res res [ l o , h i ] [lo, hi] [ l o , hi ]
对确定的 r e s = i res = i res = i c h e c k ( i ) = F a l s e 还是 T r u e check(i) =False \text{还是 }True c h ec k ( i ) = F a l se 还是 T r u e
基本模型 :构造 ”False → True“ 模型
答案具有单调增性,即 r e s res res c h e c k ( i ) check(i) c h ec k ( i ) F a l s e / T r u e False/True F a l se / T r u e
时间复杂度:O ( c h e c k ( n ) ⋅ log ( L ) ) O(check(n) \cdot \log(L)) O ( c h ec k ( n ) ⋅ log ( L )) c h e c k ( n ) check(n) c h ec k ( n )
与二分查找区别:
二分查找:在一个已知的有序数据集上进行二分地查找
二分答案:答案有一个连续区间,在这个区间上二分,直到找到最优答案
举个例子,我们需要找到一个单调增函数 f ( x ) = x 3 + x + 1 f(x) = x^3 + x + 1 f ( x ) = x 3 + x + 1 [ 1 , 10 18 ] [1, 10^{18}] [ 1 , 1 0 18 ] c h e c k ( x ) = f ( x ) > t a r g e t check(x)=f(x) > target c h ec k ( x ) = f ( x ) > t a r g e t T r u e True T r u e
可以通过利用单调性,对 x x x c h e c k = T r u e check = True c h ec k = T r u e
def f ( x ):
return x ** 3 + x + 1
def bisect ( lo , hi , target , check ):
while lo < hi :
i = ( lo + hi ) >> 1
if check ( i , target ):
hi = i
else :
lo = i + 1
return lo
target = 99999
res = bisect ( 1 , 10 ** 18 , target , lambda x , target : f ( x ) > target )
# 找到恰好 f(x) > target 的地方
print ( res ) # 47
print ( f ( res )) # 103871
print ( f ( res - 1 )) # 97383
求“区间”问题
3.冶炼金属 - 蓝桥云课 (lanqiao.cn)
给定 n n n ( a , b ) (a, b) ( a , b ) a / / v = b a // v = b a // v = b v v v
对于 100 % 的评测用例, 1 ≤ n ≤ 10 4 , 1 ≤ b ≤ a ≤ 10 9 \text{对于 }100\%\text{ 的评测用例,}1\leq n\leq10^4\mathrm{,}1\leq b\leq a\leq10^9 对于 100% 的评测用例 , 1 ≤ n ≤ 1 0 4 , 1 ≤ b ≤ a ≤ 1 0 9
思考
显然 v v v [ 1 , 10 9 ] [1, 10^9] [ 1 , 1 0 9 ]
对于给定的 v v v
暴力做法可以达到 O ( n L ) O(nL) O ( n L ) L = 10 9 L = 10^9 L = 1 0 9
思路
import sys
input = lambda : sys . stdin . readline () . strip ()
n = int ( input ())
a , b = zip ( * [ map ( int , input () . split ()) for _ in range ( n )])
def bisect ( lo , hi , check ):
while lo < hi :
i = ( lo + hi ) // 2
if check ( i ):
hi = i
else :
lo = i + 1
return lo
m = bisect ( 1 , 10 ** 9 , lambda v : all ( A // v <= B for A , B in zip ( a , b )))
M = bisect ( 1 , 10 ** 9 , lambda v : any ( A // v < B for A , B in zip ( a , b ))) - 1
print ( m , M )
时间复杂度: O ( n log L ) O(n \log L) O ( n log L )
本题还有非二分答案做法。
3048. 标记所有下标的最早秒数 I - 力扣(LeetCode)
求“至少”问题
n , m = len ( nums ), len ( changeIndices )
def check ( mx ): # 给 mx 天是否能顺利考完试
last_day = [ - 1 ] * n
for i , x in enumerate ( changeIndices [: mx ]):
last_day [ x - 1 ] = i + 1
#如果给 mx 不能完成,等价于有为 i 遍历到考试日期的考试
if - 1 in last_day :
return False
less_day = 0
for i , x in enumerate ( changeIndices [: mx ]):
if last_day [ x - 1 ] == i + 1 : # 到了考试日期
if less_day >= nums [ x - 1 ]:
less_day -= nums [ x - 1 ]
less_day -= 1 #抵消当天不能复习
else :
return False #寄了
less_day += 1
return True
left = sum ( nums ) + n # 至少需要的天数, 也是二分的左边界
res = left + bisect . bisect_left ( range ( left , m + 1 ), True , key = check )
return - 1 if res > m else res
求“最多”问题
2226. 每个小孩最多能分到多少糖果 - 力扣(LeetCode)
给你一个 下标从 0 开始 的整数数组 candies 。数组中的每个元素表示大小为 candies[i] 的一堆糖果。你可以将每堆糖果分成任意数量的 子堆 ,但 无法 再将两堆合并到一起。
另给你一个整数 k 。你需要将这些糖果分配给 k 个小孩,使每个小孩分到 相同 数量的糖果。每个小孩可以拿走 至多一堆 糖果,有些糖果可能会不被分配。
返回每个小孩可以拿走的 最大糖果数目 。
示例 1:
示例 2:
提示:
1 <= candies.length <= 10 ** 51 <= candies[i] <= 10 ** 71 <= k <= 10 ** 12
语言整理
给定长度为 n n n a a a k k k r e s res res
思路
显然,答案有界,界于区间 [ 0 , max ( a ) ] [0, \max(a)] [ 0 , max ( a )]
对 r e s res res c h e c k check c h ec k sum(x // res for x in range(1, max(a) + 1)) < k
二分得到的结果 − 1 -1 − 1
写法 1
class Solution :
def maximumCandies ( self , a : List [ int ], k : int ) -> int :
if sum ( a ) < k : return 0
lo , hi = 1 , 10 ** 12 + 10
def check ( res ):
return sum ( x // res for x in a ) < k
while lo < hi :
i = ( lo + hi ) >> 1
if check ( i ): hi = i
else : lo = i + 1
return lo - 1
写法 2
class Solution :
def maximumCandies ( self , a : List [ int ], k : int ) -> int :
if sum ( a ) < k : return 0
lo , hi = 1 , max ( a ) + 1
def check ( res ):
return sum ( x // res for x in a ) < k
while lo < hi :
i = ( lo + hi ) >> 1
if check ( i ): hi = i
else : lo = i + 1
return lo - 1
1642. 可以到达的最远建筑 - 力扣(LeetCode)
记录一下高度差数组
对于每次 c h e c k check c h ec k r e s res res t t t
对 t t t l a d d e r ladder l a dd er t[ladders:] 部分的和
这部分的和,如果大于 b r i c k s bricks b r i c k s
找出恰好不能到达的位置 r e s res res
class Solution :
def furthestBuilding ( self , heights : List [ int ], bricks : int , ladders : int ) -> int :
n = len ( heights )
lo , hi = 0 , n
d = [ max ( 0 , heights [ i + 1 ] - heights [ i ]) for i in range ( n - 1 )]
def check ( res ):
t = sorted ( d [: res ], reverse = True )
return bricks < sum ( t [ ladders : ])
while lo < hi :
i = ( lo + hi ) >> 1
if check ( i ):
hi = i
else :
lo = i + 1
return lo - 1
def furthestBuilding ( self , heights : List [ int ], bricks : int , ladders : int ) -> int :
n = len ( heights )
d = [ max ( 0 , heights [ i + 1 ] - heights [ i ]) for i in range ( n - 1 )]
def check ( x ):
t = d [: x ]
t . sort ( reverse = True )
return not ( ladders >= x or sum ( t [ ladders : ]) <= bricks )
return bisect . bisect_left ( range ( n ), True , key = check ) - 1
中位数转化为第 k k k
对于一个长度为 n n n n − 1 2 \frac{n-1}{2} 2 n − 1
3134. 找出唯一性数组的中位数 - 力扣(LeetCode)
一共有 ( n + 1 ) × n / 2 (n + 1) \times n / 2 ( n + 1 ) × n /2 f = l e n ( s e t ( s u b ) ) f=len (set(sub)) f = l e n ( se t ( s u b )) k k k
转换为二分查找:给定一个 x x x f f f x x x r e s res res x x x r e s res res r e s > k res >k res > k “不同元素个数小于等于 k k k 问题,这是一共广义上不定长滑动窗口问题。
def get_set_subarrays_lower_k ( nums , k ):
l = res = 0
freq = Counter ()
for r , x in enumerate ( nums ):
freq [ x ] += 1
while len ( freq ) > k :
freq [ nums [ l ]] -= 1
if freq [ nums [ l ]] == 0 : freq . pop ( nums [ l ])
l += 1
res += r - l + 1
return res
class Solution :
def medianOfUniquenessArray ( self , nums : List [ int ]) -> int :
n = len ( nums )
m = (( n + 1 ) * n // 2 - 1 ) // 2
lo , hi = 0 , n // 2 + 10
while lo < hi :
mid = ( lo + hi ) // 2
if get_set_subarrays_lower_k ( nums , mid ) > m :
hi = mid
else :
lo = mid + 1
return lo
自定义比较规则
class node ():
def __init__ ( self , need , get , idx ):
self . need = need
self . get = get
self . idx = idx
def __lt__ ( self , other ):
return self . need < other . need
滑动窗口
定长滑动窗口
维护定长滑动窗口和
1343. 大小为 K 且平均值大于等于阈值的子数组数目 - 力扣(LeetCode)
def numOfSubarrays ( self , nums : List [ int ], k : int , t : int ) -> int :
n = len ( nums )
s = sum ( nums [ : k ])
res = 1 if s / k >= t else 0
for r in range ( k , n ):
s = s + nums [ r ] - nums [ r - k ]
if s / k >= t : res += 1
return res
2134. 最少交换次数来组合所有的 1 II - 力扣(LeetCode)
将环形数组中所有 1 聚集到一起的最小交换位置次数,即长度为 k k k
def minSwaps ( self , nums : List [ int ]) -> int :
k = nums . count ( 1 )
if k == 0 : return 0
nums = nums + nums
n = len ( nums )
s = sum ( nums [: k ])
res = k - s
for r in range ( k , n ):
s = s + nums [ r ] - nums [ r - k ]
res = min ( res , k - s )
return res
维护定长滑动窗口 + 字典计数
567. 字符串的排列 - 力扣(LeetCode)
判断字符串 s 1 s1 s 1 s 2 s2 s 2
def checkInclusion ( self , s1 : str , s2 : str ) -> bool :
k , n = len ( s1 ), len ( s2 )
target = Counter ( s1 )
cur = Counter ( s2 [ : k ])
if target == cur : return True
for r in range ( k , n ):
rch , lch = s2 [ r ], s2 [ r - k ]
cur [ rch ] += 1
cur [ lch ] -= 1
if target == cur : return True
return False
438. 找到字符串中所有字母异位词 - 力扣(LeetCode)
找出字符串 s 1 s1 s 1 s 2 s2 s 2
def findAnagrams ( self , s : str , p : str ) -> List [ int ]:
res = []
k , n = len ( p ), len ( s )
target = Counter ( p )
cur = Counter ( s [ : k ])
if cur == target : res . append ( 0 )
for r in range ( k , n ):
lch , rch = s [ r - k ], s [ r ]
cur [ rch ] += 1
cur [ lch ] -= 1
if cur == target :
res . append ( r - k + 1 )
return res
2841. 几乎唯一子数组的最大和 - 力扣(LeetCode)
通过 C o u n t e r ( ) Counter() C o u n t er ( ) l e n ( s e t ( w i n ) ) len(set(win)) l e n ( se t ( w in ))
def maxSum ( self , nums : List [ int ], m : int , k : int ) -> int :
s = sum ( nums [ : k ])
cnt = Counter ( nums [ : k ])
res = s if len ( cnt ) >= m else 0
n = len ( nums )
for r in range ( k , n ):
nl , nr = nums [ r - k ], nums [ r ]
s = s + nr - nl
cnt [ nr ] += 1
cnt [ nl ] -= 1
if cnt [ nl ] == 0 : cnt . pop ( nl )
if len ( cnt ) >= m and s > res : res = s
return res
2009. 使数组连续的最少操作数 - 力扣(LeetCode)
定长滑动窗口 + 正难则反:需要操作最少次数 = n - 能够不操作的最多的数字。这些数字显然是不重复的,所以首先去重。对于去重完的元素,每一个左边界 $ nums[left], 在去重数组中, , 在去重数组中 , , 在去重数组中,
def minOperations ( self , nums : List [ int ]) -> int :
n = len ( nums )
nums = sorted ( set ( nums ))
res = left = 0
for i , x in enumerate ( nums ):
while x > nums [ left ] + n - 1 :
left += 1
res = max ( res , i - left + 1 )
return n - res
1423. 可获得的最大点数 - 力扣(LeetCode)
定长滑动窗口 + 正难则反:要求前 + 后 的个数为定值 k k k n − k n-k n − k
def maxScore ( self , nums : List [ int ], k : int ) -> int :
n , tot = len ( nums ), sum ( nums )
if n == k : return tot
k = n - k
s = sum ( nums [: k ])
res = s
for r in range ( k , n ):
s = s + nums [ r ] - nums [ r - k ]
res = min ( res , s )
return tot - res
不定长滑动窗口
和大于等于 k k k
209. 长度最小的子数组 - 力扣(LeetCode)
def minSubArrayLen ( self , k : int , nums : List [ int ]) -> int :
l = s = 0
res = inf
for r , x in enumerate ( nums ):
s += x
while s >= k :
res = min ( res , r - l + 1 )
s , l = s - nums [ l ], l + 1
return res if res < inf else 0
2904. 最短且字典序最小的美丽子字符串 - 力扣(LeetCode)
求包含恰好 k k k 转换为 和大于等于 k k k 。
def shortestBeautifulSubstring ( self , s1 : str , k : int ) -> str :
if s1 . count ( '1' ) < k : return ''
n = len ( s1 )
l = s = 0
resl , resr = 0 , n
for r , ch in enumerate ( s1 ):
s += int ( ch )
while s >= k :
width = r - l + 1
if width < resr - resl + 1 or ( width == resr - resl + 1 and s1 [ l : r + 1 ] < s1 [ resl : resr + 1 ]):
resl , resr = l , r
s , l = s - int ( s1 [ l ]), l + 1
return s1 [ resl : resr + 1 ]
和小于等于 k k k
1493. 删掉一个元素以后全为 1 的最长子数组 - 力扣(LeetCode)
s s s s ≤ 1 s \le 1 s ≤ 1
def longestSubarray ( self , nums : List [ int ]) -> int :
res = 0
l = s = 0
# s <= 1 的最长子数组
for r , x in enumerate ( nums ):
s += 1 if x == 0 else 0
while s > 1 :
s -= 1 if nums [ l ] == 0 else 0
l += 1
if s <= 1 :
res = max ( res , r - l )
return res
2730. 找到最长的半重复子字符串 - 力扣(LeetCode)
预处理相邻字符相等情况,转换为 s ≤ 1 s \le 1 s ≤ 1
def longestSemiRepetitiveSubstring ( self , s1 : str ) -> int :
l = s = 0
res = 0
nums = [ 1 if s1 [ i ] == s1 [ i - 1 ] else 0 for i in range ( 1 , len ( s1 ))]
# s <= 1 的最长子串
for r , x in enumerate ( nums ):
s += x
while s > 1 :
s -= nums [ l ]
l += 1
res = max ( res , r - l + 1 )
return res + 1
不包含重复元素的子数组(最长长度 / 最大和)
包含重复元素的条件是 l e n ( w i n ) < r − l + 1 len(win) < r - l+1 l e n ( w in ) < r − l + 1
3. 无重复字符的最长子串 - 力扣(LeetCode)
方法一:使用 d d d d [ c h ] d[ch] d [ c h ] [ l , r ] [l,~r] [ l , r ] l = d [ c h ] + 1 l=d[ch]+1 l = d [ c h ] + 1
def lengthOfLongestSubstring ( self , s : str ) -> int :
d = defaultdict ( lambda : - inf )
l = res = 0
for r , ch in enumerate ( s ):
if d [ ch ] >= l :
l = d . pop ( ch ) + 1
d [ ch ] = r
res = max ( res , r - l + 1 )
return res
方法二:
不包含重复元素的条件是 l e n ( w i n ) = r − l + 1 len(win) = r - l+1 l e n ( w in ) = r − l + 1
def lengthOfLongestSubstring ( self , s : str ) -> int :
res = 0
l = 0
cnt = Counter ()
for r , ch in enumerate ( s ):
cnt [ ch ] += 1
while len ( cnt ) < r - l + 1 :
lch = s [ l ]
cnt [ lch ] -= 1
if cnt [ lch ] == 0 : cnt . pop ( lch )
l += 1
res = max ( res , r - l + 1 )
return res
1695. 删除子数组的最大得分 - 力扣(LeetCode)
不包含重复元素的子数组的最大和。不包含重复元素的条件是 l e n ( w i n ) = r − l + 1 len(win) = r - l+1 l e n ( w in ) = r − l + 1
def maximumUniqueSubarray ( self , nums : List [ int ]) -> int :
res = 0
l = s = 0
cnt = Counter ()
for r , x in enumerate ( nums ):
cnt [ x ] += 1
s += x
while len ( cnt ) < r - l + 1 :
nl = nums [ l ]
s -= nl
cnt [ nl ] -= 1
if cnt [ nl ] == 0 : cnt . pop ( nl )
l += 1
res = max ( res , s )
return res
2401. 最长优雅子数组 - 力扣(LeetCode)
不定长滑窗 + 位运算。
子数组中所有数两两 A N D AND A N D 0 0 0 1 1 1 1 1 1 o r s ors ors O R OR OR r r r r & o r s = 0 r~ \& ~ors = 0 r & ors = 0 a ∣ ( b & c ) = ( a & b ) ∣ ( a & c ) = 0 a | (b ~\&~ c) = (a \&~b) | (a \&~ c)=0 a ∣ ( b & c ) = ( a & b ) ∣ ( a & c ) = 0 l e f t left l e f t o r s ors ors 1 1 1
def longestNiceSubarray ( self , nums : List [ int ]) -> int :
# nums [i] <= 1e9,30 个二进制 bit 位上
ors = 0
l = 0
res = 0
for r , x in enumerate ( nums ):
while x & ors > 0 :
ors ^= nums [ l ]
l += 1
ors |= x
res = max ( res , r - l + 1 )
return res
子数组合法方案数问题
先更新滑动窗口状态(广义上),检查、剔除不合法的元素(如窗口左边界右移、计数器减一等),累积上 r e s res res
乘积小于 k k k
713. 乘积小于 K 的子数组 - 力扣(LeetCode)
def numSubarrayProductLessThanK ( self , nums : List [ int ], k : int ) -> int :
if k <= 1 : return 0
res = 0
l , prod = 0 , 1
for r , x in enumerate ( nums ):
prod *= x
while prod >= k :
prod , l = prod / nums [ l ], l + 1
res += r - l + 1
return res
不同值个数小于等于 k k k
使用 f r e q freq f re q l l l
3134. 找出唯一性数组的中位数 - 力扣(LeetCode)
# 计算不同值元素个数小于对于 k 的子数组个数
def get_set_subarrays_lower_k ( nums , k ):
l = res = 0
freq = Counter ()
for r , x in enumerate ( nums ):
freq [ x ] += 1
while len ( freq ) > k :
freq [ nums [ l ]] -= 1
if freq [ nums [ l ]] == 0 : freq . pop ( nums [ l ])
l += 1
res += r - l + 1
return res
不定长滑窗 + 哈希计数
不定长滑窗哈希表:所有 f r e q [ x ] ≤ k freq[x] \le k f re q [ x ] ≤ k O ( n ) O(n) O ( n ) O ( n 2 ) O(n^2) O ( n 2 ) c n t cnt c n t f r e q [ x ] > k freq[x] > k f re q [ x ] > k 在边界处增减 1 。转换为 c n t = 0 cnt = 0 c n t = 0 O ( n ) O(n) O ( n )
2958. 最多 K 个重复元素的最长子数组 - 力扣(LeetCode)
def maxSubarrayLength ( self , nums : List [ int ], k : int ) -> int :
# 所有 freq [x] <= k 的最长子数组
# 转换为 cnt == 0 最长子数组 (cnt 为 freq [x] > k 的个数)
freq = Counter ()
l = res = cnt = 0
for r , x in enumerate ( nums ):
cnt += int ( freq [ x ] == k )
freq [ x ] += 1
while cnt > 0 :
nl = nums [ l ]
cnt -= int ( freq [ nl ] == k + 1 )
freq [ nl ] -= 1
l += 1
res = max ( res , r - l + 1 )
return res
Problem - 1777C - Codeforces
不定长滑窗 + 哈希计数。首先对 n u m s nums n u m s m = 1 m=1 m = 1 0 0 0 2 ∼ m 2 \sim m 2 ∼ m f r e q freq f re q 2 ∼ m 2 \sim m 2 ∼ m f r e q [ x ] ≥ 1 freq[x] \ge 1 f re q [ x ] ≥ 1 O ( n ) O(n) O ( n ) O ( m n ) O(mn) O ( mn ) c n t cnt c n t f r e q [ x ] ≥ 1 freq[x] \ge 1 f re q [ x ] ≥ 1 c n t cnt c n t
from collections import *
from math import *
import sys
input = lambda : sys . stdin . readline () . strip ()
# 预处理 2 ~ mx 中所有数的约数的列表
mx = 100001
factors = [[] for _ in range ( mx )]
for i in range ( 2 , mx ):
for j in range ( i , mx , i ):
factors [ j ] . append ( i )
t = int ( input ())
def solve ():
n , m = map ( int , input () . split ())
nums = list ( set ( map ( int , input () . split ())))
nums . sort ()
if m == 1 :
return 0
# 2, 3, ... , m
# 求所有滑窗中,freq [2...m] >= 1 的最小极差。
# 用 cnt 统计 freq [x] >= 1 的个数,求 cnt == m - 1 的滑窗的最小极差
freq = Counter ()
l = cnt = 0
res = inf
for r , x in enumerate ( nums ):
for y in factors [ x ]:
if y > m : break
if freq [ y ] == 0 : cnt += 1
freq [ y ] += 1
while cnt == m - 1 :
nl = nums [ l ]
res = min ( res , x - nl )
for y in factors [ nl ]:
if y > m : break
if freq [ y ] == 1 : cnt -= 1
freq [ y ] -= 1
l += 1
return res if res < inf else - 1
for _ in range ( t ):
print ( solve ())
枚举型滑窗 / 分组滑窗
枚举出现种类个数
枚举 + 不定长滑窗 + 哈希计数
显然 k = 1 k=1 k = 1
考虑 k > 1 k>1 k > 1 ≥ k \ge k ≥ k s 1 [ l ∼ r ] s1[l\sim r] s 1 [ l ∼ r ] s 1 [ r + 1 ] s1[r+1] s 1 [ r + 1 ] s 1 s1 s 1 l l l ′ b b a a a c b ′ 'bbaaacb' ′ bbaaa c b ′ r = 4 r=4 r = 4 c c c b b a a a b bbaaab bbaaab
然而,如果限制 / 约束了子串中不同字母的种类个数 c c c c ∈ [ 1 , 26 ] c \in [1, 26] c ∈ [ 1 , 26 ] c c c f r e q freq f re q k k k c n t cnt c n t t c n t tcnt t c n t
def longestSubstring ( self , s1 : str , k : int ) -> int :
if k == 1 : return len ( s1 )
n = len ( s1 )
res = 0
# 枚举滑窗
for c in range ( 1 , len ( set ( s1 )) + 1 ):
# 滑窗中字母种类个数恰好为 c
freq = Counter ()
cnt = 0 # 哈希计数
tcnt = 0 # 种类计数
l = 0
for r , ch in enumerate ( s1 ):
if freq [ ch ] == 0 :
cnt += 1
tcnt += 1
if freq [ ch ] == k - 1 :
cnt -= 1
freq [ ch ] += 1
while tcnt > c :
lch = s1 [ l ]
if freq [ lch ] == k :
cnt += 1
if freq [ lch ] == 1 :
tcnt -= 1
cnt -= 1
freq [ lch ] -= 1
l += 1
if tcnt == c and cnt == 0 :
res = max ( res , r - l + 1 )
return res
时间复杂度:O ( 26 N ) O(26N) O ( 26 N )
2953. 统计完全子字符串 - 力扣(LeetCode)
定长滑窗 + 枚举
def countCompleteSubstrings ( self , s1 : str , k : int ) -> int :
res = 0
# s 中每个字符恰好出现 k 次的子串个数
def f ( s ):
#
# 枚举字符种类个数
m = len ( set ( s ))
n = len ( s )
res = 0
# 由于是恰好 k 个,所以滑窗长度为 c * k
for c in range ( 1 , m + 1 ):
K = c * k
if K > n : break
freq = Counter ()
cnt = 0 # 等于 k 的个数
for i in range ( K ):
ch = s [ i ]
if freq [ ch ] == k - 1 : cnt += 1
elif freq [ ch ] == k : cnt -= 1
freq [ ch ] += 1
res += int ( cnt == c )
for r in range ( K , n ):
ch , lch = s [ r ], s [ r - K ]
if lch != ch :
if freq [ ch ] == k - 1 : cnt += 1
elif freq [ ch ] == k : cnt -= 1
if freq [ lch ] == k : cnt -= 1
elif freq [ lch ] == k + 1 : cnt += 1
freq [ ch ] += 1
freq [ lch ] -= 1
if freq [ lch ] == 0 : freq . pop ( lch )
res += int ( cnt == c )
return res
sub = ''
for ch in s1 :
if sub and abs ( ord ( ch ) - ord ( sub [ - 1 ])) > 2 :
res += f ( sub )
sub = ch
else :
sub += ch
res += f ( sub )
return res
时间复杂度:O ( 26 N ) O(26N) O ( 26 N )
枚举多起点
分组滑窗
2831. 找出最长等值子数组 - 力扣(LeetCode)
按元素对下标分组 + 不定长滑窗
预处理每个元素所有下标构成的数组,对某一元素 x x x a a a a [ r ] − a [ l ] + 1 a[r] - a[l] + 1 a [ r ] − a [ l ] + 1 r − l + 1 r-l+1 r − l + 1 x x x k k k a [ r ] − a [ l ] + 1 − ( r − l + 1 ) ≤ k a[r] - a[l] + 1 - (r - l + 1) \le k a [ r ] − a [ l ] + 1 − ( r − l + 1 ) ≤ k
def longestEqualSubarray ( self , nums : List [ int ], k : int ) -> int :
d = defaultdict ( list )
for i , x in enumerate ( nums ):
d [ x ] . append ( i )
res = 1
for a in d . values ():
m = len ( a )
l = 0
for r in range ( m ):
while a [ r ] - a [ l ] + 1 - ( r - l + 1 ) > k :
l += 1
res = max ( res , r - l + 1 )
return res
双指针
相向双指针
2105. 给植物浇水 II - 力扣(LeetCode)
def minimumRefill ( self , nums : List [ int ], A : int , B : int ) -> int :
n = len ( nums )
i , j = 0 , n - 1
a , b = A , B
res = 0
while i <= j :
l , r = nums [ i ], nums [ j ]
if i < j :
if a < l :
a = A - l
res += 1
else :
a -= l
if b < r :
b = B - r
res += 1
else :
b -= r
else :
x = max ( a , b )
if x < l :
res += 1
i , j = i + 1 , j - 1
return res
同向双指针
1574. 删除最短的子数组使剩余数组有序 - 力扣(LeetCode)
同向双指针 + 贪心。
def findLengthOfShortestSubarray ( self , nums : List [ int ]) -> int :
n = len ( nums )
l , r = 0 , n - 1
while l + 1 < n and nums [ l ] <= nums [ l + 1 ]:
l += 1
if l == n - 1 : return 0
while r - 1 >= 0 and nums [ r - 1 ] <= nums [ r ]:
r -= 1
res , mxl = r , l
for l in range ( mxl + 1 ):
while r < n and nums [ r ] < nums [ l ]:
r += 1
res = min ( res , r - l - 1 )
return res
1163. 按字典序排在最后的子串 - 力扣(LeetCode)
转换问题:子串中字典序最大的串
性质 1: 后缀 s [ i : ] s[i:] s [ i : ] s [ i ] s[i] s [ i ]
性质 2:考察字典序最大的串,记为 s u b sub s u b s u b [ 0 ] sub[0] s u b [ 0 ]
例如,'ycyba' 是一个可能的最大串,而 'yczba'就不是,因为 'zba' > 'yczba'。
对于两个位置 i , j i,j i , j k k k s [ i : ] s[i:] s [ i : ] s [ j : ] s[j:] s [ j : ]
s [ i + k ] = s [ j + k ] s[i+k] = s[j+k] s [ i + k ] = s [ j + k ] k + 1 k+1 k + 1
s [ i + k ] < s [ j + k ] s[i+k] < s[j+k] s [ i + k ] < s [ j + k ] i i i max ( i + k + 1 , j ) \max (i+k+1, j) max ( i + k + 1 , j )
首先可以肯定 [ i + 1 , i + k ] [i+1, i+k] [ i + 1 , i + k ] [ i + 1 , i + k ] [i+1, i+k] [ i + 1 , i + k ] s [ i ∼ i + k ] s[i \sim i+k] s [ i ∼ i + k ]
其次,如果 i + k + 1 ≤ j i+k+1 \le j i + k + 1 ≤ j j j j [ i + k + 1 , j − 1 ] [i+k+1, j - 1] [ i + k + 1 , j − 1 ] i i i s [ i : i + k ] s[i:i+k] s [ i : i + k ]
最后,如果 i + k + 1 > j i+k+1>j i + k + 1 > j s [ i : i + k ] = y y b b y y b s[i:i+k] = yybbyyb s [ i : i + k ] = yy bb yy b s [ j : j + k ] = y y b b y y c s[j:j+k] = yybbyyc s [ j : j + k ] = yy bb yyc y y b b y y yybbyy yy bb yy y y c yyc yyc [ j , i + k ] [j, i + k] [ j , i + k ]
所以, i = max ( i + k + 1 , j ) i = \max(i+k+1, j) i = max ( i + k + 1 , j ) j = i + 1 , k = 0 j = i + 1, k = 0 j = i + 1 , k = 0
s [ i + k ] > s [ j + k ] s[i+k] > s[j+k] s [ i + k ] > s [ j + k ] j j j j + k + 1 , k = 0 j+k+1, k = 0 j + k + 1 , k = 0
class Solution :
def lastSubstring ( self , s : str ) -> str :
i , j , k = 0 , 1 , 0
n = len ( s )
while j + k < n :
if s [ i + k ] == s [ j + k ]:
k += 1
else :
if s [ i + k ] < s [ j + k ]:
i = j if j > i + k + 1 else i + k + 1
j = i + 1
else : # s [i + k] > s [j + k]:
j += k + 1
k = 0
return s [ i : ]
分组循环
适用于:数组会被分割成若干组,且每一组的判断/处理逻辑是一样的。
核心思想 :
外层循环负责遍历组之前的准备工作(记录开始位置),和遍历组之后的统计工作(更新答案最大值)。
内层循环负责遍历组,找出这一组最远在哪结束。
模板:
n = len ( nums )
i = 0
while i < n :
start = i
while i < n and ... :
i += 1
# 从 start 到 i-1 是一组
# 下一组从 i 开始,无需 i += 1
ans = max ( ans , i - start )
时间复杂度:O ( n ) O(n) O ( n )
2760. 最长奇偶子数组 - 力扣(LeetCode)
def longestAlternatingSubarray ( self , nums : List [ int ], k : int ) -> int :
n = len ( nums )
i = res = 0
while i < n :
x = nums [ i ]
if x > k or x & 1 :
i += 1
continue
start = i
i += 1
while i < n and nums [ i ] <= k and nums [ i - 1 ] & 1 != nums [ i ] & 1 :
i += 1
res = max ( res , i - start )
return res
单调结构
单调栈
def trap ( self , height : List [ int ]) -> int :
# 单调栈:递减栈
stk , n , res = deque (), len ( height ), 0
for i in range ( n ):
# 1.单调栈不为空、且违反单调性
while stk and height [ i ] > height [ stk [ - 1 ]]:
# 2.出栈
top = stk . pop ()
# 3.特判
if not stk :
break
# 4.获得左边界、宽度
left = stk [ - 1 ]
width = i - left - 1
# 5.计算
res += ( min ( height [ left ], height [ i ]) - height [ top ]) * width
# 6.入栈
stk . append ( i )
return res
84. 柱状图中最大的矩形 - 力扣(LeetCode)
矩形面积求解:维护单调增栈,同时首尾插入哨兵节点。
def largestRectangleArea ( self , heights : List [ int ]) -> int :
heights . append ( - 1 )
stk = [ - 1 ]
res = 0
for i , h in enumerate ( heights ):
while len ( stk ) > 1 and h < heights [ stk [ - 1 ]]:
cur = stk . pop ()
l = stk [ - 1 ]
width = i - l - 1
s = width * heights [ cur ]
res = max ( res , s )
stk . append ( i )
return res
1793. 好子数组的最大分数 - 力扣(LeetCode)
矩形面积求解问题变形:求 m i n ( n u m s [ i ] , ⋯ , n u m s [ j ] ) × ( j − i + 1 ) min(nums[i], ~ \cdots~, nums[j]) \times (j -i+1) min ( n u m s [ i ] , ⋯ , n u m s [ j ]) × ( j − i + 1 ) i , j i, ~j i , j
def maximumScore ( self , nums : List [ int ], k : int ) -> int :
stk = [ - 1 ]
nums . append ( - 1 )
res = 0
for i , h in enumerate ( nums ):
while len ( stk ) > 1 and h < nums [ stk [ - 1 ]]:
cur = stk . pop ()
l = stk [ - 1 ]
if not ( l + 1 <= k and i - 1 >= k ): continue # 约束范围
width = i - l - 1
res = max ( res , width * nums [ cur ])
stk . append ( i )
return res
单调栈维护元素的左右山形边界
对于 a [ i ] = x a[i]=x a [ i ] = x l l l a [ l + 1 ] ∼ a [ i − 1 ] ≥ 或者 ≤ x a[l + 1] \sim a[i-1] \ge 或者 \le x a [ l + 1 ] ∼ a [ i − 1 ] ≥ 或者 ≤ x
对于 a [ i ] = x a[i]=x a [ i ] = x r r r a [ i + 1 ] ∼ a [ r − 1 ] ≥ 或者 ≤ x a[i + 1] \sim a[r-1] \ge 或者 \le x a [ i + 1 ] ∼ a [ r − 1 ] ≥ 或者 ≤ x
stk , left = [], [ - 1 ] * n
for i in range ( n ):
x = nums [ i ]
while stk and x <= nums [ stk [ - 1 ]]: stk . pop ()
if stk : left [ i ] = stk [ - 1 ]
stk . append ( i )
stk , right = [], [ n ] * n
for i in range ( n - 1 , - 1 , - 1 ):
x = nums [ i ]
while stk and x <= nums [ stk [ - 1 ]]: stk . pop ()
if stk : right [ i ] = stk [ - 1 ]
stk . append ( i )
2334. 元素值大于变化阈值的子数组 - 力扣(LeetCode)
在山形边界开区间所夹的区间内,满足所有元素大于等于山形边界元素 x x x x = min ( a [ l + 1 ] ∼ a [ r − 1 ] ) x = \min(a[l+1] \sim a[r-1]) x = min ( a [ l + 1 ] ∼ a [ r − 1 ])
def validSubarraySize ( self , nums : List [ int ], threshold : int ) -> int :
n = len ( nums )
# 单调栈解法
stk , left = [], [ - 1 ] * n
for i in range ( n ):
x = nums [ i ]
while stk and x <= nums [ stk [ - 1 ]]: stk . pop ()
if stk : left [ i ] = stk [ - 1 ]
stk . append ( i )
stk , right = [], [ n ] * n
for i in range ( n - 1 , - 1 , - 1 ):
x = nums [ i ]
while stk and x <= nums [ stk [ - 1 ]]: stk . pop ()
if stk : right [ i ] = stk [ - 1 ]
stk . append ( i )
for i , x in enumerate ( nums ):
l , r = left [ i ], right [ i ]
k = r - l - 1
if x > ( threshold / k ): return k
return - 1
单调队列
滑窗最大值 ~ 维护递减小队列; 滑窗最小值 ~ 维护递增队列
239. 滑动窗口最大值 - 力扣(LeetCode)
def maxSlidingWindow ( self , nums : List [ int ], k : int ) -> List [ int ]:
n = len ( nums )
res = []
q = deque ()
for i , x in enumerate ( nums ):
# 1.入,需要维护单调减队列的有序性
while q and x >= nums [ q [ - 1 ]]:
q . pop ()
q . append ( i )
# 2.出,当滑动窗口区间长度大于 k 的时候,弹出去左端的
if i - q [ 0 ] + 1 > k :
q . popleft ()
# 记录元素
if i >= k - 1 :
res . append ( nums [ q [ 0 ]])
return res
2398. 预算内的最多机器人数目 - 力扣(LeetCode)
单调队列 + 滑动窗口
def maximumRobots ( self , chargeTimes : List [ int ], runningCosts : List [ int ], budget : int ) -> int :
n = len ( chargeTimes )
res = 0
s = l = 0 # 滑窗的和 / 窗口左边界
q = deque () # 单调队列维护最大值
# 滑动窗口
for i , x in enumerate ( chargeTimes ):
while q and x >= chargeTimes [ q [ - 1 ]]:
q . pop ()
q . append ( i )
s += runningCosts [ i ]
while i - l + 1 > 0 and s * ( i - l + 1 ) + chargeTimes [ q [ 0 ]] > budget :
s -= runningCosts [ l ]
l += 1
if l > q [ 0 ]:
q . popleft ()
res = max ( res , i - l + 1 )
return res
单调栈优化 dp
2617. 网格图中最少访问的格子数 - 力扣(LeetCode)
暴力 dp 转移做法
class Solution :
def minimumVisitedCells ( self , grid : List [ List [ int ]]) -> int :
m , n = len ( grid ), len ( grid [ 0 ])
f = [[ inf ] * n for _ in range ( m )]
f [ - 1 ][ - 1 ] = 0
for i in range ( m - 1 , - 1 , - 1 ):
for j in range ( n - 1 , - 1 , - 1 ):
g = grid [ i ][ j ]
for k in range ( 1 , min ( g + 1 , m - i )):
f [ i ][ j ] = min ( f [ i ][ j ], f [ i + k ][ j ] + 1 )
for k in range ( 1 , min ( g + 1 , n - j )):
f [ i ][ j ] = min ( f [ i ][ j ], f [ i ][ j + k ] + 1 )
return f [ 0 ][ 0 ] + 1 if f [ 0 ][ 0 ] != inf else - 1
单调栈 + 二分 优化 dp
倒序枚举 i , j i,~j i , j
f [ i ] [ j ] = min { min k = j + 1 j + g f [ i ] [ k ] , min k = i + 1 i + g f [ k ] [ j ] } + 1
f [i][j] =\min\left\{\min_{k = j+1}^{j+g}f [i][k], ~\min_{k = i+1}^{i+g}f [k][j]\right\}+1
f [ i ] [ j ] = min { k = j + 1 min j + g f [ i ] [ k ] , k = i + 1 min i + g f [ k ] [ j ] } + 1 可以发现左边界 i i i j + g j +g j + g
由于栈中元素有序,每次查找只需要二分即可找出最值。
def minimumVisitedCells ( self , grid : List [ List [ int ]]) -> int :
m , n = len ( grid ), len ( grid [ 0 ])
stkyy = [ deque () for _ in range ( n )] # 列上单调栈
f = 0 # 行上单调栈
for i in range ( m - 1 , - 1 , - 1 ):
stkx = deque ()
for j in range ( n - 1 , - 1 , - 1 ):
g , stky = grid [ i ][ j ], stkyy [ j ]
f = 1 if i == m - 1 and j == n - 1 else inf
if g > 0 :
if stkx and j + g >= stkx [ 0 ][ 1 ]:
mnj = bisect_left ( stkx , j + g + 1 , key = lambda x : x [ 1 ]) - 1
f = stkx [ mnj ][ 0 ] + 1
if stky and i + g >= stky [ 0 ][ 1 ]:
mni = bisect_left ( stky , i + g + 1 , key = lambda x : x [ 1 ]) - 1
f = min ( f , stky [ mni ][ 0 ] + 1 )
if f < inf :
while stkx and f <= stkx [ 0 ][ 0 ]:
stkx . popleft ()
stkx . appendleft (( f , j ))
while stky and f <= stky [ 0 ][ 0 ]:
stky . popleft ()
stky . appendleft (( f , i ))
return f if f != inf else - 1
LCP 32. 批量处理任务 - 力扣(LeetCode)
二分单调栈
class Solution :
def processTasks ( self , tasks : List [ List [ int ]]) -> int :
stk = [( - 1 , - 1 , 0 )]
tasks . sort ( key = lambda x : x [ 1 ])
for l , r , t in tasks :
p = bisect_left ( stk , ( l , )) - 1
blue = stk [ - 1 ][ 2 ] - stk [ p ][ 2 ]
red = max ( 0 , stk [ p ][ 1 ] - l + 1 )
t -= blue + red
if t <= 0 : continue
nl , nr , nt = r - t + 1 , r , stk [ - 1 ][ 2 ] + t
while stk :
ll , rr , _ = stk [ - 1 ]
if nl > rr : break
nl = ll - ( rr - nl + 1 )
stk . pop ()
stk . append (( nl , nr , nt ))
return stk [ - 1 ][ 2 ]
单调队列优化 dp
2944. 购买水果需要的最少金币数 - 力扣(LeetCode)
暴力做法:O ( n 2 ) O(n^2) O ( n 2 )
def minimumCoins ( self , prices : List [ int ]) -> int :
n = len ( prices )
# f [i] 表示获得 i 及其以后的所有水果的最少开销
f = [ inf ] * ( n + 1 )
for i in range ( n , 0 , - 1 ):
# [i + 1, 2 * i] 免费
if 2 * i >= n :
f [ i ] = prices [ i - 1 ]
else :
for j in range ( i + 1 , 2 * i + 2 ):
f [ i ] = min ( f [ i ], f [ j ] + prices [ i - 1 ])
return f [ 1 ]
注意到 i 递减,区间 [ i + 1 , 2 × i + 1 ] [i + 1, 2 \times i + 1] [ i + 1 , 2 × i + 1 ]
def minimumCoins ( self , prices : List [ int ]) -> int :
n = len ( prices )
# f [i] 表示获得 i 及其以后的所有水果的最少开销
f = [ inf ] * ( n + 1 )
q = deque ()
for i in range ( n , 0 , - 1 ):
# i 递减,区间[i + 1, 2 * i + 1]是一个定长为 i + 1 的滑动窗口
while q and q [ - 1 ][ 1 ] - ( i + 1 ) + 1 > i + 1 :
q . pop ()
if 2 * i >= n :
f [ i ] = prices [ i - 1 ]
else :
f [ i ] = q [ - 1 ][ 0 ] + prices [ i - 1 ]
while q and f [ i ] <= q [ 0 ][ 0 ]:
q . popleft ()
q . appendleft (( f [ i ], i ))
return f [ 1 ]
前缀/差分
一维前缀和
问题定义
对于长度为 n 的数组 a , 给定 q 组区间 [ l , r ] , 对每组区间 [ l , r ] 求 ∑ i = l r a [ i ] = a [ l ] + a [ l + 1 ] + ⋯ + a [ r ] , 其中 l ≤ r
\begin{aligned}
&对于长度为 n 的数组 a, 给定 q 组区间 [l, r], \\
&对每组区间 [l, r] 求 \sum_{i = l}^r{a [i]} = a [l] + a [l + 1] + \cdots+a [r], 其中 l\le r
\end{aligned}
对于长度为 n 的数组 a , 给定 q 组区间 [ l , r ] , 对每组区间 [ l , r ] 求 i = l ∑ r a [ i ] = a [ l ] + a [ l + 1 ] + ⋯ + a [ r ] , 其中 l ≤ r 数据范围
n ∈ [ 1 , 10 5 ] , q ∈ [ 1 , 10 5 ] n \in [1, 10^5], q \in [1, 10^5] n ∈ [ 1 , 1 0 5 ] , q ∈ [ 1 , 1 0 5 ]
思路:暴力
算法基础:前缀和
定义: p [ i ] = ∑ ( a [ : i ] ) , \text{定义: }p[i] = \sum(a[: i]), \\ 定义 : p [ i ] = ∑ ( a [ : i ]) ,
则有 : p [ 0 ] = ∑ ( a [ : 0 ] ) = 0 p [ 1 ] = ∑ ( a [ : 1 ] ) = a [ 0 ] p [ n − 1 ] = ∑ ( a [ : n − 1 ] ) = a [ 0 ] + . . . + a [ n − 2 ] p [ n ] = ∑ ( a [ : n ] ) = a [ 0 ] + . . . + a [ n − 2 ] + a [ n − 1 ] = ∑ ( a ) 显然可以发现 p [ n ] − p [ n − 1 ] = a [ n − 1 ]
\begin{aligned}
则有:
p [0] = \sum(a [: 0]) &= 0 \\
p [1] = \sum(a [: 1]) &= a [0] \\
p [n - 1] = \sum(a [: n - 1]) &= a [0] + ... + a [n - 2] \\
p [n] = \sum(a [: n]) &= a [0] + ... + a [n - 2] + a [n - 1] = \sum(a) \\
显然可以发现 p [n] - p [n-1] &= a [n-1] \\
\end{aligned}
则有 : p [ 0 ] = ∑ ( a [ : 0 ]) p [ 1 ] = ∑ ( a [ : 1 ]) p [ n − 1 ] = ∑ ( a [ : n − 1 ]) p [ n ] = ∑ ( a [ : n ]) 显然可以发现 p [ n ] − p [ n − 1 ] = 0 = a [ 0 ] = a [ 0 ] + ... + a [ n − 2 ] = a [ 0 ] + ... + a [ n − 2 ] + a [ n − 1 ] = ∑ ( a ) = a [ n − 1 ] 即 p [ n ] = p [ n − 1 ] + a [ n − 1 ] , p[n] = p[n - 1] + a[n-1], p [ n ] = p [ n − 1 ] + a [ n − 1 ] ,
即 p [ n + 1 ] = p [ n ] + a [ n ] , p[n + 1] = p[n] + a[n], p [ n + 1 ] = p [ n ] + a [ n ] ,
模板
p = 0 * [ n + 1 ]
for i in range ( n ):
p [ i + 1 ] = p [ i ] + a [ i ]
P8218 【深进 1.例 1】求区间和 - 洛谷 (luogu.com.cn)
import sys
input = lambda : sys . stdin . readline () . strip ()
n = int ( input ())
a = list ( map ( int , input () . split ()))
q = int ( input ())
# 前缀和模板, p [i] = sum(a [: i])
p = [ 0 ] * ( n + 1 )
for i in range ( n ):
p [ i + 1 ] = p [ i ] + a [ i ]
for _ in range ( q ):
l , r = map ( int , input () . split ())
# l, r 下标从 1 开始,即求 a [l - 1] + a [l] + ... + a [r - 1]
# 即 sum(a [l - 1: r])
# 即 p [r] - p [l - 1]
print ( p [ r ] - p [ l - 1 ])
一维差分
def maximumBeauty ( self , nums : List [ int ], k : int ) -> int :
n = len ( nums )
d = k - min ( nums )
for i in range ( n ): nums [ i ] += d
mx = max ( nums ) + k
a = [ 0 ] * ( mx + 1 )
d = [ 0 ] * ( mx + 2 )
for x in nums :
d [ x - k ] += 1
d [ x + k + 1 ] -= 1
a [ 0 ] = d [ 0 ]
for i in range ( 1 , mx + 1 ):
a [ i ] = a [ i - 1 ] + d [ i ]
return max ( a )
二维差分
d = [[ 0 ] * ( n + 2 ) for _ in range ( m + 2 )]
# 对矩阵中执行操作,使得左上角为(i, j),右下角为(x, y)的矩阵都加 k,等价于如下操作
d [ i + 1 ][ j + 1 ] += k
d [ x + 2 ][ y + 2 ] += k
d [ i + 1 ][ y + 2 ] -= k
d [ x + 2 ][ j + 1 ] -= k
# 还原差分时,直接原地还原
for i in range ( m ):
for j in range ( n ):
d [ i + 1 ][ j + 1 ] += d [ i ][ j + 1 ] + d [ i + 1 ][ j ] - d [ i ][ j ]
二维前缀
3070. 元素和小于等于 k 的子矩阵的数目 - 力扣(LeetCode)
class PreSum2d :
# 二维前缀和(支持加法和异或),只能离线使用,用 n*m 时间预处理,用 O1 查询子矩阵的和;op = 0 是加法,op = 1 是异或
def __init__ ( self , g , op = 0 ):
m , n = len ( g ), len ( g [ 0 ])
self . op = op
self . p = p = [[ 0 ] * ( n + 1 ) for _ in range ( m + 1 )]
if op == 0 :
for i in range ( m ):
for j in range ( n ):
p [ i + 1 ][ j + 1 ] = p [ i ][ j + 1 ] + p [ i + 1 ][ j ] - p [ i ][ j ] + g [ i ][ j ]
elif op == 1 :
for i in range ( m ):
for j in range ( n ):
p [ i + 1 ][ j + 1 ] = p [ i ][ j + 1 ] ^ p [ i + 1 ][ j ] ^ p [ i ][ j ] ^ g [ i ][ j ]
# O(1)时间查询闭区间左上(a, b), 右下(c, d)矩形部分的数字和。
def sum_square ( self , a , b , c , d ):
if self . op == 0 :
return self . p [ c + 1 ][ d + 1 ] + self . p [ a ][ b ] - self . p [ a ][ d + 1 ] - self . p [ c + 1 ][ b ]
elif self . op == 1 :
return self . p [ c + 1 ][ d + 1 ] ^ self . p [ a ][ b ] ^ self . p [ a ][ d + 1 ] ^ self . p [ c + 1 ][ b ]
class NumMatrix :
def __init__ ( self , mat : List [ List [ int ]]):
self . pre = PreSum2d ( mat )
def sumRegion ( self , row1 : int , col1 : int , row2 : int , col2 : int ) -> int :
# pre = self.pre
return self . pre . sum_square ( row1 , col1 , row2 , col2 )
class Solution :
def countSubmatrices ( self , grid : List [ List [ int ]], k : int ) -> int :
n = len ( grid )
m = len ( grid [ 0 ])
res = 0
p = NumMatrix ( grid )
for i in range ( n ):
for j in range ( m ):
if p . sumRegion ( 0 , 0 , i , j ) <= k :
res += 1
return res
pre[i + 1][j + 1] 是左上角为(0, 0) 右下角为 (i, j)的矩阵的元素和。
如果是前缀异或是:
p[i+1][j+1] = p[i][j+1]^p[i+1][j]^p[i][j]^g[i][j]
def countSubmatrices ( self , grid : List [ List [ int ]], k : int ) -> int :
m , n = len ( grid ), len ( grid [ 0 ])
pre = [[ 0 ] * ( n + 1 ) for _ in range ( m + 1 )]
for i in range ( m ):
for j in range ( n ):
pre [ i + 1 ][ j + 1 ] = pre [ i ][ j + 1 ] + pre [ i + 1 ][ j ] - pre [ i ][ j ] + grid [ i ][ j ]
res = 0
for i in range ( m ):
for j in range ( n ):
if pre [ i + 1 ][ j + 1 ] <= k :
res += 1
return res
前缀异或 / 自定义前缀操作
pre = list ( accumulate ( nums , xor , initial = 0 ))
数学
数论
取整函数
上下取整转换
⌈ n m ⌉ = ⌊ n − 1 m ⌋ + 1 = ⌊ n + m − 1 m ⌋
\left\lceil \frac{n}{m} \right\rceil = \left\lfloor \frac{n - 1}{m} \right\rfloor + 1 = \left\lfloor \frac{n + m -1}{m} \right\rfloor
⌈ m n ⌉ = ⌊ m n − 1 ⌋ + 1 = ⌊ m n + m − 1 ⌋ 证明:由于有 ⌈ n m ⌉ = ⌊ n m ⌋ \left\lceil \frac{n}{m} \right\rceil = \left\lfloor \frac{n}{m} \right\rfloor ⌈ m n ⌉ = ⌊ m n ⌋ n = k ⋅ m n=k \cdot m n = k ⋅ m n = k ⋅ m − r , r ∈ ( 0 , m ) n=k\cdot m-r,r\in(0,m) n = k ⋅ m − r , r ∈ ( 0 , m ) k = ⌈ k ⋅ m m ⌉ = ⌈ k ⋅ m − r m ⌉ = ⌈ k ⋅ m − r + 1 m ⌉ = 1 + ⌊ k ⋅ m − r m ⌋ k=\left\lceil \frac{k\cdot m}{m} \right\rceil =\left\lceil \frac{k\cdot m-r}{m} \right\rceil = \left\lceil \frac{k\cdot m-r+1}{m} \right\rceil = 1+ \left\lfloor \frac{k\cdot m-r}{m} \right\rfloor k = ⌈ m k ⋅ m ⌉ = ⌈ m k ⋅ m − r ⌉ = ⌈ m k ⋅ m − r + 1 ⌉ = 1 + ⌊ m k ⋅ m − r ⌋ k ⋅ m − r + 1 ∈ R k\cdot m-r+1 \in R k ⋅ m − r + 1 ∈ R n n n ⌈ n m ⌉ = 1 + ⌊ n − 1 m ⌋ \left\lceil \frac{n}{m} \right\rceil =1+ \left\lfloor \frac{n-1}{m} \right\rfloor ⌈ m n ⌉ = 1 + ⌊ m n − 1 ⌋
⌊ n m ⌋ = ⌈ n + 1 m ⌉ − 1
\left\lfloor \frac{n}{m} \right\rfloor =\left\lceil \frac{n+1}{m} \right\rceil-1
⌊ m n ⌋ = ⌈ m n + 1 ⌉ − 1 灵神恒等式*
⌊ ⌊ n / p ⌋ q ⌋ = ⌊ n p q ⌋
\left\lfloor\frac{\lfloor n/p\rfloor}q\right\rfloor =\left\lfloor\frac n{pq}\right\rfloor
⌊ q ⌊ n / p ⌋ ⌋ = ⌊ pq n ⌋ 1553. 吃掉 N 个橘子的最少天数 - 力扣(LeetCode)
实际上这个结论可以推广到任意个数,比如:
⌊ ⌊ ⌊ n p 1 ⌋ p 2 ⌋ p 3 ⌋ = ⌊ n p 1 ⋅ p 2 ⋅ p 3 ⌋
\left\lfloor\frac{\left\lfloor\frac{\left\lfloor\frac n{p_1}\right\rfloor}{p_2}\right\rfloor}{p_3}\right\rfloor =\left\lfloor\frac n{p_1\cdot p_2\cdot p_3}\right\rfloor
p 3 ⌊ p 2 ⌊ p 1 n ⌋ ⌋ = ⌊ p 1 ⋅ p 2 ⋅ p 3 n ⌋ 题目详情 - 数字游戏 - HydroOJ
不等式
x − 1 < ⌊ x ⌋ ⩽ x ⩽ ⌈ x ⌉ < x + 1
x-1 <\lfloor x\rfloor\leqslant x\leqslant\lceil x\rceil < x+1
x − 1 < ⌊ x ⌋ ⩽ x ⩽ ⌈ x ⌉ < x + 1 取余性质
n m o d m = n − m ⋅ ⌊ n m ⌋
n \bmod m = n - m \cdot \left\lfloor \frac{n}{m}\right\rfloor
n mod m = n − m ⋅ ⌊ m n ⌋ 幂等律
⌊ ⌊ x ⌋ ⌋ = ⌊ x ⌋ ⌈ ⌈ x ⌉ ⌉ = ⌈ x ⌉
\big\lfloor \left\lfloor x \right\rfloor \big\rfloor = \left\lfloor x \right\rfloor \\
\big\lceil \left\lceil x \right\rceil \big\rceil = \left\lceil x \right\rceil
⌊ ⌊ x ⌋ ⌋ = ⌊ x ⌋ ⌈ ⌈ x ⌉ ⌉ = ⌈ x ⌉ 素数
素数计数函数近似值
小于等于 x x x π ( x ) \pi(x) π ( x ) π ( x ) 近似于 x ln x \pi (x) 近似于 \frac{x}{\ln x} π ( x ) 近似于 l n x x
(1). 埃氏筛 时间复杂度:O ( n l o g l o g n ) O(nloglogn) O ( n l o g l o g n )
primes = []
is_prime = [ True ] * ( n + 1 ) # MX 为最大可能遇到的质数 + 1
is_prime [ 1 ] = is_prime [ 0 ] = False
for i in range ( 2 , int ( math . sqrt ( n )) + 1 ): # i * i <= n
if is_prime [ i ]:
for j in range ( i * i , n + 1 , i ):
is_prime [ j ] = False
for i in range ( 2 , n + 1 ):
if is_prime [ i ]: primes . append ( i )
时间复杂度证明
对于 2,要在数组中筛大约 n 2 \frac{n}{2} 2 n p p p p n \frac{p}{n} n p
故有 O ( ∑ k = 1 π ( n ) n p k ) = O ( n ∑ k = 1 π ( n ) 1 p k ) = O ( n l o g l o g n ) (Mertens 第二定理)
\text{故有 } O\left(\sum_{k = 1}^{\pi(n)}\frac{n}{p_k} \right) = O\left(n \sum_{k = 1}^{\pi(n)} \frac{1}{p_k}\right)
= O(nloglogn) \space \text{ (Mertens 第二定理)}
故有 O k = 1 ∑ π ( n ) p k n = O n k = 1 ∑ π ( n ) p k 1 = O ( n l o g l o g n ) (Mertens 第二定理 ) 切片优化
primes = []
is_prime = [ True ] * ( n + 1 )
is_prime [ 0 ] = is_prime [ 1 ] = False
for i in range ( 2 , int ( math . sqrt ( n )) + 1 ):
if is_prime [ i ]:
is_prime [ i * i :: i ] = [ False ] * (( n - i * i ) // i + 1 )
for i in range ( 2 , n + 1 ):
if is_prime [ i ]: primes . append ( i )
(2). 欧拉筛 / 线性筛 基本思想:每一个合数一定存在最小的质因子。确保每一个合数只被他的最小质因子筛去。
primes = []
is_prime = [ True ] * ( n + 1 )
is_prime [ 0 ] = is_prime [ 1 ] = False
for i in range ( 2 , n + 1 ):
if is_prime [ i ]: primes . append ( i )
for p in primes :
if i * p > n : break
is_prime [ i * p ] = False
if i % p == 0 : break
正确性证明:
每个合数不会被筛超过一次:
枚举 i i i i % p = 0 i \% p = 0 i % p = 0 p p p i i i p ⋅ i p \cdot i p ⋅ i i i i p p p i ⋅ p i \cdot p i ⋅ p i % p = 0 i \% p =0 i % p = 0 p p p i i i
每个合数都会被筛最少一次:
每个合数 x x x p p p x / p x / p x / p i i i x / p x / p x / p x x x
由于保证每个合数一定被晒一次,所以是 O ( n ) O(n) O ( n )
(3). 分解质因子
所谓质因子分解是将一个正整数 n n n
试除法。复杂度不超过 O ( n ) O(\sqrt n ) O ( n ) O ( l o g n ) ∼ O ( n ) O(logn) \sim O(\sqrt {n}) O ( l o g n ) ∼ O ( n )
对于一个数 x,最多有一个大于等于 n \sqrt n n
所以只需要进行特判,在遍历完 [ 2 , i n t ( n ) ] [2, int(\sqrt n)] [ 2 , in t ( n )]
from math import *
def solve ( x ):
for i in range ( 2 , int ( sqrt ( x )) + 1 ): # i = 2; i * i <= x
if x % i == 0 :
s = 0
while x % i == 0 :
s += 1
x //= i
print ( f ' { i } { s } ' ) # i 是质因子, s 表示幂次
if x > 1 :
print ( f ' { x } 1' )
print ()
solve ( 2 ** 3 * 3 ** 4 * 5 ** 2 * 7 * 14 )
Oi Wiki 风格:统计质因子及其出现次数
from math import *
# 统计质因子及其出现次数
def breakdown ( x ):
res = []
for i in range ( 2 , int ( sqrt ( x )) + 1 ):
if x % i == 0 :
cnt = 0
while x % i == 0 :
x //= i
cnt += 1
res . append (( i , cnt ))
if x > 1 : res . append (( x , 1 ))
return res
print ( breakdown ( 2 ** 3 * 3 ** 4 * 5 ** 2 * 7 * 14 )) # [(2, 4), (3, 4), (5, 2), (7, 2)]
1.质因数个数 - 蓝桥云课 (lanqiao.cn)
from math import *
# 统计质因子及其出现次数
def breakdown ( x ):
res = set ()
for i in range ( 2 , int ( sqrt ( x )) + 1 ):
if x % i == 0 :
cnt = 0
while x % i == 0 :
x //= i
cnt += 1
res . add ( i )
if x > 1 : res . add ( x )
return res
print ( len ( breakdown ( int ( input ()))))
(4). 乘分解质因子
求 n ! n! n ! p p p
例如 9 ! 9! 9 ! 2 2 2 9 ! 9! 9 ! 2 , 4 , 6 , 8 2,4,6,8 2 , 4 , 6 , 8 1 , 2 , 1 , 3 1,2,1,3 1 , 2 , 1 , 3 2 2 2 7 7 7
n ! n! n ! p p p [ 1 , n ] [1,n] [ 1 , n ] p p p p p p n / / p n // p n // p p p p p p p n / / p n//p n // p n ′ ← n / / p n' \leftarrow n//p n ′ ← n // p [ 1 , n ′ [1,n' [ 1 , n ′ p p p p p p n ′ / / p n' // p n ′ // p n = 0 n=0 n = 0
# 统计 n! 中质因子 p 出现的次数
def fpf ( n , p ): # factorial_prime_factor
res = 0
while n :
res += n // p
n //= p
return res
求 n ! n! n ! b b b
例如:( 9 ! ) 10 = ( 720 ) 10 = ( 880 ) 9 = 8 × 9 2 + 8 × 9 1 + 0 × 1 = 3 4 × 2 3 + 2 3 × 3 2 = 3 2 × 2 4 × 5 (9!)_{10}=(720)_{10}=(880)_{9} = 8 \times 9^2 + 8 \times 9^1+0\times 1=3^4\times 2^3+2^3 \times 3^2=3^2\times 2^4\times 5 ( 9 ! ) 10 = ( 720 ) 10 = ( 880 ) 9 = 8 × 9 2 + 8 × 9 1 + 0 × 1 = 3 4 × 2 3 + 2 3 × 3 2 = 3 2 × 2 4 × 5
5 ! = ( 120 ) 10 = 1111000 2 = 2 3 × 3 1 × 5 1 5!=(120)_{10}=1111000_{2}=2^3\times 3^1\times5^1 5 ! = ( 120 ) 10 = 111100 0 2 = 2 3 × 3 1 × 5 1
x x x b b b x = ∑ d i b i x = \sum d_i b^{i} x = ∑ d i b i k k k d k × b k d_k\times b^k d k × b k x x x b k × ( ∑ d i × b i − k ) b^k \times (\sum d_i\times b^{i-k}) b k × ( ∑ d i × b i − k ) x x x x = p 0 k 0 × p 1 k 1 ⋯ x=p_0^{k_0} \times p_1^{k_1}\cdots x = p 0 k 0 × p 1 k 1 ⋯ b b b p 0 k 0 ′ × ⋯ p_0^{k'_0} \times \cdots p 0 k 0 ′ × ⋯ b b b n ! n! n !
n ! = p 0 k 0 × p 1 k 1 ⋯ = b k × ( ∑ d i × b i − k ) = ( p 0 k 0 ′ × p 1 k 1 ′ × . . . ) k × ( ∑ d i × b i − k ) = ( p 0 k 0 ′ ⋅ k × p 1 k 1 ′ ⋅ k × . . . ) × ( ∑ d i × b i − k )
\begin{aligned}
n! &= p_0^{k_0} \times p_1^{k_1}\cdots\\
&=b^k \times (\sum d_i \times b^{i-k})\\
&=(p_0 ^{k^{'}_0} \times p_1 ^{k^{'}_1} \times...)^k \times (\sum d_i \times b^{i-k}) \\
&= (p_0 ^{k^{'}_{0} \cdot k } \times p_1 ^{k^{'}_{1} \cdot k} \times...) \times (\sum d_i \times b^{i-k})
\end{aligned}
n ! = p 0 k 0 × p 1 k 1 ⋯ = b k × ( ∑ d i × b i − k ) = ( p 0 k 0 ′ × p 1 k 1 ′ × ... ) k × ( ∑ d i × b i − k ) = ( p 0 k 0 ′ ⋅ k × p 1 k 1 ′ ⋅ k × ... ) × ( ∑ d i × b i − k ) 即, p 0 k 0 × p 1 k 1 ⋯ = ( p 0 k 0 ′ ⋅ k × p 1 k 1 ′ ⋅ k × . . . ) × ( ∑ d i × b i − k ) p_0^{k_0} \times p_1^{k_1}\cdots = (p_0 ^{k^{'}_{0} \cdot k } \times p_1 ^{k^{'}_{1} \cdot k} \times...) \times (\sum d_i \times b^{i-k}) p 0 k 0 × p 1 k 1 ⋯ = ( p 0 k 0 ′ ⋅ k × p 1 k 1 ′ ⋅ k × ... ) × ( ∑ d i × b i − k )
由于 k i = k i ′ ⋅ k k_i = k^{'}_{i} \cdot k k i = k i ′ ⋅ k k k k k k k min k i k i ′ \min \frac{k_i}{k_i'} min k i ′ k i k i k_i k i b b b n ! n! n !
Problem - C - Codeforces
import sys
input = lambda : sys . stdin . readline () . strip ()
from math import *
# 统计 n! 中质因子 p 出现的次数
def fpf ( n , p ): # factorial_prime_factor
res = 0
while n :
res += n // p
n //= p
return res
# 统计质因子及其出现次数
def breakdown ( n ):
res = []
for i in range ( 2 , int ( sqrt ( n )) + 1 ):
if n % i == 0 :
cnt = 0
while n % i == 0 :
n //= i
cnt += 1
res . append (( i , cnt ))
if n > 1 : res . append (( n , 1 ))
return res
def solve ():
n , b = map ( int , input () . split ())
pf = breakdown ( b ) # 对 b 进行质因子分解
res = inf
for f , c in pf :
res = min ( res , fpf ( n , f ) // c )
return res
print ( solve ())
阶乘合并
1.阶乘的和 - 蓝桥云课 (lanqiao.cn)
A i ! A_i! A i ! A 1 ! + A 2 ! + . . . + A n ! A_1! + A_2! + ... + A_n! A 1 ! + A 2 ! + ... + A n ! A 1 < A 2 < . . . < A n A_1 < A_2 < ... < A_n A 1 < A 2 < ... < A n A 1 ! A_1! A 1 !
使用计数器 m m m x ! x! x ! c = m [ x ] c = m[x] c = m [ x ] c = k × ( x + 1 ) c = k \times (x + 1) c = k × ( x + 1 ) k k k ( x + 1 ) ! (x + 1)! ( x + 1 )!
即合并条件为 c c % (x + 1) == 0 c m [ x + 1 ] ← m [ x + 1 ] + c / / ( x + 1 ) m[x + 1] ← m[x + 1] + c // (x + 1) m [ x + 1 ] ← m [ x + 1 ] + c // ( x + 1 )
从 A 1 A_1 A 1 A 1 ! + A 2 ! + . . . + A n ! A_1! + A_2! + ... + A_n! A 1 ! + A 2 ! + ... + A n ! B 1 ! + B 2 ! + . . . + B m ! B_1! + B_2! + ... + B_m! B 1 ! + B 2 ! + ... + B m ! B 1 B_1 B 1
# Ai!的累加结果,A1! + A2! + ... + An!,
# 对排序后的A1 < A2 < ... < An,由公因式提取可知,则A1!为最大公因数
# 使用计数器m存储 x!出现次数。
# 考虑阶乘的合并情况:考察x!的个数c = m[x],若有c = k * (x + 1),则能合并为 k 个 (x + 1)!。
# 即合并条件为 c % (x + 1) == 0,合并操作为 m[x + 1] ← m[x + 1] + c // (x + 1)
# 从A1开始合并,当无法合并时,相当于将A1! + A2! + ... + An!转换成 B1! + B2! + ... + Bm!,返回B1即可
from collections import Counter
n = int ( input ())
a = list ( map ( int , input () . split ()))
a . sort ()
m = Counter ()
for x in a :
m [ x ] += 1
x = a [ 0 ]
while True :
c = m [ x ] # x! 的个数
if c % ( x + 1 ) == 0 : # x!的个数是x+1的倍数
m [ x + 1 ] += c // ( x + 1 ) # c = k * (x + 1)
x += 1
else :
print ( x )
break
约数
试除法求所有约数 复杂度为:O ( n ) O(\sqrt{n}) O ( n )
from math import *
def solve ( x ):
res = []
for i in range ( 2 , int ( sqrt ( x )) + 1 ):
if x % i == 0 :
res . append ( i )
if i != x // i :
res . append ( x // i )
return res
print ( solve ( 24 )) # [2, 12, 3, 8, 4, 6]
5.约数个数 - 蓝桥云课 (lanqiao.cn)
from math import *
def solve ( x ):
res = []
for i in range ( 2 , int ( sqrt ( x )) + 1 ):
if x % i == 0 :
res . append ( i )
if i != x // i :
res . append ( x // i )
return len ( res ) + 2 # 1 和 自身
print ( solve ( 1200000 )) # 96
乘积数的约数个数
对于一个以标准分解式给出的数 N = ∏ i = 1 k p i α i N = \prod_{i = 1}^k p_i^{\alpha_i} N = ∏ i = 1 k p i α i ∏ i = 1 k ( α i + 1 ) \prod_{i = 1} ^k (\alpha_i + 1) ∏ i = 1 k ( α i + 1 )
例如 N = 2 5 ⋅ 3 1 , 约数个数为 ( 5 + 1 ) × ( 1 + 1 ) = 12 N = 2^5 \cdot 3^1, 约数个数为(5 + 1) \times (1 + 1) = 12 N = 2 5 ⋅ 3 1 , 约数个数为 ( 5 + 1 ) × ( 1 + 1 ) = 12
乘积数的所有约数之和
对于一个以标准分解式给出的数 N = ∏ i = 1 k p i α i N = \prod_{i = 1}^k p_i^{\alpha_i} N = ∏ i = 1 k p i α i ∏ i = 1 k ( ∑ j = 0 α i p i j ) \prod_{i = 1} ^k (\sum_{j = 0}^{\alpha_i} p_i^j) ∏ i = 1 k ( ∑ j = 0 α i p i j )
例如 N = 2 5 ⋅ 3 1 , 约数个数为 ( 2 0 + 2 1 + ⋯ + 2 5 ) × ( 3 0 + 3 1 ) N = 2^5 \cdot 3^1, 约数个数为 (2^0 + 2^1 + \cdots + 2^5) \times (3^0 + 3^1) N = 2 5 ⋅ 3 1 , 约数个数为 ( 2 0 + 2 1 + ⋯ + 2 5 ) × ( 3 0 + 3 1 )
871. 约数之和 - AcWing 题库
from collections import Counter
from math import *
moder = 10 ** 9 + 7
res = 1
t = int ( input ())
cnt = Counter ()
for _ in range ( t ):
x = int ( input ())
for i in range ( 2 , int ( sqrt ( x )) + 1 ):
if x % i == 0 :
c = 0
while x % i == 0 :
c += 1
x //= i
cnt [ i ] += c
if x > 1 : cnt [ x ] += 1
def S ( a , n ):
s0 = 1
for _ in range ( n ):
s0 = ( a * s0 + 1 ) % moder
return s0
for a , n in cnt . items ():
res = ( res * S ( a , n )) % moder
print ( res % moder )
约数筛 / 约数预处理
求 [ 1 : m x ] [1:mx] [ 1 : m x ] 从小到大排列 )。
时间复杂度: O ( n n ) O(n \sqrt n) O ( n n )
# mx = 10 ** 5 + 1
factors = [[] for _ in range ( mx )]
for f in range ( 1 , mx ):
for x in range ( f , mx , f ):
factors [ x ] . append ( f )
欧拉函数
定义:ϕ ( n ) \phi(n) ϕ ( n ) 1 ∼ n 1 \sim n 1 ∼ n n n n
时间复杂度:O ( n ) O(\sqrt n) O ( n )
对于一个以标准分解式给出的数 N = ∏ i = 1 k p i α i N = \prod_{i = 1}^k p_i^{\alpha_i} N = ∏ i = 1 k p i α i
ϕ ( N ) = N ⋅ ∏ i = 1 k ( 1 − 1 p i )
\phi(N) = N \cdot \prod_{i = 1}^{k} \left( 1 - \frac{1}{p_i} \right)
ϕ ( N ) = N ⋅ i = 1 ∏ k ( 1 − p i 1 ) 证明方法:容斥原理。
减去 p 1 , p 2 , ⋯ , p k p_1, p_2, \cdots, p_k p 1 , p 2 , ⋯ , p k p 1 p_1 p 1 p 2 p_2 p 2
N − ∑ i = 1 k N p i
N - \sum_{i = 1}^{k} \frac{N}{p_i}
N − i = 1 ∑ k p i N 加上所有 p i ⋅ p j p_i \cdot p_j p i ⋅ p j
N − ∑ i = 1 k N p i + ∑ i , j ∈ [ 0 , k ] 且 i < j N p i ⋅ p j
N - \sum_{i = 1}^{k} \frac{N}{p_i} + \sum_{i, j \in [0, k] 且 i < j} \frac{N}{p_i \cdot p_j}
N − i = 1 ∑ k p i N + i , j ∈ [ 0 , k ] 且 i < j ∑ p i ⋅ p j N 减去所有 p i ⋅ p j ⋅ p u p_i \cdot p_j \cdot p_u p i ⋅ p j ⋅ p u
N − ∑ i = 1 k N p i + ∑ i , j ∈ [ 0 , k ] 且 i < j N p i ⋅ p j − ∑ i , j , u ∈ [ 0 , k ] 且 i < j < u N p i ⋅ p j ⋅ p u + ⋯ = N ⋅ ∏ i = 1 k ( 1 − 1 p i )
N - \sum_{i = 1}^{k} \frac{N}{p_i} + \sum_{i, j \in [0, k] \text{ 且 } i < j} \frac{N}{p_i \cdot p_j} - \sum_{i, j, u \in [0, k] \text{ 且 } i < j < u} \frac{N}{p_i \cdot p_j \cdot p_u} + \cdots = N \cdot \prod_{i = 1}^{k} \left( 1 - \frac{1}{p_i} \right)
N − i = 1 ∑ k p i N + i , j ∈ [ 0 , k ] 且 i < j ∑ p i ⋅ p j N − i , j , u ∈ [ 0 , k ] 且 i < j < u ∑ p i ⋅ p j ⋅ p u N + ⋯ = N ⋅ i = 1 ∏ k ( 1 − p i 1 ) 最后一步,可以通过观察系数的角度来证明。例如 1 p i \frac{1}{p_i} p i 1
证明方法二:
ϕ ( N ) = ϕ ( ∏ i = 1 k p i a i ) = ∏ i = 1 k ϕ ( p i a i ) = ∏ i = 1 k p i k ( 1 − 1 p i ) = N ⋅ ∏ i = 1 k ( 1 − 1 p i )
\phi(N) = \phi(\prod_{i = 1} ^ k p_i ^ {a_i}) = \prod_{i = 1} ^ {k} \phi(p_i^{a_i}) = \prod_{i = 1}^{k} p_i^{k}(1 - \frac{1}{p_i}) = N \cdot \prod_{i = 1}^{k} (1 - \frac{1}{p_i})
ϕ ( N ) = ϕ ( i = 1 ∏ k p i a i ) = i = 1 ∏ k ϕ ( p i a i ) = i = 1 ∏ k p i k ( 1 − p i 1 ) = N ⋅ i = 1 ∏ k ( 1 − p i 1 ) 性质:
积性函数:对于互质的 p , q p, q p , q ϕ ( p × q ) = ϕ ( p ) × ϕ ( q ) \phi(p \times q) = \phi(p) \times \phi(q) ϕ ( p × q ) = ϕ ( p ) × ϕ ( q ) p p p ϕ ( 2 p ) = ϕ ( p ) \phi(2p) = \phi(p) ϕ ( 2 p ) = ϕ ( p )
证明:互质的数,质因子分解的集合无交集。ϕ ( 2 ) = 1 \phi(2) = 1 ϕ ( 2 ) = 1
对于质数 p p p ϕ ( p k ) = p k − p k p = p k − p k − 1 \phi(p^k) = p^k - \frac{p^k}{p} = p^k - p^{k -1} ϕ ( p k ) = p k − p p k = p k − p k − 1
证明:减去是 p p p p p p
def solve ( n ):
res = n
for i in range ( 2 , int ( sqrt ( n )) + 1 ):
if n % i == 0 :
res = res * ( i - 1 ) // i
while n % i == 0 : 7
n //= i
if n > 1 :
res = res * ( n - 1 ) // n
return res
1. 筛法求欧拉函数
对于 N N N p 1 p_1 p 1 N ′ = N p 1 N' = \frac{N}{p_1} N ′ = p 1 N N N N N ′ ⋅ p 1 N' \cdot p_1 N ′ ⋅ p 1
考虑两种情况:
N ′ m o d p 1 = 0 N' \bmod p_1 = 0 N ′ mod p 1 = 0 N ′ N' N ′ N N N
ϕ ( N ) = N × ∏ i = 1 k ( 1 − 1 p i ) = N ′ ⋅ p 1 × ∏ i = 1 k ( 1 − 1 p i ) = p i × ϕ ( N ′ )
\phi(N) = N \times \prod_{i = 1}^{k} (1 - \frac{1}{p_i}) = N' \cdot p_1 \times \prod_{i = 1}^{k} (1 - \frac{1}{p_i}) = p_i \times \phi(N')
ϕ ( N ) = N × i = 1 ∏ k ( 1 − p i 1 ) = N ′ ⋅ p 1 × i = 1 ∏ k ( 1 − p i 1 ) = p i × ϕ ( N ′ )
N ′ m o d p i ≠ 0 N' \bmod p_i \ne 0 N ′ mod p i = 0 N ′ N' N ′ p 1 p_1 p 1
由欧拉函数的积性性质,互质的数质因子分解无交集:
ϕ ( N ) = ϕ ( N ′ × p 1 ) = ϕ ( N ′ ) × ϕ ( p 1 ) = ϕ ( N ′ ) × ( p i − 1 )
\phi (N) = \phi(N' \times p_1) = \phi(N') \times \phi(p_1) = \phi(N') \times (p_i - 1)
ϕ ( N ) = ϕ ( N ′ × p 1 ) = ϕ ( N ′ ) × ϕ ( p 1 ) = ϕ ( N ′ ) × ( p i − 1 ) 在筛质数的同时筛出欧拉函数。
primes = []
is_prime = [ True ] * ( n + 1 )
phi = [ 0 ] * ( n + 1 )
phi [ 1 ] = 1
for i in range ( 2 , n + 1 ):
if is_prime [ i ]:
phi [ i ] = i - 1
primes . append ( i )
for p in primes :
if p * i > n : break
is_prime [ i * p ] = False
if i % p == 0 :
phi [ i * p ] = p * phi [ i ]
break
phi [ i * p ] = ( p - 1 ) * phi [ i ]
2. 欧拉定理
若 a 与 n 互质,则 a ϕ ( n ) m o d n = 1
若 a 与 n 互质,则 a^{\phi(n)} \bmod n ~ = 1
若 a 与 n 互质,则 a ϕ ( n ) mod n = 1
例如:5 ϕ ( 6 ) m o d 6 = 5 2 m o d 6 = 25 m o d 6 = 1 5^ {\phi(6)} \bmod 6=5^2 \bmod 6=25 \bmod 6=1 5 ϕ ( 6 ) mod 6 = 5 2 mod 6 = 25 mod 6 = 1
证明:考察 1 ∼ n 1\sim n 1 ∼ n n n n ϕ ( n ) \phi(n) ϕ ( n ) p 1 , p 2 , ⋯ , p ϕ ( n ) p_1, ~p_2,~\cdots,~p_{\phi(n)} p 1 , p 2 , ⋯ , p ϕ ( n ) a a a n n n a p 1 m o d n , a p 2 m o d n , ⋯ , a p ϕ ( n ) m o d n ap_1 \bmod n, ~~ap_2 \bmod n,\cdots,~~ap_{\phi(n)} \bmod n a p 1 mod n , a p 2 mod n , ⋯ , a p ϕ ( n ) mod n
可以证明这一组数两两不相同(反证法,若 a p i ≡ a p j ( m o d n ) ap_i \equiv ap_j(\bmod n) a p i ≡ a p j ( mod n ) a p i − a p j ≡ 0 ( m o d n ) ap_i - ap_j \equiv 0(\bmod n) a p i − a p j ≡ 0 ( mod n ) a , n a,~n a , n p i = p j p_i = p_j p i = p j n n n a a a p i p_i p i n n n
则可以得到,新的这组数集 和 原先与 n n n p 1 ⋅ p 2 ⋯ p ϕ ( n ) m o d n = ∏ a p i m o d n p_1 \cdot p_2 \cdots p_{\phi(n)} \bmod n = \prod a p_i \bmod n p 1 ⋅ p 2 ⋯ p ϕ ( n ) mod n = ∏ a p i mod n
a ϕ ( n ) ≡ 1 ( m o d n )
a^{\phi(n)} \equiv 1~~ (\bmod~ n)
a ϕ ( n ) ≡ 1 ( mod n ) 3.费马小定理
若 a a a p p p a p − 1 ≡ 1 ( m o d p ) a^{p-1} \equiv 1 (\bmod ~ p) a p − 1 ≡ 1 ( mod p )
裴蜀定理
对正整数 a , b a,b a , b d = g c d ( a , b ) d=gcd(a,b) d = g c d ( a , b )
对于任意 x , y x,y x , y a x + b y = D , D ax+by=D,~D a x + b y = D , D d d d d ∣ ( a x + b y ) d|(ax+by) d ∣ ( a x + b y )
一定存在 x , y x,y x , y a x + b y = d ax+by=d a x + b y = d x , y x,y x , y 12 x + 8 y = 4 12x+8y = 4 12 x + 8 y = 4
推论:g c d ( a , b ) = d ⟺ gcd(a,b )=d \iff g c d ( a , b ) = d ⟺ x , y 使得 a x + b y = d x,y 使得 ax +by=d x , y 使得 a x + b y = d
a , b a,b a , b ⟺ \iff ⟺ x , y x,y x , y a x + b y = 1 ax+by=1 a x + b y = 1
推广:对于任意 n n n a 1 , a 2 , ⋯ , a n a1,a2,\cdots , a_n a 1 , a 2 , ⋯ , a n d = g c d ( a 1 , ⋯ , a n ) d=gcd(a1, \cdots, a_n) d = g c d ( a 1 , ⋯ , a n )
一定存在 x 1 , ⋯ , x n x1, \cdots, x_n x 1 , ⋯ , x n ∑ a i x i = d \sum a_i x_i = d ∑ a i x i = d \(\sum a_i x_i = k , , , 一定是 d d d
g c d ( a 1 , ⋯ , a n ) = d ⟺ gcd(a1, \cdots, a_n) = d \iff g c d ( a 1 , ⋯ , a n ) = d ⟺ x 1 , c … , x n x_1, c\dots, x_n x 1 , c … , x n ∑ a i x i = d \sum a_i x_i = d ∑ a i x i = d
1250. 检查「好数组」 - 力扣(LeetCode)
判断是否能从原给定集合中,选出子集 A = { a 1 , ⋯ , a n } A=\{a1, \cdots,a_n\} A = { a 1 , ⋯ , a n } X = { x 1 , ⋯ , x n } X=\{x1, \cdots,x_n\} X = { x 1 , ⋯ , x n } A X = 1 AX=1 A X = 1 g c d gcd g c d g c d gcd g c d X = { x 1 , ⋯ , x n } X=\{x1, \cdots,x_n\} X = { x 1 , ⋯ , x n } A X = 1 AX=1 A X = 1
def isGoodArray ( self , nums : List [ int ]) -> bool :
res_gcd = nums [ 0 ]
for x in nums :
res_gcd = gcd ( res_gcd , x )
return res_gcd == 1
1625. 执行操作后字典序最小的字符串 - 力扣(LeetCode)
暴力枚举需要 O ( n C + n C ) O(nC+nC) O ( n C + n C ) b b b C = 10 C=10 C = 10 C = 10 2 C=10^2 C = 1 0 2
对于任意起点 i ′ = ( i × b ) m o d n = i b − k n i'=(i\times b) \bmod n = ib - kn i ′ = ( i × b ) mod n = ib − kn \(\sum a_i x_i = k , , , 一定是 d d d i ′ = K × g c d ( b , n ) i'=K \times gcd(b,n) i ′ = K × g c d ( b , n ) g c d ( a , b ) gcd(a,b) g c d ( a , b ) O ( n C + n g c d ( a , b ) × C ) O(nC + \frac{n}{gcd(a,b) }\times C) O ( n C + g c d ( a , b ) n × C ) b b b C = 10 C=10 C = 10 C = 10 2 C=10^2 C = 1 0 2
def findLexSmallestString ( self , s : str , a : int , b : int ) -> str :
res = s
n = len ( s )
s = s + s
s_str = set ()
e_lim = 10 if b & 1 else 1 # b 为奇数才可以对偶数位置增加
for o_cnt in range ( 10 ): # 对奇数位置增加 a 的次数
for e_cnt in range ( e_lim ):
tmp = list ( map ( int , s ))
for i in range ( 1 , 2 * n , 2 ): tmp [ i ] = ( tmp [ i ] + a * o_cnt ) % 10
for i in range ( 0 , 2 * n , 2 ): tmp [ i ] = ( tmp [ i ] + a * e_cnt ) % 10
s_str . add ( '' . join ( map ( str , tmp )))
def _gcd ( a , b ):
return _gcd ( b , a % b ) if b else a
g = _gcd ( n , b )
for i in range ( 0 , n , g ): # 裴蜀定理优化
for ss in s_str :
tmp = ss [ i : i + n ]
if tmp < res : res = tmp
return res
欧几里得算法 算法原理:g c d ( a , b ) = g c d ( b , a m o d b ) gcd(a, b) = gcd(b,a\bmod b) g c d ( a , b ) = g c d ( b , a mod b )
证明:
对于任意一个能整除 a a a d d d a m o d b a \bmod b a mod b a − k ⋅ b a - k \cdot b a − k ⋅ b k = a / / b k = a // b k = a // b d d d b , a m o d b b, a \bmod b b , a mod b
对于任意一个能整除 b b b a − k ⋅ b a - k \cdot b a − k ⋅ b d d d a − k ⋅ b + k ⋅ b = a a-k\cdot b + k\cdot b = a a − k ⋅ b + k ⋅ b = a
所以二者的最大公约数等价
def gcd ( a , b ):
return gcd ( b , a % b ) if b else a
时间复杂度:O ( log ( max ( a , b ) ) ) O(\log (\max(a,~b))) O ( log ( max ( a , b )))
证明:
引理 1: a m o d b ∈ [ 0 , b − 1 ] a\bmod b \in[0,~ b-1] a mod b ∈ [ 0 , b − 1 ] 38 m o d 13 = 12 38 \bmod 13 = 12 38 mod 13 = 12
引理 2:取模,余数至少折半。
如果 b > a / / 2 , a m o d b = a − b < a / / 2 b > a//2,~a \bmod ~b = a - b < a//2 b > a //2 , a mod b = a − b < a //2
如果 b ≤ a / / 2 , a m o d b ≤ b − 1 ≤ a / / 2 − 1 b \le a//2, ~ a \bmod b \le b - 1 \le a//2 -1 b ≤ a //2 , a mod b ≤ b − 1 ≤ a //2 − 1
情况 1:当每次执行 gcd 时,如果 a < b a < b a < b a ≥ b a \ge b a ≥ b a a a a a a a a a
O ( T ) = O ( T / 2 ) + 2 = O ( T / 4 ) + 4 = O ( T 2 k ) + k × 2 = 2 log k O(T) = O(T /2) + 2 = O(T/4) + 4 = O(\frac {T}{2^k}) + k\times2 = 2\log k O ( T ) = O ( T /2 ) + 2 = O ( T /4 ) + 4 = O ( 2 k T ) + k × 2 = 2 log k O ( log ( max ( a , b ) ) ) O(\log(\max(a, b))) O ( log ( max ( a , b )))
扩展欧几里得
877. 扩展欧几里得算法 - AcWing 题库
求解 a x + b y = g c d ( a , b ) ax+by=gcd(a,b) a x + b y = g c d ( a , b )
当 b = 0 b=0 b = 0 ( x , y ) = ( 1 , 0 ) (x,y)=(1,0) ( x , y ) = ( 1 , 0 ) g c d ( a , b ) = g c d ( b , a m o d b ) gcd(a,b)=gcd(b, a \bmod b) g c d ( a , b ) = g c d ( b , a mod b ) ( x ′ , y ′ ) (x',y') ( x ′ , y ′ ) b x ′ + ( a % b ) y ′ = b x ′ + ( a − a / / b × b ) y ′ = a x + b y bx'+(a \%b)y'=bx'+(a-a//b \times b)y'=ax+by b x ′ + ( a % b ) y ′ = b x ′ + ( a − a // b × b ) y ′ = a x + b y a ( y ′ ) + b ( x ′ − a / / b × y ′ ) = a x + b y a(y')+b(x'-a//b \times y') = ax+by a ( y ′ ) + b ( x ′ − a // b × y ′ ) = a x + b y ( y ′ , x ′ − a / / b × y ′ ) (y', x'-a//b \times y') ( y ′ , x ′ − a // b × y ′ ) 特解 ( x 0 , y 0 ) (x_0, y_0) ( x 0 , y 0 ) 。构造通解:( x 0 + k × b g c d ( a , b ) , y 0 − k × a g c d ( a , b ) ) (x_0+k\times \frac{b}{gcd(a,b)},~y_0-k\times \frac{a}{gcd(a,b)}) ( x 0 + k × g c d ( a , b ) b , y 0 − k × g c d ( a , b ) a )
def exgcd ( a , b ):
if b == 0 : return 1 , 0 , a
x , y , d = exgcd ( b , a % b )
return y , x - a // b * y , d
线性同余方程
878. 线性同余方程 - AcWing 题库
线性同余方程
给定 a , b , m ( a m o d m ≠ 0 ) a,b, m(a\bmod m \ne0) a , b , m ( a mod m = 0 ) x x x a x ≡ b ( m o d m ) ax \equiv b (\bmod m) a x ≡ b ( mod m )
求方程 a x + m y = b ax+my=b a x + m y = b
无解条件:b m o d g c d ( a , m ) ≠ 0 b\bmod gcd(a,m) \ne 0 b mod g c d ( a , m ) = 0
例如 2 x ≡ 3 ( m o d 6 ) 2x \equiv 3 (\bmod 6) 2 x ≡ 3 ( mod 6 ) 4 x ≡ 3 ( m o d 5 ) 4x \equiv 3 (\bmod 5) 4 x ≡ 3 ( mod 5 ) 5 k + 2 5k+2 5 k + 2
转换为 存在整数 y y y \(ax = m(-y) +b (,即 a x + m y = b ax+my=b a x + m y = b b b b g c d ( a , m ) gcd(a, m) g c d ( a , m ) ( x 0 , y 0 ) (x_0, y_0) ( x 0 , y 0 ) a x 0 + m y 0 = g c d ( a , m ) ax_0 + my_0 =gcd(a,m) a x 0 + m y 0 = g c d ( a , m ) g c d ( a , m ) gcd(a,m) g c d ( a , m ) b b b ( x 0 ′ = x 0 × b g c d , y 0 ′ = y 0 × b g c d ) (x_0'=x_0 \times \frac {b}{gcd},~ y_0'= y_0 \times \frac{b}{gcd}) ( x 0 ′ = x 0 × g c d b , y 0 ′ = y 0 × g c d b ) (x'_0+k\times \frac{m}{gcd},~y'_0-k\times \frac{a}{gcd})\) ,则通解 x ′ m o d m g c d = x 0 ′ x' \bmod \frac{m}{gcd} = x'_0 x ′ mod g c d m = x 0 ′ x m = x 0 × b g c d m o d m g c d , y m = y 0 × b g c d m o d a g c d x_m = x_0 \times \frac{b}{gcd} \bmod \frac{m}{gcd},~~y_m=y_0\times \frac{b}{gcd} \bmod \frac{a}{gcd} x m = x 0 × g c d b mod g c d m , y m = y 0 × g c d b mod g c d a
def exgcd ( a , b ):
if b == 0 : return 1 , 0 , a
x , y , d = exgcd ( b , a % b )
return y , x - a // b * y , d
# 求 ax + by = c 的特解
def liEu ( a , b , c ):
x , y , d = exgcd ( a , b )
if c % d != 0 : return None
# x0 + k * (b // d)
# y0 - k * (a // d)
return x * ( c // d ) % ( b // d ), y * ( c // d ) % ( a // d )
同余
两个整数 a a a b b b m m m a a a b b b m m m a a a b b b m m m a a a b b b m m m
同余性质
a ≡ b ( m o d m ) ⇒ { a n ≡ b n ( m o d m ) , ∀ n ∈ Z a n ≡ b n ( m o d m ) , ∀ n ∈ N 0 .
a\equiv b\quad(\mathrm{mod~}m)\Rightarrow\begin{cases}an\equiv bn&\mathrm{(mod~}m),\forall n\in\mathbb{Z}\\a^n\equiv b^n&\mathrm{(mod~}m),\forall n\in\mathbb{N}^0&\end{cases}.
a ≡ b ( mod m ) ⇒ { an ≡ bn a n ≡ b n ( mod m ) , ∀ n ∈ Z ( mod m ) , ∀ n ∈ N 0 .
除法原理:若 k a ≡ k b ( m o d m ) ka\equiv kb\quad({\mathrm{mod}}\quad m) ka ≡ kb ( mod m ) k , m k,m k , m a ≡ b ( m o d m ) a\equiv b\quad({\mathrm{mod}}\quad m) a ≡ b ( mod m )
乘法逆元
快速幂求逆元
条件: 1. 模数 b b b a m o d b ≠ 0 a \bmod b \ne0 a mod b = 0
a a a b b b a b − 2 m o d b a^{b-2} \bmod b a b − 2 mod b
876. 快速幂求逆元 - AcWing 题库
def qmi ( a , n , p ):
res = 1
while n :
if n & 1 : res = res * a % p
a = a * a % p
n >>= 1
return res
def inv ( a , b ): # 确保 b 是素数且 a % b != 0
return qmi ( a , b - 2 , b )
扩展欧几里得求逆元
条件:1. g c d ( a , b ) = 1 gcd(a,b)=1 g c d ( a , b ) = 1 a m o d b ≠ 0 a \bmod b \ne0 a mod b = 0
求 a a a b b b
求线性同余方程 a x ≡ 1 ( m o d b ) ax\equiv1 (\bmod b) a x ≡ 1 ( mod b ) a − 1 a^{-1} a − 1
转化为方程 a x + b y = 1 ax+by=1 a x + b y = 1 x x x O ( l o g ( m i n ( a , b ) ) ) O(log(min(a, b))) O ( l o g ( min ( a , b )))
def exgcd ( a , b ):
if b == 0 : return 1 , 0 , a
x , y , d = exgcd ( b , a % b )
return y , x - a // b * y , d
# 求 ax + by = c 的特解
def liEu ( a , b , c ):
x , y , d = exgcd ( a , b )
if c % d != 0 : return None
return x * ( c // d ) % ( b // d ), y * ( c // d ) % ( a // d )
def inv ( a , b ):
# ax mod b = 1
# ax + by = 1
x , y = liEu ( a , b , 1 )
return x
线性求逆元
P3811 【模板】模意义下的乘法逆元 - 洛谷 | 计算机科学教育新生态 (luogu.com.cn)
求 1 , 2 , ⋯ , n 1,2, \cdots, n 1 , 2 , ⋯ , n p p p
已知 1 × 1 ≡ 1 ( m o d b ) 1\times 1\equiv1(\bmod b) 1 × 1 ≡ 1 ( mod b ) i i i i − 1 i^{-1} i − 1 p p p i i i k = ⌊ p i ⌋ k = \lfloor \frac{p}{i} \rfloor k = ⌊ i p ⌋ j = p m o d i j=p \bmod i j = p mod i p = k i + j p=ki+j p = ki + j p p p k i + j ≡ 0 ( m o d p ) ki+j \equiv0 (\bmod p) ki + j ≡ 0 ( mod p ) i − 1 × j − 1 i^{-1} \times j ^{-1} i − 1 × j − 1 k j − 1 + i − 1 ≡ 0 ( m o d p ) kj^{-1} + i^{-1} \equiv 0(\bmod p) k j − 1 + i − 1 ≡ 0 ( mod p ) i − 1 ≡ − k j − 1 ( m o d p ) ≡ − ⌊ p i ⌋ ( p m o d i ) − 1 ( m o d p ) i^{-1} \equiv-kj^{-1} (\bmod p) \equiv - \lfloor \frac{p}{i} \rfloor (p \bmod i)^{-1} (\bmod p) i − 1 ≡ − k j − 1 ( mod p ) ≡ − ⌊ i p ⌋ ( p mod i ) − 1 ( mod p )
递推式:
inv [ i ] = { 1 , if i = 1 − ( p / / i ) × inv [ p % i ] , otherwise ( m o d p )
\text{inv}[i] =
\begin{cases}
1, & \text{if} ~i = 1
\\
-(p //i) \times \text{inv}[p \%i],&\text{otherwise}
\end{cases}
~(\bmod p)
inv [ i ] = { 1 , − ( p // i ) × inv [ p % i ] , if i = 1 otherwise ( mod p ) inv = [ 1 ] * ( n + 1 )
for i in range ( 2 , n + 1 ):
k , j = ( p // i ), p % i
inv [ i ] = - k * inv [ j ] % p
逆元解决除法取模
如果 b b b p p p ∀ a , \forall ~a, ∀ a , a / b a /b a / b x x x a b ≡ a ⋅ x ( m o d p ) \frac{a}{b} \equiv a \cdot x (mod~p) b a ≡ a ⋅ x ( m o d p ) x x x b b b b − 1 b^{-1} b − 1 b b b p p p b b b b b b p p p
逆元性质
b ⋅ b − 1 ≡ 1 ( m o d p ) b \cdot b^{-1} \equiv1(mod~p) b ⋅ b − 1 ≡ 1 ( m o d p ) b b b a ≡ a ⋅ b − 1 ⋅ b ( m o d p ) a\equiv a\cdot b ^{-1} \cdot b (mod ~p) a ≡ a ⋅ b − 1 ⋅ b ( m o d p ) a a a b b b b b b p p p a a a p p p 当模数 p p p b m o d p − 1 = b p − 2 b^{-1}_{\bmod p} =b^{p-2} b mod p − 1 = b p − 2 p p p b p − 1 ≡ 1 ( m o d p ) b^{p-1}\equiv1(mod~p) b p − 1 ≡ 1 ( m o d p ) b b b x x x b x ≡ 1 ( m o d p ) bx \equiv 1(mod~p) b x ≡ 1 ( m o d p ) b − 1 = x = b p − 2 b^{-1} =x=b^{p-2} b − 1 = x = b p − 2
中国剩余定理
条件:整数 m 1 , m 2 , … , m n m_1,m_2,\ldots,m_n m 1 , m 2 , … , m n 两两互质
引理:寻找整数 y 1 y_1 y 1 y 1 y_1 y 1 3 3 3 1 1 1 5 5 5 0 0 0 7 7 7 0 0 0
y 1 y_1 y 1 5 × 7 = 35 5 \times 7 = 35 5 × 7 = 35 y 1 = 35 k y_1 = 35k y 1 = 35 k 35 k ≡ 1 ( m o d 3 ) 35k \equiv 1 (\bmod 3) 35 k ≡ 1 ( mod 3 ) k k k 35 35 35 3 3 3
对于任意的整数 a 1 , a 2 , … , a n a_1,a_2,\ldots,a_n a 1 , a 2 , … , a n
{ x ≡ a 1 ( m o d m 1 ) x ≡ a 2 ( m o d m 2 ) ⋯ x ≡ a n ( m o d m n )
\begin{cases}
x \equiv a_1(\bmod m_1) \\
x \equiv a_2(\bmod m_2) \\
\cdots \\
x \equiv a_n(\bmod m_n) \\
\end{cases}
⎩ ⎨ ⎧ x ≡ a 1 ( mod m 1 ) x ≡ a 2 ( mod m 2 ) ⋯ x ≡ a n ( mod m n ) 的最小非负整数解:
x ≡ ∑ i = 1 n a i × M m i × inv ( M m i , m i ) ( m o d N ) ,其中 M = ∏ i = 1 n m i
x \equiv \sum_{i = 1}^na_i
\times\frac M{m_i}
\times \text{inv}(\frac{M}{m_i},~m_i)\pmod{N},
其中 M =\prod_{i = 1}^nm_i
x ≡ i = 1 ∑ n a i × m i M × inv ( m i M , m i ) ( mod N ) ,其中 M = i = 1 ∏ n m i 记:
c i = M m i , x = ∑ a i c i ⋅ inv ( c i , m i )
c_i =\frac{M}{m_i}, x =\sum a_ic_i \cdot \text{inv}(c_i,~m_i)
c i = m i M , x = ∑ a i c i ⋅ inv ( c i , m i ) P1495 【模板】中国剩余定理(CRT)/ 曹冲养猪 - 洛谷 | 计算机科学教育新生态 (luogu.com.cn)
def exgcd ( a , b ):
if b == 0 : return 1 , 0 , a
x , y , d = exgcd ( b , a % b )
return y , x - a // b * y , d
def liEu ( a , b , c ):
# ax + by = c 的解
x , y , d = exgcd ( a , b )
a //= d
b //= d
c //= d
return x * c % b , y * c % a
def inv ( a , b ):
x , _ = liEu ( a , b , 1 )
return x
def CRT ( a , m ):
M = 1
res = 0
for mi in m : M *= mi
for ai , mi in zip ( a , m ):
ci = M // mi
res = ( res + ai * ci * inv ( ci , mi )) % M
return res
扩展中国剩余定理
204. 表达整数的奇怪方式 - AcWing 题库
P4777 【模板】扩展中国剩余定理(EXCRT) - 洛谷 | 计算机科学教育新生态 (luogu.com.cn)
删去条件 m i m_i m i
前两个方程:x ≡ a 1 ( m o d m 1 ) , x ≡ a 2 ( m o d m 2 ) x\equiv a_1(\bmod m_1),x\equiv a_2(\bmod m_2) x ≡ a 1 ( mod m 1 ) , x ≡ a 2 ( mod m 2 ) x = p m 1 + a 1 = q m 2 + a 2 x=pm_1 +a_1=qm_2+a_2 x = p m 1 + a 1 = q m 2 + a 2 p m 1 − q m 2 = a 2 − a 1 pm_1-qm_2=a_2-a_1 p m 1 − q m 2 = a 2 − a 1 a 2 − a 1 a_2-a_1 a 2 − a 1 g c d ( m 1 , m 2 ) gcd(m_1,m_2) g c d ( m 1 , m 2 ) g c d gcd g c d ( p 0 , q 0 ) (p_0,q_0) ( p 0 , q 0 ) ( P = p 0 × a 2 − a 1 g c d ( m 1 , m 2 ) m o d m 2 g c d ( m 1 , m 2 ) + k m 2 g c d ( m 1 , m 2 ) , Q = q 0 × a 2 − a 1 g c d ( m 1 , m 2 ) m o d m 1 g c d ( m 1 , m 2 ) − k m 1 g c d ( m 1 , m 2 ) ) (P=p_0 \times\frac{a_2-a_1}{gcd(m_1, m_2)} \bmod \frac{m_2}{gcd(m_1, m_2)}+ k\frac{m_2}{gcd(m_1, m_2)},~~~~Q=q_0\times \frac{a_2-a_1}{gcd(m_1,m_2)} \bmod \frac{m_1}{gcd(m_1, m_2)} - k\frac{m_1}{gcd(m_1, m_2)}) ( P = p 0 × g c d ( m 1 , m 2 ) a 2 − a 1 mod g c d ( m 1 , m 2 ) m 2 + k g c d ( m 1 , m 2 ) m 2 , Q = q 0 × g c d ( m 1 , m 2 ) a 2 − a 1 mod g c d ( m 1 , m 2 ) m 1 − k g c d ( m 1 , m 2 ) m 1 )
代入有 x = P m 1 + a 1 = p 0 ′ m 1 + a 1 + k × m 1 m 2 g c d ( m 1 , m 2 ) = p 0 ′ m 1 + a 1 + k ⋅ lcm ( m 1 , m 2 ) x=Pm_1+a_1=p'_0m_1+a_1+k\times \frac{m_1m_2}{gcd(m_1,m_2)}=p_0'm_1+a_1+k \cdot \text{lcm}(m_1, m_2) x = P m 1 + a 1 = p 0 ′ m 1 + a 1 + k × g c d ( m 1 , m 2 ) m 1 m 2 = p 0 ′ m 1 + a 1 + k ⋅ lcm ( m 1 , m 2 ) x ≡ a 1 ′ ( m o d m 1 ′ ) , a 1 ′ = p 0 ′ m 1 + a 1 , m 1 ′ = lcm ( m 1 , m 2 ) x\equiv a_1' (\bmod m_1'),a_1'=p_0'm_1+a_1,m'_1=\text{lcm}(m_1,m_2) x ≡ a 1 ′ ( mod m 1 ′ ) , a 1 ′ = p 0 ′ m 1 + a 1 , m 1 ′ = lcm ( m 1 , m 2 ) n − 1 n-1 n − 1
每一次将 m 1 ← a b s ( m 1 m 2 g c d ( m 1 , m 2 ) ) , a 1 ← p 0 ′ m 1 + a 1 m_1 \leftarrow abs(\frac{m_1m_2}{gcd(m_1,m_2)}),~a_1 \leftarrow p'_0m_1 + a1 m 1 ← ab s ( g c d ( m 1 , m 2 ) m 1 m 2 ) , a 1 ← p 0 ′ m 1 + a 1
def exgcd ( a , b ):
if b == 0 : return 1 , 0 , a
x , y , d = exgcd ( b , a % b )
return y , x - a // b * y , d
def liEu ( a , b , c ):
x , y , g = exgcd ( a , b )
a , b , c = a // g , b // g , c // g
return x * c % b , y * c % a , g
def ex_CRT ( a , m ):
a1 , m1 = a [ 0 ], m [ 0 ]
for i in range ( 1 , len ( a )):
a2 , m2 = a [ i ], m [ i ]
# 构造 p * m1 + a1 = q * m2 + a2
p , q , g = liEu ( m1 , - m2 , a2 - a1 )
if ( a2 - a1 ) % g != 0 : return - 1
a1 = p * m1 + a1
m1 = abs ( m1 * m2 // g )
return a1
[P8807 蓝桥杯 2022 国 C] 取模 - 洛谷 | 计算机科学教育新生态 (luogu.com.cn)
给定 n , m n,m n , m x , y x,y x , y 1 ≤ x < y ≤ m 1\leq x<y\leq m 1 ≤ x < y ≤ m n m o d x = n m o d y n\bmod x=n\bmod y n mod x = n mod y
考虑反面情况,当且仅当对于任意 [ 1 , m ] [1,m] [ 1 , m ] x x x n m o d x n \bmod x n mod x n n n n m o d 1 = 0 n \bmod 1=0 n mod 1 = 0 n m o d 2 n \bmod 2 n mod 2 n m o d 3 n \bmod 3 n mod 3 n m o d k n \bmod k n mod k k − 1 k-1 k − 1 ∀ k ∈ [ 1 , m ] 有 n m o d k = k − 1 \forall k \in [1, m] 有 n \bmod k =k-1 ∀ k ∈ [ 1 , m ] 有 n mod k = k − 1
def solve ():
n , m = map ( int , input () . split ())
for k in range ( 1 , m + 1 ):
if n % k != k - 1 :
return 'Yes'
return 'No'
由扩展中国剩余定理,m 1 = 1 , a 1 = 0 m_1 = 1, a_1=0 m 1 = 1 , a 1 = 0 m 1 ← a b s ( m 1 m 2 g c d ( m 1 , m 2 ) ) , a 1 ← p 0 ′ m 1 + a 1 m_1 \leftarrow abs(\frac{m_1m_2}{gcd(m_1,m_2)}),~a_1 \leftarrow p'_0m_1 + a1 m 1 ← ab s ( g c d ( m 1 , m 2 ) m 1 m 2 ) , a 1 ← p 0 ′ m 1 + a 1 m 1 = l c m ( 1 , 2 , ⋯ , m ) m_1 = lcm(1,2,\cdots,m) m 1 = l c m ( 1 , 2 , ⋯ , m ) a 1 = − 1 a_1 = -1 a 1 = − 1 x ≡ − 1 ( m o d m 1 ) x\equiv -1(\bmod m_1) x ≡ − 1 ( mod m 1 ) n m o d L = − 1 即 L − 1 n \bmod L=-1 即L-1 n mod L = − 1 即 L − 1 m m m L L L n n n n m o d L = n < L − 1 n \bmod L = n < L-1 n mod L = n < L − 1
def gcd ( a , b ):
return gcd ( b , a % b ) if b else a
def lcm ( a , b ):
return a * b // gcd ( a , b )
Lcm = [ 1 ] * 21
for i in range ( 2 , 21 ):
Lcm [ i ] = lcm ( i , Lcm [ i - 1 ])
def solve ():
n , m = map ( int , input () . split ())
if m > 20 : return 'Yes'
L = Lcm [ m ]
if n % L == L - 1 : return 'No'
return 'Yes'
离散数学
容斥
2652. 倍数求和 - 力扣(LeetCode)
给你一个正整数 n ,请你计算在 [1,n] 范围内能被 3或者5或者7 整除的所有整数之和。
返回一个整数,用于表示给定范围内所有满足约束条件的数字之和。
利用等差数列求和公式:1 ∼ n 中能被 x 整除的数之和 = ( x + 2 ⋅ x + ⋯ + n / / x ⋅ x ) = x ⋅ ( 1 + n / / x ) ∗ ( n / / x ) / / 2 1 \sim n 中 能被 x 整除的数之和 = (x + 2\cdot x+ \cdots + n//x \cdot x) = x \cdot(1 + n // x) * (n // x) // 2 1 ∼ n 中能被 x 整除的数之和 = ( x + 2 ⋅ x + ⋯ + n // x ⋅ x ) = x ⋅ ( 1 + n // x ) ∗ ( n // x ) //2
因而,
class Solution :
def sumOfMultiples ( self , n : int ) -> int :
# 定义 f(x) 为能被 x 整除的数字之和
def f ( x ):
return x * ( 1 + n // x ) * ( n // x ) // 2
return f ( 3 ) + f ( 5 ) + f ( 7 ) - f ( 15 ) - f ( 21 ) - f ( 35 ) + f ( 105 )
3116. 单面值组合的第 K 小金额 - 力扣(LeetCode)
容斥 + 预处理最小公倍数:给定无重复集合 c o i n s ′ coins' co in s ′ 1 ∼ x 1 \sim x 1 ∼ x c o i n s ′ coins' co in s ′ c h e c k ( x ) check(x) c h ec k ( x )
将问题转换成,恰好能有 不少于 k k k c o i n s ′ coins' co in s ′ x x x c o i n s ′ coins' co in s ′ l l l d i c [ l ] dic[l] d i c [ l ] y y y 1 ∼ x 1 \sim x 1 ∼ x i n t ( x / y ) int(x/y) in t ( x / y )
def findKthSmallest ( self , coins : List [ int ], k : int ) -> int :
coins . sort ()
if coins [ 0 ] == 1 : return k
c = set ( coins )
n = len ( coins )
for i in range ( n ):
for j in range ( i + 1 , n ):
x , y = coins [ i ], coins [ j ]
if y % x == 0 and y in c :
n -= 1
c . remove ( y )
coins = list ( c )
# 预处理:dic [i] 表示 从 coins 中选出 i 个数的子集的最小公倍数
dic = defaultdict ( list )
dic [ 1 ] = coins
# 回溯枚举子集
path = []
def dfs ( i ):
l = len ( path )
if i == n :
if l >= 2 :
lcm_ = path [ 0 ]
for j in range ( 1 , l ):
lcm_ = lcm ( lcm_ , path [ j ])
dic [ l ] . append ( lcm_ )
return
dfs ( i + 1 )
path . append ( coins [ i ])
dfs ( i + 1 )
path . pop ()
dfs ( 0 )
def check ( x ):
# 检查 1 ~ x 中,能被任意一个 c 整除的个数 res 和 k 的关系
res = 0
for l in range ( 1 , n + 1 ):
plus = l & 1
for d in dic [ l ]:
res = res + ( 1 if plus else - 1 ) * ( x // d )
return res >= k
lo , hi = 0 , 5 * 10 ** 10 + 10
while lo < hi :
mid = ( lo + hi ) >> 1
if check ( mid ):
hi = mid
else :
lo = mid + 1
return lo
鸽巢原理 / 抽屉原理
常用于求解最坏情况下的解,以及证明不存在解(连最坏情况下,都不存在解,则所有情况不存在解)。
鸽巢原理定理
有 n + 1 n+1 n + 1 n n n n n n n + 1 n+1 n + 1 n n n
推广:将 n n n k k k ⌈ n k ⌉ \left\lceil \frac{n}{k} \right\rceil ⌈ k n ⌉ ⌈ n k ⌉ \left\lceil \frac{n}{k} \right\rceil ⌈ k n ⌉ ( ⌈ n k ⌉ − 1 ) × k < ( n k ) × k = n (\left\lceil \frac{n}{k} \right\rceil - 1) \times k < (\frac{n}{k}) \times k=n ( ⌈ k n ⌉ − 1 ) × k < ( k n ) × k = n
例如,53 个物体,分成 6 组,最坏情况下是 9,9,9,9,9,8。
简单应用:
任意 11 个整数中,至少有 2 个整数之差是 10 的倍数。(证明,从余数角度来看,11 个数对 10 的余数有 11 个,一共有 10 种余数 0 ~ 9,至少有两个数对 10 同余,故其差也对 10 同余)
一个人骑车 10 小时内走完了 281 公里路程,已知他第一小时走了 30 公里,最后一小时走了 17 公里。证明:他一定在某相继的两小时中至少走完了 58 公里路程。(证明:8 小时走了 234 公里,234 个物品分到 8 组,最坏情况下,至少有一组是 ⌈ 234 8 ⌉ = 29 \lceil \frac{234}{8} \rceil=29 ⌈ 8 234 ⌉ = 29 28 28 28
Ramsey 定理 / 拉姆齐定理
任意 n n n ⌈ ( n − 1 ) / 2 ⌉ \lceil (n-1)/2 \rceil ⌈( n − 1 ) /2 ⌉ k 1 k1 k 1 k 2 k2 k 2 ⌈ ( n − 1 ) / 2 ⌉ \lceil (n-1)/2 \rceil ⌈( n − 1 ) /2 ⌉
隔板法
Problem - 1205 (hdu.edu.cn)
Gardon 有 1 ≤ K ≤ 10 6 1\leq K\leq10^6 1 ≤ K ≤ 1 0 6 i i i 1 ≤ a i ≤ 10 6 1\leq a_i\leq10^6 1 ≤ a i ≤ 1 0 6
即给定 K K K a i a_i a i
找到最大个数的数量 N N N S S S N − 1 N-1 N − 1 S ≥ N − 1 S \ge N-1 S ≥ N − 1
数学公式
排序不等式
结论:对于两个有序数组的乘积和,顺序和 ≥ \ge ≥ ≥ \ge ≥
对于 a 1 ≤ a 2 ≤ ⋯ ≤ a n , b 1 ≤ b 2 ≤ ⋯ ≤ b n a_1 \le a_2 \le \cdots \le a_n,b_1 \le b_2 \le \cdots \le b_n a 1 ≤ a 2 ≤ ⋯ ≤ a n , b 1 ≤ b 2 ≤ ⋯ ≤ b n c 1 , c 2 , ⋯ , c n c1,c2,\cdots, c_n c 1 , c 2 , ⋯ , c n b 1 , b 2 , ⋯ , b n b1, b2, \cdots , b_n b 1 , b 2 , ⋯ , b n
∑ i = 1 n a i b n + 1 − i ≤ ∑ i = 1 n a i c i ≤ ∑ i = 1 n a i b i 。
\sum_{i = 1}^{n}a_ib_{n + 1 - i} \le \sum_{i = 1}^{n}a_ic_i\le \sum_{i = 1}^{n}a_ib_i。\\
i = 1 ∑ n a i b n + 1 − i ≤ i = 1 ∑ n a i c i ≤ i = 1 ∑ n a i b i 。 当且仅当 a i = a j a_i = a_j a i = a j b i = b j ( 1 ≤ i , j ≤ n ) b_i = b_j \space (1 \le i, j\le n) b i = b j ( 1 ≤ i , j ≤ n )
区间递增 k 个数
结论:对于 i 0 = a i_0 = a i 0 = a k k k [ a , b ) [a, b) [ a , b )
( b − a − 1 ) / / k + 1
(b - a - 1) // k + 1
( b − a − 1 ) // k + 1 平均数不等式
x 1 , x 2 , … , x n ∈ R + ⇒ n ∑ i = 1 n 1 x i ≤ ∏ i = 1 n x i n ≤ ∑ i = 1 n x i n ≤ ∑ i = 1 n x i 2 n 当且仅当 x 1 = x 2 = ⋯ = x n , 等号成立。
x_1, x_2,\ldots, x_n\in\mathbb{R}_+\Rightarrow\frac n{\sum_{i = 1}^n\frac1{x_i}}
\leq\sqrt [n]{\prod_{i = 1}^nx_i}
\leq\frac{\sum_{i = 1}^nx_i}n
\leq\sqrt{\frac{\sum_{i = 1}^nx_i^2}n}
\\
\text{当且仅当 }x_1 = x_2 =\cdots = x_n\text{, 等号成立。}
x 1 , x 2 , … , x n ∈ R + ⇒ ∑ i = 1 n x i 1 n ≤ n i = 1 ∏ n x i ≤ n ∑ i = 1 n x i ≤ n ∑ i = 1 n x i 2 当且仅当 x 1 = x 2 = ⋯ = x n , 等号成立。 即:调和平均数 ,几何平均数,算术平均数,平方平均数 (调几算方)
应用:
例如当算术平均数为定值,x i x_i x i
3081. 替换字符串中的问号使分数最小 - 力扣(LeetCode)
各个字母之间的出现次数的差异越小,越均衡,最终结果越小。可以基于贪心 + 堆进行维护,每次取出出现次数最小中字典序最小的字符。
def minimizeStringValue ( self , s : str ) -> str :
cnt = Counter ( s )
hq = [( cnt [ ch ], ch ) for ch in string . ascii_lowercase ]
heapq . heapify ( hq )
alp = []
res = list ( s )
for i in range ( s . count ( '?' )):
v , k = heappop ( hq )
v += 1
alp . append ( k )
heappush ( hq , ( v , k ))
alp . sort ( reverse = True )
for i , x in enumerate ( res ):
if res [ i ] == '?' :
res [ i ] = alp . pop ()
return '' . join ( res )
求和公式
Σ 1 n n 2 = n ⋅ ( n + 1 ) ⋅ ( 2 n + 1 ) 6
\Sigma_1^nn^2 = \frac{n \cdot (n + 1) \cdot (2n + 1)}{6}
Σ 1 n n 2 = 6 n ⋅ ( n + 1 ) ⋅ ( 2 n + 1 ) 取模性质
模运算与基本四则运算有些相似,但是除法例外。其规则如下:
(a + b) % p = (a % p + b % p) % p
(a - b) % p = (a % p - b % p) % p
(a * b) % p = (a % p * b % p) % p
a ^ b % p = ((a % p)^b) % p
结合律:
((a+b) % p + c) % p = (a + (b+c) % p) % p
((a b) % p * c)% p = (a * (b c) % p) % p
交换律:
(a + b) % p = (b+a) % p
(a * b) % p = (b * a) % p
分配律:
(a+b) % p = ( a % p + b % p ) % p
((a +b)% p * c) % p = ((a * c) % p + (b * c) % p) % p
数列
等比数列求和公式
S n = a 1 ( 1 − q n ) 1 − q , q ≠ 1
S_n = \frac{a_1(1-q^n)}{1-q},~q \ne1
S n = 1 − q a 1 ( 1 − q n ) , q = 1 递推方法求等比数列求和(带模运算)
希望求:S ( a , n ) m o d p = ( a 0 + a 1 + ⋯ + a n ) m o d p S(a,n) \bmod p=(a^0+a^1+\cdots+a^n) \bmod p S ( a , n ) mod p = ( a 0 + a 1 + ⋯ + a n ) mod p S ( a , n ) = a ⋅ ( S ( a , n − 1 ) ) + 1 S(a,n)=a\cdot \big(S(a,n-1) \big) + 1 S ( a , n ) = a ⋅ ( S ( a , n − 1 ) ) + 1
时间复杂度:O ( n ) O(n) O ( n )
def S ( a , n ):
s0 = 1
for _ in range ( n ):
s0 = ( a * s0 + 1 ) % moder
return s0
组合数学
排列
A m n = m ! n ! A_m^n = \frac{m!}{n!} A m n = n ! m !
A n m = n A n − 1 m − 1 \mathrm{A}_n^m=n\mathrm{A}_{n-1}^{m-1} A n m = n A n − 1 m − 1
递推公式:可理解为“某特定位置”先安排,再安排其余位置。
@lru_cache ( None )
def A ( n , m ):
if m == 0 : return 1
return n * A ( n - 1 , m - 1 )
组合数学
C m n = m ! n ! ( m − n ) ! ~ C_m^n = \frac{m!}{n!(m-n)!} C m n = n ! ( m − n )! m !
C m n = C m m − n C_m^n = C_m^{m-n} C m n = C m m − n
递推公式:
C m n = C m − 1 n + C m − 1 n − 1 C_m^n = C_{m -1}^n + C_{m-1}^{n-1} C m n = C m − 1 n + C m − 1 n − 1
@lru_cache ( None )
def C ( n , m ):
if m == 0 or n == m : return 1
return C ( n - 1 , m - 1 ) + C ( n - 1 , m )
C n 0 + C n 1 + ⋯ + C n n = 2 n C_n^0+C_n^1 + \cdots+ C_n^n = 2 ^ n C n 0 + C n 1 + ⋯ + C n n = 2 n
62. 不同路径 - 力扣(LeetCode)
路径方案数 = C ( n + m − 2 , m − 1 ) = C(n+m-2,m-1) = C ( n + m − 2 , m − 1 )
@lru_cache ( None )
def C ( n , m ):
if m == 0 or n == m : return 1
return C ( n - 1 , m - 1 ) + C ( n - 1 , m )
class Solution :
def uniquePaths ( self , m : int , n : int ) -> int :
m , n = m - 1 , n - 1
return C ( m + n , m )
二项式定理
( a + b ) n = ∑ i = 0 n C n i a i b n − i
(a + b) ^n = \sum_{i = 0}^n C_n^ia^ib^{n-i}
( a + b ) n = i = 0 ∑ n C n i a i b n − i 卡特兰数
5. 卡特兰数(Catalan)公式、证明、代码、典例._c n = n+11 ( n2n )-CSDN 博客
给定 n 个 0 和 n 个 1 ,排序成长度为 2 n 的序列。其中任意前缀中 0 的个数都不少于 1 的个数的序列的数量为: H ( n ) = C 2 n n − C 2 n n − 1 = C 2 n n n + 1 = ( 2 n ) ! ( n + 1 ) ! n !
给定 ~n ~ 个 0 和 ~n~ 个 1,排序成长度为 2n 的序列。其中任意前缀中 0 的个数都不少于 1 的个数的序列的数量为:
\\
H(n) = C_{2n}^n-C_{2n}^{n-1} = \frac{C_{2n}^n}{n+1} = \frac{(2n)!}{(n + 1)! n!}
给定 n 个 0 和 n 个 1 ,排序成长度为 2 n 的序列。其中任意前缀中 0 的个数都不少于 1 的个数的序列的数量为: H ( n ) = C 2 n n − C 2 n n − 1 = n + 1 C 2 n n = ( n + 1 )! n ! ( 2 n )!
证明方法:
看成从从 ( 0 , 0 ) (0,~ 0) ( 0 , 0 ) ( n , n ) (n, ~n ) ( n , n )
对于不合法的情况,超过 y = x y = x y = x y = x + 1 y = x + 1 y = x + 1 y = x + 1 y = x + 1 y = x + 1 y = x + 1 y = x + 1 y = x + 1 ( n , n ) (n,n) ( n , n ) y = x + 1 y = x + 1 y = x + 1 ( n − 1 , n + 1 ) (n - 1, n + 1) ( n − 1 , n + 1 ) C 2 n n − 1 C_{2n}^{n-1} C 2 n n − 1
递推公式 1:
H ( n + 1 ) = H ( 0 ) ⋅ H ( n ) + H ( 1 ) ⋅ H ( n − 1 ) + ⋯ + H ( n ) ⋅ H ( 0 ) = ∑ i = 0 n H ( i ) ⋅ H ( n − i )
H(n+1) = H(0)\cdot H(n) + H(1)\cdot H(n - 1) + \cdots +H(n)\cdot H(0) = \sum_{i = 0}^{n} H(i)\cdot H(n-i)
H ( n + 1 ) = H ( 0 ) ⋅ H ( n ) + H ( 1 ) ⋅ H ( n − 1 ) + ⋯ + H ( n ) ⋅ H ( 0 ) = i = 0 ∑ n H ( i ) ⋅ H ( n − i ) 证明方法:从 ( 0 , 0 ) (0, 0) ( 0 , 0 ) ( n + 1 , n + 1 ) (n +1, n+1) ( n + 1 , n + 1 )
首先从 ( 0 , 0 ) (0,0) ( 0 , 0 ) ( i , i ) (i,i) ( i , i ) H ( i ) H(i) H ( i ) ( i , i ) (i,i) ( i , i ) ( n , n ) (n,n) ( n , n ) H ( n − i ) H(n-i) H ( n − i ) ( n , n ) (n,n) ( n , n ) ( n + 1 , n + 1 ) (n + 1, n + 1) ( n + 1 , n + 1 ) H ( 1 ) H(1) H ( 1 )
递推公式 2:
H ( n ) = H ( n − 1 ) ⋅ 2 n ( 2 n − 1 ) ( n + 1 ) n = H ( n − 1 ) ⋅ ( 4 n − 2 ) ( n + 1 )
H(n) = H(n-1) \cdot \frac{2n(2n - 1)}{(n+1)n} = H(n-1) \cdot \frac{(4n - 2)}{(n+1)}
H ( n ) = H ( n − 1 ) ⋅ ( n + 1 ) n 2 n ( 2 n − 1 ) = H ( n − 1 ) ⋅ ( n + 1 ) ( 4 n − 2 ) 推论:
前几项: 1,1,2,5,14,42,132,429,1430
n n n F ( n ) F(n) F ( n ) F ( i ) , i ∈ [ 0 , n ] , F(i), i \in [0,n], F ( i ) , i ∈ [ 0 , n ] , F ( n − i ) , F(n-i), F ( n − i ) , 从 ( 0 , 0 ) (0,~ 0) ( 0 , 0 ) ( n , n ) (n, ~n ) ( n , n ) y = x y = x y = x
一个无穷大栈,进栈顺序为 1 , 2 , . . . , n 1, 2, ... , n 1 , 2 , ... , n
n n n n n n
凸多边形划分问题
在一个 n 边形中,通过不相交于 n 边形内部的对角线,把 n 边形拆分为若干个三角形,问有多少种拆分方案?
以凸多边形的一边为基,设这条边的 2 个顶点为 A 和 B。从剩余顶点中选 1 个,可以将凸多边形分成三个部分,中间是一个三角形,左右两边分别是两个凸多边形,然后求解左右两个凸多边形。
2.设问题的解 f(n),其中 n 表示顶点数,那么 f(n)= f(2)f(n-1)+f(3) f(n-2)+……+f(n-2)f(3)+f(n-1) f(2)。
其中,f(2)f(n-1)表示:三个相邻的顶点构成一个三角形,另外两个部分的顶点数分别为 2(一条直线两个点)和 n-1。
其中,f(3) f(n-2)表示:将凸多边形分为三个部分,左右两边分别是一个有 3 个顶点的三角形和一个有 n-2 个顶点的多边形。
3.设 f(2) = 1,那么 f(3) = 1, f(4) = 2, f(5) = 5。结合递推式,不难发现 f(n) 等于 H(n-2)。
快速幂
欧拉降幂 / 快速幂
def pow ( a , n , moder ):
res = 1
while n :
if n & 1 : res = ( res * a ) % moder
n >>= 1
a = ( a * a ) % moder
return res
矩阵乘法时间复杂度:O ( M 1 N 2 N 1 ) O(M_1N_2N_1) O ( M 1 N 2 N 1 )
矩阵乘法
moder = 10 ** 9 + 7
def mul ( a , b ):
m_a , n_a = len ( a ), len ( a [ 0 ])
m_b , n_b = len ( b ), len ( b [ 0 ])
c = n_a # 可以加一个 n_a 和 m_b 的判等
res = [[ 0 ] * n_b for _ in range ( m_a )]
for i in range ( m_a ):
for j in range ( n_b ):
tmp = 0
for k in range ( c ):
# tmp = (tmp + (a [i][k] * b [k][j]) % moder) % moder # 如果需要取模
tmp += a [ i ][ k ] * b [ k ][ j ]
res [ i ][ j ] = tmp
return res
矩阵快速幂
moder = 10 ** 9 + 7
def mul ( a , b ):
ma , na = len ( a ), len ( a [ 0 ])
mb , nb = len ( b ), len ( b [ 0 ])
# ma * nb
c = na
res = [[ 0 ] * nb for _ in range ( ma )]
for i in range ( ma ):
for j in range ( nb ):
tmp = 0
for k in range ( na ):
tmp = ( tmp + a [ i ][ k ] * b [ k ][ j ] % moder ) % moder
res [ i ][ j ] = tmp
return res
def mat_pow ( a , n ):
res = [[ 6 , 6 ]]
while n :
if n & 1 : res = mul ( res , a )
a = mul ( a , a )
n >>= 1
return res
1411. 给 N x 3 网格图涂色的方案数 - 力扣(LeetCode)
递推方程:f ( 0 ) = ( 6 , 6 ) , f ( i ) = ( f ( i − 1 , 0 ) × 2 + f ( i − 1 , 1 ) × 2 , f ( i − 1 , 0 ) × 2 + f ( i − 1 , 1 ) × 3 ) f(0)=(6, 6),~f(i)=(f(i-1,0) \times 2+f(i-1,1)\times 2,~~f(i-1,0) \times 2 + f(i-1,1)\times3) f ( 0 ) = ( 6 , 6 ) , f ( i ) = ( f ( i − 1 , 0 ) × 2 + f ( i − 1 , 1 ) × 2 , f ( i − 1 , 0 ) × 2 + f ( i − 1 , 1 ) × 3 )
即:
[ f ( n , 0 ) f ( n , 1 ) ] = [ 6 6 ] ⋅ [ 2 2 2 3 ] n − 1
\left[\begin{array}{c}
f(n,0) \\
f(n,1)
\end{array}\right]
=
\left[\begin{array}{c}
6 \\
6
\end{array}\right]
\cdot
\left[\begin{array}{c}
2 & 2 \\
2 & 3
\end{array}\right]^{n-1}
[ f ( n , 0 ) f ( n , 1 ) ] = [ 6 6 ] ⋅ [ 2 2 2 3 ] n − 1 moder = 10 ** 9 + 7
def mul ( a , b ):
ma , na = len ( a ), len ( a [ 0 ])
mb , nb = len ( b ), len ( b [ 0 ])
# ma * nb
c = na
res = [[ 0 ] * nb for _ in range ( ma )]
for i in range ( ma ):
for j in range ( nb ):
tmp = 0
for k in range ( na ):
tmp = ( tmp + a [ i ][ k ] * b [ k ][ j ] % moder ) % moder
res [ i ][ j ] = tmp
return res
def mat_pow ( a , n ):
res = [[ 6 , 6 ]]
while n :
if n & 1 : res = mul ( res , a )
a = mul ( a , a )
n >>= 1
return res
class Solution :
def numOfWays ( self , n : int ) -> int :
m = [[ 2 , 2 ],
[ 2 , 3 ]]
x = mat_pow ( m , n - 1 )
return sum ( x [ 0 ]) % moder
高等数学
调和级数
∑ i = 1 n 1 k 是调和级数,其发散率表示为 ∑ i = 1 n 1 k = ln n + C
\sum_{i = 1}^{n} \frac{1}{k} 是调和级数,其发散率表示为\sum_{i = 1}^{n} \frac{1}{k} = \ln n + C
i = 1 ∑ n k 1 是调和级数,其发散率表示为 i = 1 ∑ n k 1 = ln n + C 经典应用:求一个数的约数的个数期望值
考虑 1~n 所有的数的约数个数。
从筛法的角度来看,拥有约数 2 的所有的数,是 1 ~ n 中所有 2 的倍数,大约是 n // 2 个。
所以 1~n 所有的数的约数个数和 可以看成 所有的倍数的个数 = n / 1 + n / 2 + n / 3 + ⋯ + n / n = n ∑ i = 1 n 1 i = n ln n 。 n/1 + n / 2 + n /3 + \cdots + n / n = n \sum_{i=1}^n\frac{1}{i} = n \ln n。 n /1 + n /2 + n /3 + ⋯ + n / n = n ∑ i = 1 n i 1 = n ln n 。
所以 =,从期望角度来讲,一个数 n n n ln n \ln n ln n
泰勒展开式
f ( x ) = f ( x 0 ) + f ′ ( x 0 ) 1 ! ( x − x 0 ) + f ′ ′ ( x 0 ) 2 ! ( x − x 0 ) 2 + ⋯ + f ( n ) ( x 0 ) n ! ( x − x 0 ) n + R n
f(x)= f(x_0)+\frac{f'(x_0)}{1!}(x-x_0)+\frac{f''(x_0)}{2!}(x-x_0)^2+\cdots+\frac{f^{(n)}(x_0)}{n!}(x-x_0)^n+R_n
f ( x ) = f ( x 0 ) + 1 ! f ′ ( x 0 ) ( x − x 0 ) + 2 ! f ′′ ( x 0 ) ( x − x 0 ) 2 + ⋯ + n ! f ( n ) ( x 0 ) ( x − x 0 ) n + R n 麦克劳林公式:x 0 = 0 x_0 = 0 x 0 = 0
f ( x ) = ∑ k = 0 n f ( k ) ( 0 ) k ! ⋅ x k + o ( x n ) = f ( 0 ) + f ′ ( 0 ) 1 ! ⋅ x + f ′ ′ ( 0 ) 2 ! ⋅ x 2 + ⋯ + f ( n ) ( 0 ) n ! ⋅ x n + o ( x n )
f(x) = \sum_{k = 0}^{n} \frac{f^{(k)}(0)}{k!} \cdot x^k + o(x^n) = f(0) + \frac{f'(0)}{1!} \cdot x + \frac{f''(0)}{2!} \cdot x^2 + \cdots+\frac{f^{(n)}(0)}{n!} \cdot x^n + o(x^n)
f ( x ) = k = 0 ∑ n k ! f ( k ) ( 0 ) ⋅ x k + o ( x n ) = f ( 0 ) + 1 ! f ′ ( 0 ) ⋅ x + 2 ! f ′′ ( 0 ) ⋅ x 2 + ⋯ + n ! f ( n ) ( 0 ) ⋅ x n + o ( x n ) 常用展开:
e x = 1 + 1 1 ! ⋅ x + 1 2 ! ⋅ x 2 + ⋯ + 1 n ! ⋅ x n + o ( x n )
e^x = 1+\frac{1}{1!} \cdot x + \frac{1}{2!} \cdot x^2 + \cdots +\frac{1}{n!} \cdot x^n + o(x^n)
e x = 1 + 1 ! 1 ⋅ x + 2 ! 1 ⋅ x 2 + ⋯ + n ! 1 ⋅ x n + o ( x n ) 所以有:
e = 1 0 ! + 1 1 ! + 1 2 ! + ⋯ + 1 n !
e = \frac{1}{0!} + \frac{1}{1!} + \frac{1}{2!} + \cdots + \frac{1}{n!}
e = 0 ! 1 + 1 ! 1 + 2 ! 1 + ⋯ + n ! 1 Stirling 斯特林公式
描述阶乘的近似阶:
n ! = 2 π n ( n e ) n
n!=\sqrt{2\pi n}(\frac n{e})^{n}
n ! = 2 πn ( e n ) n 所以可以得到卡特兰数列的近似:
O ( C n ) ∼ O ( 4 n n 3 2 ⋅ π )
O(C_n) \sim O(\frac{4^n}{n^{\frac{3}{2}} \cdot\sqrt \pi})
O ( C n ) ∼ O ( n 2 3 ⋅ π 4 n ) 数据结构
堆 / 优先队列
库导入:from heapq import *
注意:python的heap,默认是小堆顶,即二叉堆堆顶元素小于左右孩子。
heappush(heap, item)
将 item 添加到 heap 中,并保持堆的不变性。
时间复杂度:O ( l o g n ) O(log n) O ( l o g n )
heappop(heap)
弹出并返回 heap 中的最小元素,并保持堆的不变性。
时间复杂度:O ( l o g n ) O(log n) O ( l o g n )
heap[0] 取堆顶元素,时间复杂度 O ( 1 ) O(1) O ( 1 )
from heapq import *
hq = []
heappush ( hq , 5 )
heappush ( hq , 9 )
heappush ( hq , 11 )
heappush ( hq , 12 )
heappush ( hq , 13 )
heappush ( hq , 15 )
print ( hq ) # 输出: [5, 9, 11, 12, 13, 15]
# 获取堆顶元素(最小),O(1)
print ( hq [ 0 ]) # 5
# 弹出堆顶元素(最小),O(logn)
heappop ( hq )
print ( hq ) # 输出 [9, 12, 11, 15, 13]
# 注意:python 中堆默认且只能是小顶堆
# 大顶堆,通过取反实现
nums = [ 15 , 13 , 9 , 5 , 11 , 12 ]
hq = []
for x in nums :
heappush ( hq , - x )
print ( hq ) # [-15, -13, -12, -5, -11, -9]
# 获取堆顶元素(最大)
print ( - hq [ 0 ]) # 15
# 弹出堆顶元素(最大),O(logn)
heappop ( hq )
print ( hq ) # [-13, -11, -12, -5, -9]
print ( - hq [ 0 ]) # 13
2530. 执行 K 次操作后的最大分数 - 力扣(LeetCode)
给你一个下标从 0 开始的整数数组 nums 和一个整数 k 。你的 起始分数 为 0 。
在一步 操作 中:
选出一个满足 0 <= i < nums.length 的下标 i ,
将你的 分数 增加 nums[i] ,并且
将 nums[i] 替换为 ceil(nums[i] / 3) 。
返回在 恰好 执行 k 次操作后,你可能获得的最大分数。
向上取整函数 ceil(val) 的结果是大于或等于 val 的最小整数。
示例 2:
from heapq import *
from math import *
class Solution :
def maxKelements ( self , nums : List [ int ], k : int ) -> int :
res = 0
hq = []
for i , x in enumerate ( nums ):
nums [ i ] = - x
heappush ( hq , - x )
for _ in range ( k ):
x = heappop ( hq )
res += x
heappush ( hq , - ceil ( - x / 3 ))
return - res
1.删字母 - 蓝桥云课 (lanqiao.cn)
思路
转换成从 n n n n − m n-m n − m
贪心:考虑当前选择字母的范围。假设上一处选择的字母下标为 L L L L + 1 L+1 L + 1 R R R
最小堆,插入可以选择的元素,每次选择完成进行一次 p o p pop p o p
例如,
12, 5, 7, 6, 20, 1, 4, 15, 21 从9个数中,删除3个,即选择6个。
第一个可以选择的范围是 [ 0 , 3 ] [0, 3] [ 0 , 3 ]
第一处选择了5,下标为1,第二个可以选择的范围是 [ 2 , 4 ] [2, 4] [ 2 , 4 ]
import sys
input = lambda : sys . stdin . readline () . strip ()
from heapq import *
n , m = map ( int , input () . split ())
s = input ()
hq = []
res = ''
L = 0
for i in range ( m ):
heappush ( hq , ( s [ i ], i ))
for R in range ( m , n ):
heappush ( hq , ( s [ R ], R ))
mn , mni = heappop ( hq )
while mni < L :
mn , mni = heappop ( hq )
res += mn
L = mni + 1
print ( res )
注意:本题还有单调栈解法更为简单。
并查集
并查集是一种用于管理元素所属集合的数据结构,实现为一个森林,其中每棵树表示一个集合,树中的节点表示对应集合中的元素。集合内的元素可达且连通。
实现
初始化:每个元素都位于一个单独的集合,表示为一棵只有根节点的树。方便起见,我们将根节点的父亲设为自己
fa = list ( range ( n )) # [0, 1, 2, ..., n - 1]
查询:当 f a [ x ] = x fa[x] =x f a [ x ] = x x x x f i n d ( f a [ x ] ) find(fa[x]) f in d ( f a [ x ]) u , v u,v u , v f i n d ( u ) , f i n d ( v ) find(u),find(v) f in d ( u ) , f in d ( v )
# 查找 x 所属集合(对应的树的树根)
def find ( x ):
if fa [ x ] == x : return x
return find ( fa [ x ])
def find ( x ):
return x if fa [ x ] == x else find ( fa [ x ])
# v所在集合并到u所在集合中
def union ( u , v ):
if find ( u ) != find ( v ):
fa [ find ( v )] = find ( u )
路径压缩
查询过程中,经过的每个元素都属于该集合,我们可直接更新每个元素,让其父节点指向树根。即 f a [ x ] ← f i n d ( f a [ x ] ) fa[x] \leftarrow find(fa[x]) f a [ x ] ← f in d ( f a [ x ])
def find ( x ):
if fa [ x ] == x : return x
fa [ x ] = find ( fa [ x ])
return fa [ x ]
并查集递归模板
# 并查集模板
fa = list ( range ( n + 1 ))
def find ( x ):
if fa [ x ] == x : return x
fa [ x ] = find ( fa [ x ])
return fa [ x ]
def union ( u , v ):
if find ( u ) != find ( v ):
fa [ find ( v )] = find ( u )
迭代模板
fa = list ( range ( n ))
def find ( x ):
root = x
while fa [ root ] != root :
root = fa [ root ]
while fa [ x ] != x : # 路径压缩
x , fa [ x ] = fa [ x ], root
return root
def union ( u , v ):
root_u = find ( u )
root_v = find ( v )
if root_u != root_v :
fa [ root_v ] = root_u
常见问题
求连通块个数
记录每个集合大小:绑定到根节点
记录每个点到根节点的 距离 :绑定到每一个节点上
P1551 亲戚 - 洛谷 (luogu.com.cn)
语言整理
对一个无向图有 n n n m m m ( u , v ) (u,v) ( u , v ) p p p p u , p v p_u,p_v p u , p v
思路
可达、连通的连通分量可以看作一个集合。
对给定的无向边 ( u , v ) (u,v ) ( u , v ) u n i o n ( u , v ) union(u,v) u ni o n ( u , v )
对每组询问,f i n d ( p u ) find(p_u) f in d ( p u ) f i n d ( p v ) find(p_v) f in d ( p v ) u , v u,v u , v
import sys
n , m , p = map ( int , input () . split ())
# 并查集模板
fa = list ( range ( n + 1 ))
def find ( x ):
if fa [ x ] == x : return x
fa [ x ] = find ( fa [ x ])
return fa [ x ]
def union ( u , v ):
if find ( u ) != find ( v ):
fa [ find ( v )] = find ( u )
for _ in range ( m ):
u , v = map ( int , input () . split ())
# 通过合并,表示可达、连通关系
union ( u , v )
for _ in range ( p ):
u , v = map ( int , input () . split ())
print ( 'Yes' if find ( u ) == find ( v ) else 'No' )
并查集维护连通分量
P1536 村村通 - 洛谷 (luogu.com.cn)
语言整理
给定若干组数据,每组给 n , m n,m n , m n n n m m m
思路
import sys
input = lambda : sys . stdin . readline () . strip ()
while True :
s = input ()
if s == '0' : break
n , m = map ( int , s . split ())
fa = list ( range ( n + 1 ))
def find ( x ):
if fa [ x ] == x : return x
fa [ x ] = find ( fa [ x ])
return fa [ x ]
def union ( u , v ):
if find ( u ) != find ( v ):
fa [ find ( v )] = find ( u )
for _ in range ( m ):
u , v = map ( int , input () . split ())
union ( u , v )
# 压缩成严格菊花集
for x in range ( 1 , n + 1 ):
fa [ x ] = find ( x )
cnt = len ( set ( fa )) - 1 # 连通块数量,-1是减去下标0
print ( cnt - 1 ) # cnt - 1是需要修路数量
1.合根植物 - 蓝桥云课 (lanqiao.cn)
import sys
input = lambda : sys . stdin . readline () . strip ()
m , n = map ( int , input () . split ())
k = int ( input ())
fa = list ( range ( m * n + 1 ))
def find ( x ):
if fa [ x ] == x : return x
fa [ x ] = find ( fa [ x ])
return fa [ x ]
def union ( u , v ):
if find ( u ) != find ( v ):
fa [ find ( v )] = find ( u )
for _ in range ( k ):
u , v = map ( int , input () . split ())
union ( u , v )
for x in range ( 1 , n * m + 1 ):
fa [ x ] = find ( x )
print ( len ( set ( fa )) - 1 )
1998. 数组的最大公因数排序 - 力扣(LeetCode)
质因子分解 + 并查集判断连通分量。
将所有数看成一个图中的节点。任意两个数 u , v u, v u , v u ∼ v u \sim v u ∼ v O ( n 2 ) O(n^2) O ( n 2 ) x x x
记数组中最大值 m = m a x ( n u m s ) m = max(nums) m = ma x ( n u m s ) O ( x ) O(\sqrt x) O ( x ) O ( n 2 ) O(n^2) O ( n 2 ) O ( n m ) O(n \sqrt m) O ( n m )
时间复杂度:O ( n ( m ⋅ α ( m ) ) + n log n ) O\bigg(n\big(\sqrt m \cdot \alpha(m) \big) +n\log n \bigg ) O ( n ( m ⋅ α ( m ) ) + n log n )
def gcdSort ( self , nums : List [ int ]) -> bool :
n = len ( nums )
fa = list ( range ( max ( nums ) + 1 ))
def find ( x ): # x 压缩到 fa [x] 中
if fa [ x ] != x :
fa [ x ] = find ( fa [ x ])
return fa [ x ]
def union ( u , v ): # u 合并到 v 中
if find ( u ) != find ( v ):
fa [ find ( u )] = find ( v )
for i , x in enumerate ( nums ):
xx = x
for j in range ( 2 , int ( sqrt ( x )) + 1 ):
if x % j == 0 :
union ( j , xx )
while x % j == 0 :
x //= j
if x > 1 :
union ( x , xx )
sorted_nums = sorted ( nums )
for u , v in zip ( nums , sorted_nums ):
if u == v : continue
# 不在位元素,需要看是否在同一连通分量
if find ( u ) != find ( v ): return False
return True
952. 按公因数计算最大组件大小 - 力扣(LeetCode)
def largestComponentSize ( self , nums : List [ int ]) -> int :
n = len ( nums )
m = max ( nums )
fa = list ( range ( m + 1 ))
def find ( x ):
if fa [ x ] != x :
fa [ x ] = find ( fa [ x ])
return fa [ x ]
def union ( u , v ):
if find ( u ) != find ( v ):
fa [ find ( u )] = find ( v )
for x in nums :
xx = x
for j in range ( 2 , int ( sqrt ( x )) + 1 ):
if x % j == 0 :
union ( xx , j )
while x % j == 0 :
x //= j
if x > 1 :
union ( xx , x )
for x in nums :
find ( x )
cnt = Counter ()
for x in nums : cnt [ fa [ x ]] += 1
return max ( cnt . values ())
**并查集维护连通块大小 **
模板代码:
fa = list ( range ( n + 1 ))
siz = [ 1 ] * ( n + 1 )
def find ( x ):
if fa [ x ] != x :
fa [ x ] = find ( fa [ x ])
return fa [ x ]
def union ( u , v ):
if find ( u ) != find ( v ):
siz [ find ( v )] += siz [ find ( u )]
fa [ find ( u )] = find ( v )
765. 情侣牵手 - 力扣(LeetCode)
诸如 ( 0 , 1 ) , ( 1 , 2 ) , ( 2 , 3 ) , ( 3 , 1 ) (0,1), (1, 2), (2, 3), (3,1) ( 0 , 1 ) , ( 1 , 2 ) , ( 2 , 3 ) , ( 3 , 1 )
class Solution :
def minSwapsCouples ( self , row : List [ int ]) -> int :
n = len ( row )
fa = list ( range ( n + 1 ))
siz = [ 1 ] * ( n + 1 )
def find ( x ):
if fa [ x ] != x :
fa [ x ] = find ( fa [ x ])
return fa [ x ]
def union ( u , v ):
if find ( u ) != find ( v ):
siz [ find ( v )] += siz [ find ( u )]
fa [ find ( u )] = find ( v )
s = set ()
for i in range ( 0 , n , 2 ):
p = i // 2
l , r = row [ i ] // 2 , row [ i + 1 ] // 2
if l == r : continue
union ( l , r )
for x in row :
s . add ( find ( x // 2 ))
res = 0
for x in s :
res += siz [ find ( x )] - 1
return res
2867. 统计树中的合法路径数目 - 力扣(LeetCode)
并查集维护所有非质数子连通块的大小。
def countPaths ( self , n : int , edges : List [ List [ int ]]) -> int :
primes = []
N = n + 10
is_prime = [ True ] * N
is_prime [ 0 ] = is_prime [ 1 ] = False
for i in range ( 2 , N ):
if is_prime [ i ]:
primes . append ( i )
for p in primes :
if i * p >= N :
break
is_prime [ i * p ] = False
if i % p == 0 :
break
e = [[] for _ in range ( n + 1 )]
fa = list ( range ( n + 1 ))
siz = [ 1 ] * ( n + 1 )
def find ( x ):
if fa [ x ] != x :
fa [ x ] = find ( fa [ x ])
return fa [ x ]
def union ( u , v ): # u 合并到 v
if find ( u ) != find ( v ):
siz [ find ( v )] += siz [ find ( u )]
fa [ find ( u )] = find ( v )
for u , v in edges :
e [ u ] . append ( v )
e [ v ] . append ( u )
if not is_prime [ u ] and not is_prime [ v ]:
union ( u , v )
res = 0
vis = [ False ] * ( n + 1 )
for u in range ( 1 , n + 1 ):
if not vis [ u ] and is_prime [ u ]:
# 遍历 u 的所有非质数连通块
vis [ u ] = True
cur_siz = 0
for v in e [ u ]:
if not is_prime [ v ]:
sz = siz [ find ( v )]
res += sz + sz * cur_siz
cur_siz += sz
return res
并查集维护连通块按位与的值
100244. 带权图里旅途的最小代价 - 力扣(LeetCode)
def minimumCost ( self , n : int , edges : List [ List [ int ]], query : List [ List [ int ]]) -> List [ int ]:
fa = list ( range ( n ))
cc_and = [ - 1 ] * n
def find ( x ):
if fa [ x ] != x :
fa [ x ] = find ( fa [ x ])
return fa [ x ]
def union ( u , v , w ): # v 合并到 u 中
if find ( u ) != find ( v ):
cc_and [ find ( u )] &= cc_and [ find ( v )]
fa [ find ( v )] = find ( u )
for u , v , w in edges :
# 各自连通块内更新,只要更新其一即可
cc_and [ find ( u )] &= w
union ( u , v , w )
return [ 0 if u == v else ( - 1 if find ( u ) != find ( v ) else cc_and [ find ( u )]) for u , v in query ]
并查集维护链
把考虑过的元素串起来,链条的长度就是当前一段数的长度。关键需要高效串联两条链。
2334. 元素值大于变化阈值的子数组 - 力扣(LeetCode)
时间复杂度:O ( n l o g n ) O(nlogn) O ( n l o g n )
对 n u m s nums n u m s x x x k − 1 k - 1 k − 1
def validSubarraySize ( self , nums : List [ int ], threshold : int ) -> int :
n = len ( nums )
fa = list ( range ( n + 1 ))
siz = [ 1 ] * ( n + 1 )
def find ( x ):
if fa [ x ] != x : fa [ x ] = find ( fa [ x ])
return fa [ x ]
def union ( u , v ): # v 合并到 u 中
if find ( u ) != find ( v ):
siz [ find ( u )] += siz [ find ( v )]
fa [ find ( v )] = find ( u )
for x , i in sorted ( zip ( nums , range ( n )), reverse = True ):
union ( i , i + 1 )
k = siz [ find ( i )] - 1
if x > ( threshold / k ): return k
return - 1
1.修改数组 - 蓝桥云课 (lanqiao.cn)
import os
import sys
N = int ( input ())
a = list ( map ( int , input () . split ()))
fa = list ( range ( 10 ** 6 + 1 ))
def find ( x ):
if x == fa [ x ]: return x
fa [ x ] = find ( fa [ x ])
return fa [ x ]
def union ( u , v ):
fa [ find ( v )] = find ( u )
for i in range ( N ):
a [ i ] = find ( a [ i ])
union ( a [ i ] + 1 , a [ i ])
print ( * a )
Trie树 / 字典树
26 叉字典树
class Trie :
def __init__ ( self ):
self . is_end = False
self . next = [ None ] * 26
def insert ( self , word : str ) -> None :
node = self
for ch in word :
idx = ord ( ch ) - ord ( 'a' )
if not node . next [ idx ]:
node . next [ idx ] = Trie ()
node = node . next [ idx ]
node . is_end = True
def search ( self , word : str ) -> bool :
node = self
for ch in word :
idx = ord ( ch ) - ord ( 'a' )
if not node . next [ idx ]:
return False
node = node . next [ idx ]
return node . is_end
def startsWith ( self , prefix : str ) -> bool :
node = self
for ch in prefix :
idx = ord ( ch ) - ord ( 'a' )
if not node . next [ idx ]:
return False
node = node . next [ idx ]
return True
哈希字典树
def countPrefixSuffixPairs ( self , words : List [ str ]) -> int :
class Node :
__slots__ = 'children' , 'cnt'
def __init__ ( self ):
self . children = {} # 用字典的字典树
self . cnt = 0
res = 0
root = Node () # 树根
for word in words :
cur = root
for p in zip ( word , word [:: - 1 ]): # (p [i], p [n - i - 1])
if p not in cur . children :
cur . children [ p ] = Node ()
cur = cur . children [ p ]
res += cur . cnt
cur . cnt += 1
return res
class Trie :
def __init__ ( self ):
self . end = False
self . next = {}
def insert ( self , word : str ) -> None :
p = self
for ch in word :
if ch not in p . next :
p . next [ ch ] = Trie ()
p = p . next [ ch ]
p . end = True
def search ( self , word : str ) -> bool :
p = self
for ch in word :
if ch not in p . next :
return False
p = p . next [ ch ]
return p . end
def startsWith ( self , prefix : str ) -> bool :
p = self
for ch in prefix :
if ch not in p . next :
return False
p = p . next [ ch ]
return True
# Your Trie object will be instantiated and called as such:
# obj = Trie()
# obj.insert(word)
# param_2 = obj.search(word)
# param_3 = obj.startsWith(prefix)
线段树
lazy 线段树
支持单点修改 / 区间修改 / 区间查询
支持最小/最大/求和
class SegmentTree :
__slots__ = [ 'node' , 'lazy' , 'n' , 'nums' , 'op' , 'ini' , 'ops' ]
def __init__ ( self , nums , ops = 'sum' ):
n = len ( nums )
if ops == 'sum' or ops == 'bin' :
op , ini = lambda a , b : a + b , 0
elif ops == 'max' :
op , ini = lambda a , b : max ( a , b ), - inf
elif ops == 'min' :
op , ini = lambda a , b : min ( a , b ), inf
self . nums = nums
self . op = op
self . ini = ini
self . ops = ops
self . node = [ ini ] * ( 4 * n )
self . lazy = [ None ] * ( 4 * n )
self . n = n
def build ( self , idx = 1 , l = 1 , r = None ):
if r is None : r = self . n
if l == r :
self . node [ idx ] = self . nums [ l - 1 ]
return
mid = ( l + r ) >> 1
self . build ( idx << 1 , l , mid )
self . build (( idx << 1 ) + 1 , mid + 1 , r )
self . node [ idx ] = self . op ( self . node [ idx << 1 ], self . node [( idx << 1 ) + 1 ])
def do ( self , idx , dl , dr , val = None ):
if self . ops == 'bin' :
self . node [ idx ] = dr - dl + 1
self . lazy [ idx ] = True
elif self . ops == 'sum' :
self . node [ idx ] = self . op ( self . node [ idx ], ( dr - dl + 1 ) * val )
self . lazy [ idx ] = val
else :
self . node [ idx ] = self . op ( val , self . node [ idx ])
self . lazy [ idx ] = val
def pushdown ( self , idx , pl , pr ):
val = self . lazy [ idx ]
mid = ( pl + pr ) >> 1
self . do ( idx << 1 , pl , mid , val )
self . do (( idx << 1 ) + 1 , mid + 1 , pr , val )
self . lazy [ idx ] = None
def update ( self , ul , ur , val , idx = 1 , l = 1 , r = None ):
if r is None : r = self . n
if ul <= l and r <= ur :
self . do ( idx , l , r , val )
return
if self . lazy [ idx ]:
self . pushdown ( idx , l , r )
mid = ( l + r ) >> 1
if ul <= mid : self . update ( ul , ur , val , idx << 1 , l , mid )
if ur > mid : self . update ( ul , ur , val , ( idx << 1 ) + 1 , mid + 1 , r )
self . node [ idx ] = self . op ( self . node [ idx << 1 ], self . node [( idx << 1 ) + 1 ])
def query ( self , ql , qr , idx = 1 , l = 1 , r = None ):
if r is None : r = self . n
if ql <= l and r <= qr :
return self . node [ idx ]
if self . lazy [ idx ]:
self . pushdown ( idx , l , r )
mid = ( l + r ) >> 1
ansl , ansr = self . ini , self . ini
if ql <= mid : ansl = self . query ( ql , qr , idx << 1 , l , mid )
if qr > mid : ansr = self . query ( ql , qr , ( idx << 1 ) + 1 , mid + 1 , r )
return self . op ( ansl , ansr )
tr = SegmentTree ([ 1 , 2 , 3 , 4 , 5 ], 'sum' )
tr . build ()
print ( tr . query ( 1 , 5 )) # 15
print ( tr . query ( 2 , 5 )) # 14
tr . update ( 2 , 4 , 2 ) # 1 4 5 6 5
print ( tr . query ( 2 , 5 )) # 20
tr = SegmentTree ([ 8 , 4 , 5 , 7 , 9 ], 'min' )
tr . build ()
print ( tr . query ( 1 , 4 )) # 4
tr . update ( 1 , 4 , 5 ) # [5, 4, 5, 5, 9]
print ( tr . query ( 4 , 5 )) # 5
tr . update ( 3 , 5 , - 10 ) # [5, 4, -10, -10, -10]
print ( tr . query ( 1 , 3 )) # -10
lazy 线段树(01 翻转)
class Solution :
def handleQuery ( self , nums1 : List [ int ], nums2 : List [ int ], queries : List [ List [ int ]]) -> List [ int ]:
n = len ( nums1 )
node = [ 0 ] * ( 4 * n )
# 懒标记:True 表示该节点代表的区间被曾经被修改,但是其子节点尚未更新
lazy = [ False ] * ( 4 * n )
# 初始化线段树
def build ( i = 1 , l = 1 , r = n ):
if l == r :
node [ i ] = nums1 [ l - 1 ]
return
mid = ( l + r ) >> 1
build ( i * 2 , l , mid )
build ( i * 2 + 1 , mid + 1 , r )
# 维护区间 [l, r] 的值
node [ i ] = node [ i * 2 ] + node [ i * 2 + 1 ]
# 更新节点值,并设置 lazy 标记
def do ( i , l , r ):
node [ i ] = r - l + 1 - node [ i ]
lazy [ i ] = not lazy [ i ]
# 区间更新:本题中更新区间 [l, r] 相当于做翻转
def update ( L , R , i = 1 , l = 1 , r = n ):
if L <= l and r <= R :
do ( i , l , r )
return
mid = ( l + r ) >> 1
if lazy [ i ]:
# 根据标记信息更新 p 的两个左右子节点,同时为子节点增加标记
# 然后清除当前节点的标记
do ( i * 2 , l , mid )
do ( i * 2 + 1 , mid + 1 , r )
lazy [ i ] = False
if L <= mid :
update ( L , R , i * 2 , l , mid )
if R > mid :
update ( L , R , i * 2 + 1 , mid + 1 , r )
# 更新节点值
node [ i ] = node [ i * 2 ] + node [ i * 2 + 1 ]
build ()
res , s = [], sum ( nums2 )
for op , L , R in queries :
if op == 1 :
update ( L + 1 , R + 1 )
elif op == 2 :
s += node [ 1 ] * L
else :
res . append ( s )
return res
lazy 线段树(带动态开点)
class Node :
__slots__ = [ 'l' , 'r' , 'lazy' , 'val' ]
def __init__ ( self , val = 0 ):
self . l = None
self . r = None
self . lazy = None
self . val = val
class SegmentTree :
__slots__ = [ 'root' , 'node' , 'op' , 'ini' , 'ops' , 'max_val' ]
def __init__ ( self , ops : str = 'sum' , max_val : int = int ( 1e9 )):
if ops == 'sum' or ops == 'bin' :
op , ini = lambda a , b : a + b if a is not None else b , 0
elif ops == 'max' :
op , ini = lambda a , b : max ( a , b ), - inf
elif ops == 'min' :
op , ini = lambda a , b : min ( a , b ), inf
self . root = Node ( ini )
self . op = op
self . ini = ini
self . ops = ops
self . max_val = max_val
def __do ( self , node , dl , dr , val = None ):
if self . ops == 'bin' :
node . val = dr - dl + 1
node . lazy = True
elif self . ops == 'sum' :
node . val = self . op ( node . val , ( dr - dl + 1 ) * val )
node . lazy = self . op ( node . lazy , val )
else :
node . val = self . op ( node . val , val )
node . lazy = val
# 下放 lazy 标记。如果是孩子为空,则动态开点
def __pushdown ( self , node , pl , pr ):
val = node . lazy
# 根据 lazy 标记信息,更新左右节点,然后将 lazy 信息清除
mid = ( pl + pr ) >> 1
self . __do ( node . l , pl , mid , val )
self . __do ( node . r , mid + 1 , pr , val )
node . lazy = None
def update ( self , ul , ur , val , node = None , l = 1 , r = None ):
# 查询默认从根节点开始
if node is None : node = self . root
if r is None : r = self . max_val
if ul <= l and r <= ur :
self . __do ( node , l , r , val )
return
if node . l is None : node . l = Node ( self . ini )
if node . r is None : node . r = Node ( self . ini )
# 下放标记、根据标记信息更新左右节点,然后清除标记
if node . lazy is not None :
self . __pushdown ( node , l , r )
mid = ( l + r ) >> 1
if ul <= mid : self . update ( ul , ur , val , node . l , l , mid )
if ur > mid : self . update ( ul , ur , val , node . r , mid + 1 , r )
# node.val 为 True 表示这个节点所在区间,均被“跟踪”
node . val = self . op ( node . l . val , node . r . val )
def query ( self , ql , qr , node = None , l = 1 , r = None ):
# 查询默认从根节点开始
if node is None : node = self . root
if r is None : r = self . max_val
if ql <= l and r <= qr :
return node . val
if node . l is None : node . l = Node ( self . ini )
if node . r is None : node . r = Node ( self . ini )
# 下放标记、根据标记信息更新左右节点,然后清除标记
if node . lazy is not None :
self . __pushdown ( node , l , r )
mid = ( l + r ) >> 1
ansl , ansr = self . ini , self . ini
if ql <= mid : ansl = self . query ( ql , qr , node . l , l , mid )
if qr > mid : ansr = self . query ( ql , qr , node . r , mid + 1 , r )
return self . op ( ansl , ansr )
tr = SegmentTree ( 'sum' )
tr . update ( 1 , 10 , 99 )
tr . update ( 1 , 4 , 1 )
tr . update ( 5 , 10 , 1 )
print ( tr . query ( 1 , 1 )) # 100
print ( tr . query ( 1 , 10 )) # 1000
699. 掉落的方块 - 力扣(LeetCode)
class Solution :
def fallingSquares ( self , positions : List [ List [ int ]]) -> List [ int ]:
tr = SegmentTree ( 'max' , int ( 1e8 ))
res = []
for l , sz in positions :
r = l + sz - 1
mxh = tr . query ( l , r ) + sz
tr . update ( l , r , mxh )
res . append ( tr . query ( 1 , int ( 1e8 )))
return res
递归动态开点(无 lazy) 线段树
区间覆盖统计问题,区间覆盖不需要重复操作,不需要进行 lazy 传递
但是数据范围较大,需要动态开点
# https://leetcode.cn/problems/count-integers-in-intervals
class CountIntervals :
__slots__ = 'left' , 'right' , 'l' , 'r' , 'val'
def __init__ ( self , l = 1 , r = int ( 1e9 )):
self . left = self . right = None
self . l , self . r , self . val = l , r , 0
def add ( self , l : int , r : int ) -> None :
# 覆盖区间操作,不需要重复覆盖,饱和区间无需任何操作
if self . val == self . r - self . l + 1 :
return
if l <= self . l and self . r <= r : # self 已被区间 [l, r] 完整覆盖,不再继续递归
self . val = self . r - self . l + 1
return
mid = ( self . l + self . r ) >> 1
# 动态开点
if self . left is None :
self . left = CountIntervals ( self . l , mid ) # 动态开点
if self . right is None :
self . right = CountIntervals ( mid + 1 , self . r ) # 动态开点
if l <= mid :
self . left . add ( l , r )
if mid < r :
self . right . add ( l , r )
# self.val 的值,表示区间 [self.l, self.r] 中被覆盖的点的个数
self . val = self . left . val + self . right . val
def count ( self ) -> int :
return self . val
动态开点 + lazy 线段树 (旧版)
# https://leetcode.cn/problems/range-module/
class Node :
__slots__ = [ 'l' , 'r' , 'lazy' , 'val' ]
def __init__ ( self ):
self . l = None
self . r = None
self . lazy = 0
self . val = False
class SegmentTree :
__slots__ = [ 'root' ]
def __init__ ( self ):
self . root = Node ()
def do ( self , node , val ):
node . val = val
node . lazy = 1
# 下放 lazy 标记。如果是孩子为空,则动态开点
def pushdown ( self , node ):
if node . l is None :
node . l = Node ()
if node . r is None :
node . r = Node ()
# 根据 lazy 标记信息,更新左右节点,然后将 lazy 信息清除
if node . lazy :
self . do ( node . l , node . val )
self . do ( node . r , node . val )
node . lazy = 0
def query ( self , L , R , node = None , l = 1 , r = int ( 1e9 )):
# 查询默认从根节点开始
if node is None :
node = self . root
if L <= l and r <= R :
return node . val
# 下放标记、根据标记信息更新左右节点,然后清除标记
self . pushdown ( node )
mid = ( l + r ) >> 1
vl = vr = True
if L <= mid :
vl = self . query ( L , R , node . l , l , mid )
if R > mid :
vr = self . query ( L , R , node . r , mid + 1 , r )
return vl and vr
def update ( self , L , R , val , node = None , l = 1 , r = int ( 1e9 )):
# 查询默认从根节点开始
if node is None :
node = self . root
if L <= l and r <= R :
self . do ( node , val )
return
mid = ( l + r ) >> 1
# 下放标记、根据标记信息更新左右节点,然后清除标记
self . pushdown ( node )
if L <= mid :
self . update ( L , R , val , node . l , l , mid )
if R > mid :
self . update ( L , R , val , node . r , mid + 1 , r )
# node.val 为 True 表示这个节点所在区间,均被“跟踪”
node . val = bool ( node . l and node . l . val and node . r and node . r . val )
class RangeModule :
def __init__ ( self ):
self . tree = SegmentTree ()
def addRange ( self , left : int , right : int ) -> None :
self . tree . update ( left , right - 1 , True )
def queryRange ( self , left : int , right : int ) -> bool :
return self . tree . query ( left , right - 1 )
def removeRange ( self , left : int , right : int ) -> None :
self . tree . update ( left , right - 1 , False )
# Your RangeModule object will be instantiated and called as such:
# obj = RangeModule()
# obj.addRange(left, right)
# param_2 = obj.queryRange(left, right)
# obj.removeRange(left, right)
LCP 32. 批量处理任务 - 力扣(LeetCode)
class SegmentTree :
__slots__ = [ 'node' , 'lazy' , 'n' , 'nums' , 'op' , 'ini' , 'ops' ]
def __init__ ( self , nums , ops = 'sum' ):
if ops == 'sum' or ops == 'bin' :
self . op , self . ini = lambda a , b : a + b , 0
elif ops == 'max' :
self . op , self . ini = lambda a , b : max ( a , b ), - float ( 'inf' )
elif ops == 'min' :
self . op , self . ini = lambda a , b : min ( a , b ), float ( 'inf' )
self . nums = nums
self . ops = ops
self . n = len ( nums )
self . node = {}
self . lazy = {}
def build ( self , idx = 1 , l = 1 , r = None ):
if r is None :
r = self . n
if l == r :
self . node [ idx ] = self . nums [ l - 1 ]
return
mid = ( l + r ) >> 1
self . build ( idx << 1 , l , mid )
self . build (( idx << 1 ) + 1 , mid + 1 , r )
self . node [ idx ] = self . op ( self . node . get ( idx << 1 , self . ini ), self . node . get (( idx << 1 ) + 1 , self . ini ))
def do ( self , idx , dl , dr , val = None ):
if self . ops == 'bin' :
self . node [ idx ] = dr - dl + 1
self . lazy [ idx ] = True
else :
self . node [ idx ] = self . op ( val , self . node . get ( idx , self . ini ))
self . lazy [ idx ] = val
def pushdown ( self , idx , pl , pr ):
if idx not in self . lazy :
return
val = self . lazy [ idx ]
mid = ( pl + pr ) >> 1
if idx << 1 not in self . node :
self . node [ idx << 1 ] = self . ini
if ( idx << 1 ) + 1 not in self . node :
self . node [( idx << 1 ) + 1 ] = self . ini
self . do ( idx << 1 , pl , mid , val )
self . do (( idx << 1 ) + 1 , mid + 1 , pr , val )
del self . lazy [ idx ]
def update ( self , ul , ur , val , idx = 1 , l = 1 , r = None ):
if r is None :
r = self . n
if ul <= l and r <= ur :
self . do ( idx , l , r , val )
return
self . pushdown ( idx , l , r )
mid = ( l + r ) >> 1
if ul <= mid :
self . update ( ul , ur , val , idx << 1 , l , mid )
if ur > mid :
self . update ( ul , ur , val , ( idx << 1 ) + 1 , mid + 1 , r )
self . node [ idx ] = self . op ( self . node . get ( idx << 1 , self . ini ), self . node . get (( idx << 1 ) + 1 , self . ini ))
def query ( self , ql , qr , idx = 1 , l = 1 , r = None ):
if r is None :
r = self . n
if ql <= l and r <= qr :
return self . node . get ( idx , self . ini )
self . pushdown ( idx , l , r )
mid = ( l + r ) >> 1
ansl , ansr = self . ini , self . ini
if ql <= mid :
ansl = self . query ( ql , qr , idx << 1 , l , mid )
if qr > mid :
ansr = self . query ( ql , qr , ( idx << 1 ) + 1 , mid + 1 , r )
return self . op ( ansl , ansr )
def update_suffix ( self , ul , ur , val , idx = 1 , l = 1 , r = None ):
if r is None :
r = self . n
siz = r - l + 1
if ul <= l and r <= ur and siz - self . node . get ( idx , 0 ) <= val :
ans = siz - self . node . get ( idx , 0 )
self . do ( idx , l , r )
return ans
mid = ( l + r ) >> 1
self . pushdown ( idx , l , r )
ans = 0
if ur > mid :
ans = self . update_suffix ( ul , ur , val , ( idx << 1 ) + 1 , mid + 1 , r )
val -= ans
if val and ul <= mid :
ans += self . update_suffix ( ul , ur , val , idx << 1 , l , mid )
self . node [ idx ] = self . op ( self . node . get ( idx << 1 , self . ini ), self . node . get (( idx << 1 ) + 1 , self . ini ))
return ans
class Solution :
def processTasks ( self , nums ):
nums . sort ( key = lambda x : x [ 1 ])
n , m = len ( nums ), nums [ - 1 ][ 1 ]
tr = SegmentTree ([ 0 ] * ( m + 1 ), 'bin' )
for l , r , c in nums :
l , r = l + 1 , r + 1
c -= tr . query ( l , r )
if c > 0 :
tr . update_suffix ( l , r , c )
return tr . query ( 0 , m + 1 )
线段树优化问题
2617. 网格图中最少访问的格子数 - 力扣(LeetCode)
单点修改 + 区间最小值查询
class SegmentTree :
def __init__ ( self , n : int ):
self . n = n
self . tree = [ inf ] * ( 4 * n )
def op ( self , a , b ):
return min ( a , b )
def update ( self , ul , ur , val , idx = 1 , l = 1 , r = None ):
if r is None : r = self . n
if ul <= l and r <= ur :
self . tree [ idx ] = val
return
mid = ( l + r ) >> 1
if ul <= mid : self . update ( ul , ur , val , idx * 2 , l , mid )
if ur > mid : self . update ( ul , ur , val , idx * 2 + 1 , mid + 1 , r )
self . tree [ idx ] = self . op ( self . tree [ idx * 2 ], self . tree [ idx * 2 + 1 ]) # 更新当前节点的值
def query ( self , ql , qr , idx = 1 , l = 1 , r = None ):
if r is None : r = self . n
if ql <= l and r <= qr :
return self . tree [ idx ]
mid = ( l + r ) >> 1
ansl , ansr = inf , inf
if ql <= mid : ansl = self . query ( ql , qr , idx * 2 , l , mid )
if qr > mid : ansr = self . query ( ql , qr , idx * 2 + 1 , mid + 1 , r )
return self . op ( ansl , ansr )
class Solution :
def minimumVisitedCells ( self , grid : List [ List [ int ]]) -> int :
m , n = len ( grid ), len ( grid [ 0 ])
treey = [ SegmentTree ( m ) for _ in range ( n )]
# treey [j] 是第 j 列的线段树
for i in range ( m - 1 , - 1 , - 1 ):
treex = SegmentTree ( n )
for j in range ( n - 1 , - 1 , - 1 ):
if i == m - 1 and j == n - 1 :
treex . update ( j + 1 , j + 1 , 1 )
treey [ j ] . update ( i + 1 , i + 1 , 1 )
continue
g = grid [ i ][ j ]
if g == 0 : continue
mnx = treex . query ( j + 1 + 1 , min ( g + j , n - 1 ) + 1 ) if j < n - 1 else inf
mny = treey [ j ] . query ( i + 1 + 1 , min ( g + i , m - 1 ) + 1 ) if i < m - 1 else inf
mn = min ( mnx , mny ) + 1
treex . update ( j + 1 , j + 1 , mn )
treey [ j ] . update ( i + 1 , i + 1 , mn )
res = treey [ 0 ] . query ( 1 , 1 )
return res if res != inf else - 1
最值查询朴素无更新线段树:
class Solution :
def subArrayRanges ( self , nums : List [ int ]) -> int :
class SegmentTree :
def __init__ ( self , n , flag ):
self . n = n
self . tree = [ inf * flag ] * ( 4 * n )
self . flag = flag
def op ( self , a , b ):
if self . flag == 1 : return min ( a , b )
elif self . flag == - 1 : return max ( a , b )
def build ( self , idx = 1 , l = 1 , r = None ):
if not r : r = self . n
if l == r :
self . tree [ idx ] = nums [ l - 1 ]
return
mid = ( l + r ) >> 1
self . build ( idx * 2 , l , mid )
self . build ( idx * 2 + 1 , mid + 1 , r )
self . tree [ idx ] = self . op ( self . tree [ idx * 2 ], self . tree [ idx * 2 + 1 ])
def query ( self , ql , qr , idx = 1 , l = 1 , r = None ):
if not r : r = self . n
if ql <= l and r <= qr :
return self . tree [ idx ]
ansl , ansr = inf * self . flag , inf * self . flag
mid = ( l + r ) >> 1
if ql <= mid : ansl = self . query ( ql , qr , idx * 2 , l , mid )
if qr > mid : ansr = self . query ( ql , qr , idx * 2 + 1 , mid + 1 , r )
return self . op ( ansl , ansr )
n = len ( nums )
mxtr , mntr = SegmentTree ( n , - 1 ), SegmentTree ( n , 1 )
res = 0
mxtr . build ()
mntr . build ()
for i in range ( n ):
for j in range ( i + 1 , n ):
res += mxtr . query ( i + 1 , j + 1 ) - mntr . query ( i + 1 , j + 1 )
return res
LCP 32. 批量处理任务 - 力扣(LeetCode)
排序 + 贪心 + lazy 线段树二分优化
class SegmentTree :
__slots__ = [ 'node' , 'lazy' , 'n' , 'nums' , 'op' , 'ini' , 'ops' ]
def __init__ ( self , nums , ops = 'sum' ):
n = len ( nums )
if ops == 'sum' or ops == 'bin' :
op , ini = lambda a , b : a + b , 0
elif ops == 'max' :
op , ini = lambda a , b : max ( a , b ), - inf
elif ops == 'min' :
op , ini = lambda a , b : min ( a , b ), inf
self . nums = nums
self . op = op
self . ini = ini
self . ops = ops
self . node = [ ini ] * ( 4 * n )
self . lazy = [ None ] * ( 4 * n )
self . n = n
def build ( self , idx = 1 , l = 1 , r = None ):
if r is None : r = self . n
if l == r :
self . node [ idx ] = self . nums [ l - 1 ]
return
mid = ( l + r ) >> 1
self . build ( idx << 1 , l , mid )
self . build (( idx << 1 ) + 1 , mid + 1 , r )
self . node [ idx ] = self . op ( self . node [ idx << 1 ], self . node [( idx << 1 ) + 1 ])
def do ( self , idx , dl , dr , val = None ):
if self . ops == 'bin' :
self . node [ idx ] = dr - dl + 1
self . lazy [ idx ] = True
else :
self . node [ idx ] = self . op ( val , self . node [ idx ])
self . lazy [ idx ] = val
def pushdown ( self , idx , pl , pr ):
val = self . lazy [ idx ]
mid = ( pl + pr ) >> 1
self . do ( idx << 1 , pl , mid , val )
self . do (( idx << 1 ) + 1 , mid + 1 , pr , val )
self . lazy [ idx ] = None
def update ( self , ul , ur , val , idx = 1 , l = 1 , r = None ):
if r is None : r = self . n
if ul <= l and r <= ur :
self . do ( idx , l , r , val )
return
if self . lazy [ idx ]:
self . pushdown ( idx , l , r )
mid = ( l + r ) >> 1
if ul <= mid : self . update ( ul , ur , val , idx << 1 , l , mid )
if ur > mid : self . update ( ul , ur , val , ( idx << 1 ) + 1 , mid + 1 , r )
self . node [ idx ] = self . op ( self . node [ idx << 1 ], self . node [( idx << 1 ) + 1 ])
def query ( self , ql , qr , idx = 1 , l = 1 , r = None ):
if r is None : r = self . n
if ql <= l and r <= qr :
return self . node [ idx ]
if self . lazy [ idx ]:
self . pushdown ( idx , l , r )
mid = ( l + r ) >> 1
ansl , ansr = self . ini , self . ini
if ql <= mid : ansl = self . query ( ql , qr , idx << 1 , l , mid )
if qr > mid : ansr = self . query ( ql , qr , ( idx << 1 ) + 1 , mid + 1 , r )
return self . op ( ansl , ansr )
def update_suffix ( self , ul , ur , val , idx = 1 , l = 1 , r = None ):
if r is None : r = self . n
siz = r - l + 1
if ul <= l and r <= ur and siz - self . node [ idx ] <= val :
ans = siz - self . node [ idx ]
self . do ( idx , l , r )
return ans
mid = ( l + r ) >> 1
if self . lazy [ idx ]:
self . pushdown ( idx , l , r )
ans = 0
if ur > mid : ans += self . update_suffix ( ul , ur , val , ( idx << 1 ) + 1 , mid + 1 , r )
val -= ans
if val and ul <= mid : ans += self . update_suffix ( ul , ur , val , idx << 1 , l , mid )
self . node [ idx ] = self . op ( self . node [ idx << 1 ], self . node [( idx << 1 ) + 1 ])
return ans
class Solution :
def findMinimumTime ( self , nums : List [ List [ int ]]) -> int :
nums . sort ( key = lambda x : x [ 1 ])
n , m = len ( nums ), nums [ - 1 ][ 1 ]
tr = SegmentTree ([ 0 ] * m , 'bin' )
for l , r , c in nums :
c -= tr . query ( l , r )
if c > 0 :
tr . update_suffix ( l , r , c )
return tr . query ( 0 , m )
树状数组
下标从 1 开始,单点修改 + 区间查询
# 下标从 1 开始
class FenwickTree :
def __init__ ( self , length : int ):
self . length = length
self . tree = [ 0 ] * ( length + 1 )
def lowbit ( self , x : int ) -> int :
return x & ( - x )
# 更新自底向上
def update ( self , idx : int , val : int ) -> None :
while idx <= self . length :
self . tree [ idx ] += val
idx += self . lowbit ( idx )
# 查询自顶向下
def query ( self , idx : int ) -> int :
res = 0
while idx > 0 :
res += self . tree [ idx ]
idx -= self . lowbit ( idx )
return res
class NumArray :
def __init__ ( self , nums : List [ int ]):
n = len ( nums )
self . nums = nums
self . tree = FenwickTree ( n )
for i , x in enumerate ( nums ):
self . tree . update ( i + 1 , x )
def update ( self , index : int , val : int ) -> None :
# 因为这里是更新为 val, 所以节点增加的值应为 val - self.nums [index]
# 同时需要更新 nums [idx]
self . tree . update ( index + 1 , val - self . nums [ index ])
self . nums [ index ] = val
def sumRange ( self , left : int , right : int ) -> int :
r = self . tree . query ( right + 1 )
l = self . tree . query ( left )
return r - l
# Your NumArray object will be instantiated and called as such:
# obj = NumArray(nums)
# obj.update(index, val)
# param_2 = obj.sumRange(left, right)
离散化树状数组 + 还原
class FenwickTree :
def __init__ ( self , length : int ):
self . length = length
self . tree = [ 0 ] * ( length + 1 )
def lowbit ( self , x : int ) -> int :
return x & ( - x )
# 更新自底向上
def update ( self , idx : int , val : int ) -> None :
while idx <= self . length :
self . tree [ idx ] += val
idx += self . lowbit ( idx )
# 查询自顶向下
def query ( self , idx : int ) -> int :
res = 0
while idx > 0 :
res += self . tree [ idx ]
idx -= self . lowbit ( idx )
return res
class Solution :
def resultArray ( self , nums : List [ int ]) -> List [ int ]:
# 离散化 nums
sorted_nums = sorted ( nums )
tmp = nums . copy ()
nums = [ bisect . bisect_left ( sorted_nums , x ) + 1 for x in nums ]
# 还原
mp_rev = { i : x for i , x in zip ( nums , tmp )}
n = len ( nums )
t1 = FenwickTree ( n )
t2 = FenwickTree ( n )
a = [ nums [ 0 ]]
b = [ nums [ 1 ]]
t1 . update ( nums [ 0 ], 1 )
t2 . update ( nums [ 1 ], 1 )
for i in range ( 2 , len ( nums )):
x = nums [ i ]
c = len ( a ) - t1 . query ( x )
d = len ( b ) - t2 . query ( x )
if c > d or c == d and len ( a ) <= len ( b ):
a . append ( x )
t1 . update ( x , 1 )
else :
b . append ( x )
t2 . update ( x , 1 )
# 还原为原始数据: i 为离散化秩,x 为还原值
return [ mp_rev [ i ] for i in a ] + [ mp_rev [ i ] for i in b ]
可离散化线段树
class FenwickTree :
def __lowbit ( self , x : int ) -> int :
"""
返回x 的二进制中,最低为的1所构成的数。
:param x: 整数
:return: x的二进制中,最低为的1所构成的数
"""
return x & - x
def __init__ ( self , n : int , discretize : bool = False , nums : [ List [ int ]] = None ):
"""
初始化树状数组(Fenwick Tree)数据结构,下标从0开始
:param n: 值域范围
:param discretize: 是否对输入值进行离散化
:param nums: 离散化所需的输入数组
"""
self . __dic = None
self . __discretize = discretize
self . __nums = None
self . __n = n
if discretize :
unique_nums = sorted ( set ( nums ))
self . __dic = { unique_nums [ i ]: i + 1 for i in range ( len ( unique_nums ))}
self . __n = len ( unique_nums )
self . __nums = [ 0 ] * ( self . __n + 1 )
def __query ( self , x : int ) -> int :
"""
查询小于等于x的个数
:param x: 查询的数
:return: 查询小于等于x的个数
"""
res = 0
while x > 0 :
res += self . __nums [ x ]
x -= self . __lowbit ( x )
return res
def update ( self , x : int , val : int ) -> None :
"""
x处对应的值增加val
:param x: 更新的数
:param val: 变化值
"""
if self . __discretize :
if x not in self . __dic :
raise ValueError ( f "值 { x } 不在离散化范围内" )
x = self . __dic [ x ]
while x <= self . __n :
self . __nums [ x ] += val
x += self . __lowbit ( x )
def query ( self , lx : int , rx : int = None ) -> int :
"""
如果只传入一个参数,则查询小于等于lx的个数
如果传入两个参数,则查询大于等于lx, 小于等于rx的个数
:param lx: 查询区间左端点
:param rx: 查询区间右端点
:return: 查询区间内的元素个数
"""
if self . __discretize :
if lx not in self . __dic :
raise ValueError ( f "值 { lx } 不在离散化范围内" )
lx = self . __dic [ lx ]
if rx is not None :
if rx not in self . __dic :
raise ValueError ( f "值 { rx } 不在离散化范围内" )
rx = self . __dic [ rx ]
if rx is not None :
if lx > rx :
raise ValueError ( f "左边界 { lx } 大于右边界 { rx } " )
return self . __query ( rx ) - self . __query ( lx - 1 )
return self . __query ( lx )
ST 表 / 可重复贡献问题
可重复贡献问题:指对于运算 o p t opt o pt x o p t x = x x \space opt \space x = x x o pt x = x
ST 表思想基于倍增,不支持修改操作。
预处理:O ( n l o g n ) O(nlogn) O ( n l o g n )
f ( i , j ) f(i, j) f ( i , j ) [ i , i + 2 j − 1 ] [i, i + 2^j - 1] [ i , i + 2 j − 1 ]
l e f t = [ i , i + 2 j − 1 − 1 ] , r i g h t = [ i + 2 j − 1 , i + 2 j − 1 ]
left = [i, i + 2^{j-1} -1], right = [i+2^{j-1}, i+2^j-1]
l e f t = [ i , i + 2 j − 1 − 1 ] , r i g h t = [ i + 2 j − 1 , i + 2 j − 1 ] 则:
f ( i , j ) = o p t ( f ( i , j − 1 ) , f ( i + 2 j − 1 , j − 1 ) )
f(i, j) = opt(f(i, j - 1), f(i + 2^{j - 1}, j - 1))
f ( i , j ) = o pt ( f ( i , j − 1 ) , f ( i + 2 j − 1 , j − 1 )) 初始化时:
f ( i , 0 ) = a [ i ]
f(i, 0) = a [i]
f ( i , 0 ) = a [ i ] 对于 j j j i + 2 j − 1 i + 2 ^ j - 1 i + 2 j − 1 n − 1 n - 1 n − 1 2 j 2 ^ j 2 j n n n
j ∈ [ 1 , c e i l ( l o g 2 j ) + 1 )
j \in [1, ceil(log_2^j) + 1)
j ∈ [ 1 , ce i l ( l o g 2 j ) + 1 ) 对于 i i i
i + 2 j − 1 < n
i + 2 ^ j - 1 < n
i + 2 j − 1 < n 即:
i ∈ [ 0 , n − 2 k + 1 )
i \in[0, n - 2^k + 1)
i ∈ [ 0 , n − 2 k + 1 ) 例如,对于 f ( 4 , 3 ) = o p t ( f ( 4 , 2 ) , f ( 8 , 2 ) ) f(4, 3) = opt(f(4, 2), f(8, 2)) f ( 4 , 3 ) = o pt ( f ( 4 , 2 ) , f ( 8 , 2 ))
lenj = math . ceil ( math . __log ( n , 2 )) + 1
f = [[ 0 ] * lenj for _ in range ( n )]
for i in range ( n ):
f [ i ][ 0 ] = a [ i ]
for j in range ( 1 , lenj ):
# i + 2 ^ j < n + 1
for i in range ( n + 1 - ( 1 << j )):
f [ i ][ j ] = opt ( f [ i ][ j - 1 ], f [ i + ( 1 << ( j - 1 ))][ j - 1 ])
单次询问:O ( 1 ) O(1) O ( 1 )
例如, 对于 q r y ( 5 , 10 ) qry(5, 10) q ry ( 5 , 10 ) 6 6 6 i n t ( l o g 2 6 ) = 2 int(log_2^6) = 2 in t ( l o g 2 6 ) = 2 k = 2 2 k = 2^2 k = 2 2
即 o p t ( 5 , 10 ) = o p t ( o p t ( 5 , 8 ) , o p t ( 7 , 10 ) ) opt(5, 10) = opt(opt(5, 8), opt(7, 10)) o pt ( 5 , 10 ) = o pt ( o pt ( 5 , 8 ) , o pt ( 7 , 10 )) ( l , l + 2 k − 1 ) (l, l + 2^k-1) ( l , l + 2 k − 1 ) ( r − 2 k + 1 , r ) (r - 2^k+1,r) ( r − 2 k + 1 , r )
q r y ( l , r ) = o p t ( q r y ( l , k ) , q r y ( r − 2 k + 1 , k ) )
qry(l, r) = opt(qry(l, k), qry(r - 2 ^k + 1, k))
q ry ( l , r ) = o pt ( q ry ( l , k ) , q ry ( r − 2 k + 1 , k )) def qry ( l , r ):
k = log [ r - l + 1 ]
return opt ( f [ l ][ k ], f [ r - ( 1 << k ) + 1 ][ k ])
可以提取预处理一个对数数组。例如 i n t ( l o g ( 7 ) ) = i n t ( l o g ( 3 ) ) + 1 = i n t ( l o g ( 1 ) ) + 1 + 1 int(log(7)) = int(log(3)) + 1 = int(log(1)) + 1 + 1 in t ( l o g ( 7 )) = in t ( l o g ( 3 )) + 1 = in t ( l o g ( 1 )) + 1 + 1
log = [ 0 ] * ( n + 1 )
for i in range ( 2 , n + 1 ):
log [ i ] = log [ i >> 1 ] + 1
模板
def opt ( a , b ):
return max ( a , b )
lenj = math . ceil ( math . __log ( n , 2 )) + 1
f = [[ 0 ] * lenj for _ in range ( n )]
log = [ 0 ] * ( n + 1 )
for i in range ( 2 , n + 1 ):
log [ i ] = log [ i >> 1 ] + 1
for i in range ( n ): f [ i ][ 0 ] = a [ i ]
for j in range ( 1 , lenj ):
for i in range ( n + 1 - ( 1 << j )):
f [ i ][ j ] = opt ( f [ i ][ j - 1 ], f [ i + ( 1 << ( j - 1 ))][ j - 1 ])
def qry ( l , r ):
k = log [ r - l + 1 ]
return opt ( f [ l ][ k ], f [ r - ( 1 << k ) + 1 ][ k ])
类模板
class ST :
def opt ( self , a , b ):
return a & b
def __init__ ( self , nums ):
n = len ( nums )
log = [ 0 ] * ( n + 1 )
for i in range ( 2 , n + 1 ):
log [ i ] = log [ i >> 1 ] + 1
lenj = ceil ( math . __log ( n , 2 )) + 1
f = [[ 0 ] * lenj for _ in range ( n )]
for i in range ( n ): f [ i ][ 0 ] = nums [ i ]
for j in range ( 1 , lenj ):
for i in range ( n + 1 - ( 1 << j )):
f [ i ][ j ] = self . opt ( f [ i ][ j - 1 ], f [ i + ( 1 << ( j - 1 ))][ j - 1 ])
self . f = f
self . log = log
def qry ( self , L , R ):
k = self . log [ R - L + 1 ]
return self . opt ( self . f [ L ][ k ], self . f [ R - ( 1 << k ) + 1 ][ k ])
2104. 子数组范围和 - 力扣(LeetCode)
def subArrayRanges ( self , nums : List [ int ]) -> int :
# f [i][j] 表示 [i, i + 2^j - 1] 的最值
n = len ( nums )
lenj = ceil ( math . __log ( n , 2 )) + 1
log = [ 0 ] * ( n + 1 )
for i in range ( 2 , n + 1 ):
log [ i ] = log [ i // 2 ] + 1
class ST :
def __init__ ( self , n , flag ):
self . flag = flag
f = [[ inf * flag ] * lenj for _ in range ( n )]
for i in range ( n ):
f [ i ][ 0 ] = nums [ i ]
for j in range ( 1 , lenj ):
for i in range ( n + 1 - ( 1 << j )):
f [ i ][ j ] = self . op ( f [ i ][ j - 1 ], f [ i + ( 1 << ( j - 1 ))][ j - 1 ])
self . f = f
def op ( self , a , b ):
if self . flag == 1 : return min ( a , b )
return max ( a , b )
def query ( self , l , r ):
k = log [( r - l + 1 )]
return self . op ( self . f [ l ][ k ], self . f [ r - ( 1 << k ) + 1 ][ k ])
n = len ( nums )
mxtr , mntr = ST ( n , - 1 ), ST ( n , 1 )
res = 0
for i in range ( n ):
for j in range ( i + 1 , n ):
res += mxtr . query ( i , j ) - mntr . query ( i , j )
return res
图论
建图
给定 n n n m m m g ( u , v ) g(u,v) g ( u , v ) u , v u,v u , v
邻接矩阵
带权无向图
初始值设置为 i n f inf in f
g ( x , x ) g(x,x) g ( x , x ) 0 0 0
from math import inf
n , m = map ( int , input () . split ())
g = [[ inf ] * n for _ in range ( n )]
for _ in range ( m ):
u , v , w = map ( int , input () . split ())
g [ u ][ v ] = g [ v ][ u ] = w
g [ u ][ u ] = g [ v ][ v ] = 0 # 原地不动,距离是0
邻接表
带权无向图
n , m = map ( int , input () . split ())
e = [[] for _ in range ( n )]
for _ in range ( m ):
u , v , w = map ( int , input () . split ())
e [ u ] . append (( v , w ))
e [ v ] . append (( u , w ))
带权有向图
n , m = map ( int , input () . split ())
e = [[] for _ in range ( n )]
for _ in range ( m ):
u , v , w = map ( int , input () . split ())
e [ u ] . append (( v , w ))
不带权有向图
n , m = map ( int , input () . split ())
e = [[] for _ in range ( n )]
for _ in range ( m ):
e [ u ] . append ( v )
图遍历
DFS序(邻接表版)
s = set () # 已经访问的
def dfs ( u ):
s . add ( u )
for v , _ in e [ u ]:
if v not in s :
dfs ( v )
n , m = map ( int , input () . split ())
e = [[] for _ in range ( n )]
for _ in range ( m ):
u , v , w = map ( int , input () . split ())
e [ u ] . append (( v , w ))
e [ v ] . append (( u , w ))
s = set () # 已经访问的
def dfs ( u ):
# 遍历当前节点的操作,如输出节点信息等
print ( u , end = " " )
s . add ( u )
# 遍历邻居
for v , _ in e [ u ]:
if v not in s :
dfs ( v )
dfs ( 0 ) # 0 1 2 3 4
print ()
s . clear () #已经访问的
dfs ( 4 ) # 4 3 0 1 2
去重边建图
100244. 带权图里旅途的最小代价 - 力扣(LeetCode)
这道题需要在建图的时候取 AND 运算的最小值。
e = [ defaultdict ( lambda : - 1 ) for _ in range ( n )]
for u , v , w in edges :
e [ v ][ u ] = e [ u ][ v ] = e [ u ][ v ] & w
Floyd
求解带权图上 多源最短路 。
给定 n n n m m m q q q u , v u, v u , v
考虑 u , v u,v u , v k k k u → k u \rightarrow k u → k k → v k \rightarrow v k → v
k k k k k k [ 0 , n − 1 ] [0, n - 1] [ 0 , n − 1 ] k k k g[u][v] = min(g[u][v], g[u][k] + g[k][v]) \text{ g[u][v] = min(g[u][v], g[u][k] + g[k][v])} g[u][v] = min(g[u][v], g[u][k] + g[k][v]) 为什么 k k k k k k ( u , v ) (u,v) ( u , v )
时间复杂度:O ( n 3 ) O(n^3) O ( n 3 )
for _ in range ( m ):
u , v , w = map ( int , input () . split ())
g [ u ][ v ] = g [ v ][ u ] = w
for k in range ( n ):
for u in range ( n ):
for v in range ( n ):
g [ u ][ v ] = min ( g [ u ][ v ], g [ u ][ k ] + g [ k ][ v ])
from math import inf
n , m = map ( int , input () . split ())
g = [[ inf ] * n for _ in range ( n )]
for _ in range ( m ):
u , v , w = map ( int , input () . split ())
g [ u ][ v ] = g [ v ][ u ] = w
for k in range ( n ):
for u in range ( n ):
for v in range ( n ):
g [ u ][ v ] = min ( g [ u ][ v ], g [ u ][ k ] + g [ k ][ v ])
print ( g )
print ( g [ 4 ][ 2 ]) # 16
1334. 阈值距离内邻居最少的城市 - 力扣(LeetCode)
class Solution :
def findTheCity ( self , n : int , edges : List [ List [ int ]], distanceThreshold : int ) -> int :
res , idx = inf , 0
g = [[ inf ] * n for _ in range ( n )]
for u , v , w in edges :
g [ u ][ v ] = g [ v ][ u ] = w
for k in range ( n ):
for u in range ( n ):
for v in range ( n ):
g [ u ][ v ] = min ( g [ u ][ v ], g [ u ][ k ] + g [ k ][ v ])
for u in range ( n ):
cnt = sum ( g [ u ][ v ] <= distanceThreshold and u != v for v in range ( n ))
if cnt <= res :
res , idx = cnt , u
return idx
Dijkstra
求解非负权图 上单源最短路径。
朴素 Dijkstra
适用于稠密图,时间复杂度:O ( n 2 ) O(n^2) O ( n 2 )
d = [ inf ] * n
d [ 0 ] = 0
s = set () # S集合为已经确定的节点集合
for _ in range ( n - 1 ):
x = - 1
# 从 U - S中找出距离S最近的节点
for u in range ( n ):
if u not in s and ( x < 0 or d [ u ] < d [ x ]):
x = u
s . add ( x )
# 松弛,对每个节点判断以x作为中间节点时,是否距离原点更加
for u in range ( n ):
d [ u ] = min ( d [ u ], d [ x ] + g [ u ][ x ])
from math import inf
n , m = map ( int , input () . split ())
g = [[ inf ] * n for _ in range ( n )]
for _ in range ( m ):
u , v , w = map ( int , input () . split ())
g [ u ][ v ] = g [ v ][ u ] = w
g [ u ][ u ] = g [ v ][ v ] = 0
d = [ inf ] * n
d [ 0 ] = 0
s = set () # S集合为已经确定的节点集合
for _ in range ( n - 1 ):
x = - 1
# 从 U - S中找出距离S最近的节点
for u in range ( n ):
if u not in s and ( x < 0 or d [ u ] < d [ x ]):
x = u
s . add ( x )
# 松弛,对每个节点判断以x作为中间节点时,是否距离原点更加
for u in range ( n ):
d [ u ] = min ( d [ u ], d [ x ] + g [ u ][ x ])
print ( d ) # [10, 11, 16, 7, 0]
743. 网络延迟时间 - 力扣(LeetCode)
class Solution :
def networkDelayTime ( self , e : List [ List [ int ]], n : int , k : int ) -> int :
g = [[ inf ] * ( n + 1 ) for _ in range ( n + 1 )]
m = len ( e )
for i in range ( m ):
u , v , w = e [ i ]
g [ u ][ v ] = w
d = [ inf ] * ( n + 1 )
d [ k ] = 0
s = set () # S集合为已经确定的节点集合
for _ in range ( n - 1 ):
x = - 1
# 从 U - S中找出距离S最近的节点
for u in range ( 1 , n + 1 ):
if u not in s and ( x < 0 or d [ u ] < d [ x ]):
x = u
s . add ( x )
# 松弛,对每个节点判断以x作为中间节点时,是否距离原点更加
for u in range ( 1 , n + 1 ):
d [ u ] = min ( d [ u ], d [ x ] + g [ x ][ u ])
res = max ( d [ 1 : ])
return res if res < inf else - 1
1976. 到达目的地的方案数 - 力扣(LeetCode)
最短路 Dijkstra + 最短路 Dp:求源点 0 到任意节点 i 的最短路个数。
def countPaths ( self , n : int , roads : List [ List [ int ]]) -> int :
g = [[ inf ] * n for _ in range ( n )]
moder = 10 ** 9 + 7
for u , v , w in roads :
g [ u ][ v ] = g [ v ][ u ] = w
g [ u ][ u ] = g [ v ][ v ] = 0
d = [ inf ] * n # dist 数组, d [i] 表示源点到 i 的最短路径长度
d [ 0 ] = 0
v = [ False ] * n # 节点访问标记
mn , res = inf , 0
f = [ 0 ] * n # f [i] 表示源点到 i 节点的最短路个数
f [ 0 ] = 1
for _ in range ( n - 1 ):
x = - 1
for u in range ( n ):
if not v [ u ] and ( x < 0 or d [ u ] < d [ x ]):
x = u
v [ x ] = True
for u in range ( n ):
a = d [ x ] + g [ x ][ u ]
if a < d [ u ]: # 到 u 的最短路个数 = 经过 x 到 u 的个数 = 到 x 的最短路的个数
d [ u ], f [ u ] = a , f [ x ]
elif a == d [ u ] and u != x : # 路径一样短,追加
f [ u ] = ( f [ u ] + f [ x ]) % moder
return f [ n - 1 ]
2662. 前往目标的最小代价 - 力扣(LeetCode)
将 有向图路径 转换为 节点。不需要建图,但是需要首先对 d 数组进行预处理。
def minimumCost ( self , start : List [ int ], target : List [ int ], specialRoads : List [ List [ int ]]) -> int :
# 把路径(a, b) -> (c, d) 简化成 (c, d)
t , s = tuple ( target ), tuple ( start )
d , v = defaultdict ( lambda : inf ), set ()
d [ s ] = 0
def g ( p , q ):
return abs ( p [ 0 ] - q [ 0 ]) + abs ( p [ 1 ] - q [ 1 ])
# 补充 start 和 target 节点
specialRoads . append ([ s [ 0 ], s [ 1 ], t [ 0 ], t [ 1 ], g ( s , t )])
specialRoads . append ([ s [ 0 ], s [ 1 ], s [ 0 ], s [ 1 ], 0 ])
while True :
x = None
# 找到距离 start 最近的 且 未计算过的节点
for x1 , y1 , x2 , y2 , w in specialRoads :
u = ( x2 , y2 )
if u not in v and ( not x or d [ u ] < d [ x ]):
x = u
v . add ( x )
if x == t :
return d [ t ]
for x1 , y1 , x2 , y2 , w in specialRoads :
u0 , u = ( x1 , y1 ), ( x2 , y2 )
# 两种情况,1. start 经过 x 到达 u
# 2. start 经过 x 再到 u0 从路径到达 u
d1 = d [ x ] + g ( x , u )
d2 = d [ x ] + g ( x , u0 ) + w
d [ u ] = min ( d [ u ], d1 , d2 )
堆优化 Dijkstra
适用于稀疏图(点个数的平方远大于边的个数 点个数的平方 远大于 边的个数 点个数的平方远大于边的个数 O ( m l o g m ) O(mlogm) O ( m l o g m ) m 表示边的个数 m表示边的个数 m 表示边的个数
使用小根堆,存放未确定最短路点集对应的 (d [i], i)。对于同一个 i 可能存放多组不同 d [i] 的元组,因此堆中元素的个数最多是 m m m
寻找最小值的过程可以用一个最小堆来快速完成。
e = [[] for _ in range ( n )]
for u , v , w in roads :
e [ u ] . append (( v , w ))
e [ v ] . append (( u , w ))
d = [ inf ] * n
d [ 0 ] = 0
hq = [( 0 , 0 )] # 小根堆,存放未确定最短路点集对应的 (d [i], i)
while hq :
dx , x = heapq . heappop ( hq )
if dx > d [ x ]: continue # 跳过重复出堆,首次出堆一定是最短路
for u , w in e [ x ]:
a = d [ x ] + w
if a < d [ u ]:
d [ u ] = a # 同一个节点 u 的最短路 d [u] 在出堆前会被反复更新
heapq . heappush ( hq , ( a , u ))
1976. 到达目的地的方案数 - 力扣(LeetCode)
def countPaths ( self , n : int , roads : List [ List [ int ]]) -> int :
e = [[] for _ in range ( n )]
for u , v , w in roads :
e [ u ] . append (( v , w ))
e [ v ] . append (( u , w ))
moder = 10 ** 9 + 7
f = [ 0 ] * n
d = [ inf ] * n
f [ 0 ], d [ 0 ] = 1 , 0
hq = [( 0 , 0 )] # 小根堆,存放未确定最短路点集对应的 (d [i], i)
while hq :
dx , x = heapq . heappop ( hq )
if dx > d [ x ]: continue # 之前出堆过
for u , w in e [ x ]:
a = d [ x ] + w
if a < d [ u ]:
d [ u ] = a
f [ u ] = f [ x ]
heapq . heappush ( hq , ( a , u ))
elif a == d [ u ]:
f [ u ] = ( f [ u ] + f [ x ]) % moder
return f [ n - 1 ]
743. 网络延迟时间 - 力扣(LeetCode)
有向图 + 邻接矩阵最短路
def networkDelayTime ( self , times : List [ List [ int ]], n : int , k : int ) -> int :
e = [[] * ( n + 1 ) for _ in range ( n + 1 )]
for u , v , w in times :
e [ u ] . append (( v , w ))
d = [ inf ] * ( n + 1 )
d [ k ] = 0
hq = [( 0 , k )]
while hq :
dx , x = heapq . heappop ( hq )
if dx > d [ x ]: continue
for u , w in e [ x ]:
a = d [ x ] + w
if a < d [ u ]:
d [ u ] = a
heapq . heappush ( hq , ( a , u ))
res = max ( d [ 1 : ])
return res if res < inf else - 1
2045. 到达目的地的第二短时间 - 力扣(LeetCode)
使用双列表 d,存放最短和次短。将等红绿灯转换为松弛条件,通过 t 来判断红灯还是绿灯。
def secondMinimum ( self , n : int , edges : List [ List [ int ]], time : int , change : int ) -> int :
# 将 节点 (u, t) 即 (节点,时间) 作为新的节点
e = [[] for _ in range ( n + 1 )]
for u , v in edges :
e [ u ] . append ( v )
e [ v ] . append ( u )
hq = [( 0 , 1 )]
# (t // change) & 1 == 0 绿色
# (x, t) -> (u, t + time)
# (t // change) & 1 == 1 红色
# 需要 change - t % change 时间进入下一个节点
d , dd = [ inf ] * ( n + 1 ), [ inf ] * ( n + 1 )
d [ 1 ] = 0
while hq :
t , x = heapq . heappop ( hq )
if d [ x ] < t and dd [ x ] < t : # 确认最小的和次小的
continue
for u in e [ x ]:
nt = inf
if ( t // change ) & 1 == 0 :
nt = t + time
else :
nt = t + change - t % change + time
if nt < d [ u ]:
d [ u ] = nt
heapq . heappush ( hq , ( nt , u ))
elif dd [ u ] > nt > d [ u ] :
dd [ u ] = nt
heapq . heappush ( hq , ( nt , u ))
return dd [ n ]
堆优化 Dijkstra(字典写法)
转换建图 + 堆 Dijkstra (字典写法 )
LCP 35. 电动车游城市 - 力扣(LeetCode)
def electricCarPlan ( self , paths : List [ List [ int ]], cnt : int , start : int , end : int , charge : List [ int ]) -> int :
# 将(节点, 电量) 即 (u, c) 看成新的节点
# 将充电等效转换成图
# 则将节点 i 充电消耗时间 charge [u] 看成从(u, c) 到 (u, c + 1) 有 w = 1
n = len ( charge )
e = [[] for _ in range ( n )]
for u , v , w in paths :
e [ u ] . append (( v , w ))
e [ v ] . append (( u , w ))
hq = [( 0 , start , 0 )]
d = {}
while hq :
dx , x , c = heapq . heappop ( hq )
if ( x , c ) in d : # 已经加入到寻找到最短路的集合中
continue
d [( x , c )] = dx
for u , w in e [ x ]:
if c >= w and ( u , c - w ) not in d :
heapq . heappush ( hq , ( w + dx , u , c - w ))
if c < cnt :
heapq . heappush ( hq , ( charge [ x ] + dx , x , c + 1 ))
return d [( end , 0 )]
743. 网络延迟时间 - 力扣(LeetCode)
def networkDelayTime ( self , times : List [ List [ int ]], n : int , k : int ) -> int :
e = [[] * ( n + 1 ) for _ in range ( n + 1 )]
for u , v , w in times :
e [ u ] . append (( v , w ))
d = {}
hq = [( 0 , k )]
while hq :
dx , x = heapq . heappop ( hq )
if x in d : continue # 跳过非首次出堆
d [ x ] = dx # 首次出堆一定是最短路
for u , w in e [ x ]:
a = d [ x ] + w
if u not in d : # 未确定最短路
heapq . heappush ( hq , ( a , u )) # 入堆,同一个节点可能用多组
for i in range ( 1 , n + 1 ):
if i != k and i not in d :
return - 1
return max ( d . values ())
2045. 到达目的地的第二短时间 - 力扣(LeetCode)
求解严格次短路问题:两个 d 字典,一个存放最短,一个存放严格次短
def secondMinimum ( self , n : int , edges : List [ List [ int ]], time : int , change : int ) -> int :
# 将 节点 (u, t) 即 (节点,时间) 作为新的节点
# (t // change) & 1 == 0 绿色
# (x, t) -> (u, t + time)
# (t // change) & 1 == 1 红色
# 需要 change - t % change 时间进入下一个节点
# (x, t) -> (u, t + change - t % change + time)
e = [[] for _ in range ( n + 1 )]
for u , v in edges :
e [ u ] . append ( v )
e [ v ] . append ( u )
hq = [( 0 , 1 )]
d , dd = {}, {} # dd 是确认次短的字典
while hq :
t , x = heapq . heappop ( hq )
if x not in d :
d [ x ] = t
elif t > d [ x ] and x not in dd :
dd [ x ] = t
else :
continue
for u in e [ x ]:
if ( t // change ) & 1 == 0 :
if u not in dd :
heapq . heappush ( hq , ( t + time , u ))
else :
if u not in dd :
heapq . heappush ( hq , ( t + change - t % change + time , u ))
return dd [ n ]
转换建图问题:可折返图 转换成 到达时间的奇偶问题
2577. 在网格图中访问一个格子的最少时间 - 力扣(LeetCode)
class Solution :
def minimumTime ( self , grid : List [ List [ int ]]) -> int :
# (w, x0, x1) 表示到达(x0, x1) 时刻至少为 w
if grid [ 0 ][ 1 ] > 1 and grid [ 1 ][ 0 ] > 1 : return - 1
m , n = len ( grid ), len ( grid [ 0 ])
deltas = [( 1 , 0 ), ( - 1 , 0 ), ( 0 , 1 ), ( 0 , - 1 )]
target = ( m - 1 , n - 1 )
d = {}
hq = [( 0 , ( 0 , 0 ))]
while hq :
dx , x = heappop ( hq )
if x in d : continue
d [ x ] = dx
if x == target : return d [ target ]
x0 , x1 = x [ 0 ], x [ 1 ]
for u0 , u1 in [( x0 + dx , x1 + dy ) for dx , dy in deltas ]:
if not ( 0 <= u0 < m and 0 <= u1 < n ) or ( u0 , u1 ) in d : continue
u , t = ( u0 , u1 ), grid [ u0 ][ u1 ]
if dx + 1 >= t :
heappush ( hq , ( dx + 1 , u ))
else :
# 例如 3 -> 6,折返一次变成 5 后 + 1 到达 6
du = ( t - dx - 1 ) if ( t - dx ) & 1 else t - dx
heappush ( hq , ( dx + du + 1 , u ))
最短路与子序列「和/积」问题
求解一个数组的所有子序列的和 / 积中第 k 小 (大同理) 问题,其中子序列是原数组删去一些元素后剩余元素不改变相对位置的数组。
以和为例,可以转化为最短路问题:
将子序列看成节点 ( s , i d x ) (s, idx) ( s , i d x ) s s s i d x idx i d x i d x − 1 idx - 1 i d x − 1
例如 [ 1 , 2 , 4 , 4 , 5 , 9 ] [1, 2, 4, 4, 5, 9] [ 1 , 2 , 4 , 4 , 5 , 9 ] [ 1 , 2 ] [1,2] [ 1 , 2 ] ( 3 , 2 ) (3, 2) ( 3 , 2 ) i d x − 1 idx-1 i d x − 1 [ 1 , 2 , 4 ] [1, 2, 4] [ 1 , 2 , 4 ] [ 1 , 4 ] [1, 4] [ 1 , 4 ]
可以将原问题看成从 [ ] [\space ] [ ]
假设有 n n n k k k O ( k l o g k ) O(klogk) O ( k l o g k )
注意,如果采用二分答案方式求解,即想求出恰好有 k k k s s s O ( k l o g U ) , U = ∑ a i O(klogU), U = \sum{a_i} O ( k l o gU ) , U = ∑ a i
2386. 找出数组的第 K 大和 - 力扣(LeetCode)
def kSum ( self , nums : List [ int ], k : int ) -> int :
res = sum ( x for x in nums if x > 0 )
nums = sorted ([ abs ( x ) for x in nums ])
# (s, idx) (子序列和, 当前下标)
hq = [( 0 , 0 )]
while k > 1 :
# 每一次会将最小的子序列的和 pop 出去
# pop k - 1 次,堆顶就是答案
s , idx = heappop ( hq )
# 选 idx - 1
if idx < len ( nums ):
heappush ( hq , ( s + nums [ idx ], idx + 1 ))
# 不选 idx - 1
if idx :
heappush ( hq , ( s + ( nums [ idx ] - nums [ idx - 1 ]), idx + 1 ))
k -= 1
return res - hq [ 0 ][ 0 ]
动态修改边权
2699. 修改图中的边权 - 力扣(LeetCode)
在邻接表数组中记录原矩阵中边的位置,方便修改
记 d s i g n a l , i d_{signal, i} d s i g na l , i s i g n a l signal s i g na l i i i
第二次修改边权时,对于特殊边尝试修改条件:
d 1 , x + n w + d 0 , d e s t − d 0 , u = t a r g e t
d_{1, x} + nw + d_{0, dest} - d_{0, u} = target \\
d 1 , x + n w + d 0 , d es t − d 0 , u = t a r g e t 解得:
n w = t a r g e t − d 1 , x + d 0 , u − d 0 , d e s t
nw = target - d_{1, x} + d_{0, u} - d_{0, dest}
n w = t a r g e t − d 1 , x + d 0 , u − d 0 , d es t 当这个值大于 1 时,是一个合法的边权,进行修改。
def modifiedGraphEdges ( self , n : int , edges : List [ List [ int ]], source : int , destination : int , target : int ) -> List [ List [ int ]]:
e = [[] for _ in range ( n )]
# 存放边的位置,方便在原矩阵直接修改
for pos , ( u , v , w ) in enumerate ( edges ):
e [ u ] . append ([ v , pos ])
e [ v ] . append ([ u , pos ])
total_d = [[ inf ] * n for _ in range ( 2 )]
total_d [ 0 ][ source ] = total_d [ 1 ][ source ] = 0
def dijkstra ( signal ):
d = total_d [ signal ] # 第 signal 次的最短路数组
v = set ()
for _ in range ( n - 1 ):
x = - 1
for u in range ( n ):
if u not in v and ( x < 0 or d [ u ] < d [ x ]):
x = u
v . add ( x )
for u , pos in e [ x ]:
w = edges [ pos ][ 2 ]
w = 1 if w == - 1 else w
# d [x] + nw + total_d [0][destination] - total_d [0][u] = target
if signal == 1 and edges [ pos ][ 2 ] == - 1 :
nw = target - total_d [ 0 ][ destination ] + total_d [ 0 ][ u ] - d [ x ]
if nw > 1 : # 合法修改
w = edges [ pos ][ 2 ] = nw
d [ u ] = min ( d [ u ], d [ x ] + w )
return d [ destination ]
if dijkstra ( 0 ) > target : return [] # 全为 1 也会超过 target
if dijkstra ( 1 ) < target : return [] # 最短路无法变大
for e in edges :
if e [ 2 ] == - 1 :
e [ 2 ] = 1
return edges
最小生成树
P3366 【模板】最小生成树 - 洛谷 (luogu.com.cn)
Prim
from math import *
def solve ():
n , m = map ( int , input () . split ())
d = [ inf ] * n
g = [[] for _ in range ( n )]
for _ in range ( m ):
u , v , w = map ( int , input () . split ())
u , v = u - 1 , v - 1
g [ u ] . append (( v , w ))
g [ v ] . append (( u , w ))
d [ 0 ] = 0
res = 0
s = set ()
for _ in range ( n ):
dx , x = inf , - 1
for i in range ( n ):
if i not in s and ( x < 0 or d [ i ] < dx ):
dx , x = d [ i ], i
s . add ( x )
res += dx
for i , w in g [ x ]:
if i not in s :
d [ i ] = min ( d [ i ], w )
if inf not in d :
print ( res )
return
print ( 'orz' )
solve ()
Kruskal
import sys
input = lambda : sys . stdin . readline () . strip ()
def solve ():
n , m = map ( int , input () . split ())
edges = []
for _ in range ( m ):
u , v , w = map ( int , input () . split ())
edges . append (( w , u , v ))
# 按边的权重排序
edges . sort ()
# 并查集初始化
fa = list ( range ( n + 1 ))
def find ( x ):
if fa [ x ] == x :
return x
fa [ x ] = find ( fa [ x ])
return fa [ x ]
def union ( u , v ):
if find ( u ) != find ( v ):
fa [ find ( v )] = find ( u )
return True
return False
res = 0 # 最小生成树的权重和
cnt = 0 # 已选择的边数
for w , u , v in edges :
if union ( u , v ): # 如果边的两个端点不在同一集合中
res += w
cnt += 1
if cnt == n - 1 : # 已经选择了 n-1 条边,最小生成树完成
break
if cnt == n - 1 :
print ( res )
else :
print ( 'orz' ) # 无法形成最小生成树
solve ()
二分图
简单来说,如果图中点可以被分为两组,并且使得所有边都跨越组的边界,则这就是一个二分图。
二分图的最大匹配、完美匹配和匈牙利算法_完美匹配图论-CSDN 博客
定义:无向图 G ( U , V , E ) G(U,V,E) G ( U , V , E ) U U U V V V ∀ ( u , v ) ∈ E \forall (u, v) \in E ∀ ( u , v ) ∈ E
证明:因为走过一条边必然从一个集合走到另一个集合,要完成闭环必须走偶数条边(偶数个点)
二分图判定
785. 判断二分图 - 力扣(LeetCode)
DFS 染色:
def isBipartite ( self , graph : List [ List [ int ]]) -> bool :
n = len ( graph )
color = [ 0 ] * n
flag = True
def dfs ( u , c ):
nonlocal flag
color [ u ] = c
for v in graph [ u ]:
if color [ v ] == 0 :
dfs ( v , - c )
elif color [ v ] == c :
flag = False
return
for i in range ( n ):
if color [ i ] == 0 : dfs ( i , 1 )
if not flag : return False
return True
Bfs 染色:
def isBipartite ( self , graph : List [ List [ int ]]) -> bool :
n = len ( graph )
q = collections . deque ()
color = [ 0 ] * n
for i in range ( n ):
if not color [ i ]:
q . append ( i )
color [ i ] = 1
while q :
u = q . popleft ()
c = color [ u ]
for v in graph [ u ]:
if not color [ v ]:
color [ v ] = - c
q . append ( v )
elif color [ v ] == c :
return False
return True
并查集做法:
维护两个并查集 U , V U, V U , V
对于每个节点 u u u v v v u u u v v v
否则将所有邻接节点加到另一个并查集中。
def isBipartite ( self , graph : List [ List [ int ]]) -> bool :
n = len ( graph )
s = set ()
pa = list ( range ( n ))
def find ( x ):
if pa [ x ] != x :
pa [ x ] = find ( pa [ x ])
return pa [ x ]
def union ( u , v ):
if find ( u ) != find ( v ):
pa [ find ( v )] = find ( u )
for u in range ( n ):
if u not in s :
s . add ( u )
p = None
for v in graph [ u ]:
if find ( u ) == find ( v ):
return False
if p : union ( p , v )
p = v
return True
二分图最大匹配 / 匈牙利算法
二分图的匹配
给定一个二分图 G,在 G 的一个子图 M 中, M 的边集 { E } \{E\} { E } 任意两条边都没有公共顶点 ,则称 M 是一 个匹配 。
最大匹配 :匹配边数最大的匹配。
完美匹配 :如果一个图的某个匹配中,所有的顶点都是匹配点,那么它就是一个完美匹配。图 4 是一个完美匹配。
二分图最大权完美匹配 :二分图边权和最大的完美匹配。
交替路 :从一个未匹配点出发(右),依次经过非匹配边、匹配边、非匹配边…形成的路径叫交替路。
增广路 :从一个未匹配点出发(右),走交替路,如果途径另一个未匹配点(出发的点不算),则这条交替路称为增广路(agumenting path)。例如,图 5 中的一条增广路如图 6 所示(图中的匹配点均用红色标出)
特点:非匹配边比匹配边多一条 。因此,研究增广路的意义是改进匹配。只要把增广路中的匹配边和非匹配边的身份交换即可。由于中间的匹配节点不存在其他相连的匹配边,所以这样做不会破坏匹配的性质。交换后,图中的匹配边数目比原来多了 1 条。
增广路定理
通过不停地找增广路来增加匹配中的匹配边和匹配点。找不到增广路时,达到最大匹配
861. 二分图的最大匹配 - AcWing 题库
n1 , n2 , m = map ( int , input () . split ())
vis = set ()
match = {}
e = defaultdict ( list )
def dfs ( u ) -> bool :
for v in e [ u ]:
if v in vis : continue
vis . add ( v )
if v not in match or dfs ( match [ v ]):
match [ v ] = u
return True
return False
for _ in range ( m ):
u , v = map ( int , input () . split ())
e [ u ] . append ( v )
for u in range ( 1 , n1 + 1 ):
vis = set ()
dfs ( u )
print ( len ( match ))
二分图最大权完美匹配 / KM 算法
1947. 最大兼容性评分和 - 力扣(LeetCode)
暴力枚举时间复杂度:O ( m ! ) O(m!) O ( m !) O ( m 3 ) O(m^3) O ( m 3 )
class KM :
def __init__ ( self , n ):
self . maxn = 300 + 10
self . INF = float ( 'inf' )
self . wx = [ 0 ] * ( self . maxn )
self . wy = [ 0 ] * ( self . maxn )
self . cx = [ - 1 ] * ( self . maxn )
self . cy = [ - 1 ] * ( self . maxn )
self . visx = [ 0 ] * ( self . maxn )
self . visy = [ 0 ] * ( self . maxn )
self . cntx = n
self . cnty = n
self . Map = [[ 0 ] * ( self . maxn ) for _ in range ( self . maxn )]
self . slack = [ 0 ] * ( self . maxn )
def dfs ( self , u ):
self . visx [ u ] = 1
for v in range ( 1 , self . cnty + 1 ):
if not self . visy [ v ] and self . Map [ u ][ v ] != self . INF :
t = self . wx [ u ] + self . wy [ v ] - self . Map [ u ][ v ]
if t == 0 :
self . visy [ v ] = 1
if self . cy [ v ] == - 1 or self . dfs ( self . cy [ v ]):
self . cx [ u ] = v
self . cy [ v ] = u
return True
elif t > 0 :
self . slack [ v ] = min ( self . slack [ v ], t )
return False
def KM ( self ):
for i in range ( 1 , self . cntx + 1 ):
for j in range ( 1 , self . cnty + 1 ):
if self . Map [ i ][ j ] == self . INF :
continue
self . wx [ i ] = max ( self . wx [ i ], self . Map [ i ][ j ])
for i in range ( 1 , self . cntx + 1 ):
self . slack = [ self . INF ] * ( self . maxn )
while True :
self . visx = [ 0 ] * ( self . maxn )
self . visy = [ 0 ] * ( self . maxn )
if self . dfs ( i ):
break
minz = self . INF
for j in range ( 1 , self . cnty + 1 ):
if not self . visy [ j ] and minz > self . slack [ j ]:
minz = self . slack [ j ]
for j in range ( 1 , self . cntx + 1 ):
if self . visx [ j ]:
self . wx [ j ] -= minz
for j in range ( 1 , self . cnty + 1 ):
if self . visy [ j ]:
self . wy [ j ] += minz
else :
self . slack [ j ] -= minz
ans = 0
for i in range ( 1 , self . cntx + 1 ):
if self . cx [ i ] != - 1 :
ans += self . Map [ i ][ self . cx [ i ]]
return ans
def add_edge ( self , u , v , w ):
self . Map [ u + 1 ][ v + 1 ] = w
连通块问题
2867. 统计树中的合法路径数目 - 力扣(LeetCode)
DFS + 字典维护节点所在连通块大小
cc_siz 用来记录连通块的大小。vis 数组对质数节点进行记录,dfs 的起始节点一定是质数节点的非质数子节点。
使用 cc_node 记录一次连通分量 dfs 得到的节点列表,更新对应 cc_siz 的值。这样后续在遍历到已经遍历过的非质数连通块时,可以直接得到结果。
def countPaths ( self , n : int , edges : List [ List [ int ]]) -> int :
primes = []
N = n + 10
is_prime = [ True ] * N
is_prime [ 0 ] = is_prime [ 1 ] = False
for i in range ( 2 , N ):
if is_prime [ i ]:
primes . append ( i )
for p in primes :
if i * p >= N :
break
is_prime [ i * p ] = False
if i % p == 0 :
break
e = [[] for _ in range ( n + 1 )]
for u , v in edges :
e [ u ] . append ( v )
e [ v ] . append ( u )
vis = [ False ] * ( n + 1 )
cc_siz = {}
cc_node = []
def dfs ( u , fa ):
siz = 1
cc_node . append ( u )
for v in e [ u ]:
if v != fa and not is_prime [ v ]:
siz += dfs ( v , u )
return siz
res = 0
for u in range ( 1 , n + 1 ):
if not vis [ u ] and is_prime [ u ]:
vis [ u ] = True
cur_siz = 0
for v in e [ u ]:
if is_prime [ v ]:
continue
# 对于每一个子连通分量
if v in cc_siz :
siz = cc_siz [ v ]
else :
cc_node . clear ()
siz = dfs ( v , u )
for node in cc_node :
cc_siz [ node ] = siz
res += siz + siz * cur_siz
cur_siz += siz
return res
DFS + 字典维护连通块的 AND 值 和 节点对应的连通块下标
100244. 带权图里旅途的最小代价 - 力扣(LeetCode)
通过字典中连通块下标,判断两个节点是否在同一连通块内。
def minimumCost ( self , n : int , edges : List [ List [ int ]], query : List [ List [ int ]]) -> List [ int ]:
cc_and = {} # 键为节点,值为 (cc_cnt, and_ans),即对应的连通块编号 和 连通块的 and 值
cc_cnt = 0 # 计数,记录当前统计到第几个连通块
cc_node = []
e = [{} for _ in range ( n )]
for u , v , w in edges :
if v not in e [ u ]:
e [ v ][ u ] = e [ u ][ v ] = w
else :
e [ v ][ u ] = e [ u ][ v ] = e [ u ][ v ] & w
vis = [ False ] * n
def dfs ( u ):
vis [ u ] = True
cc_node . append ( u )
and_ans = - 1
for v in e [ u ]:
w = e [ u ][ v ]
and_ans &= w
if not vis [ v ]:
and_ans &= dfs ( v )
return and_ans
for u in range ( n ):
if not vis [ u ]:
and_ans = dfs ( u )
for node in cc_node :
cc_and [ node ] = ( cc_cnt , and_ans )
cc_node . clear ()
cc_cnt += 1
return [ 0 if u == v else ( cc_and [ u ][ 1 ] if cc_and [ u ][ 0 ] == cc_and [ v ][ 0 ] else - 1 )
for u , v in query ]
并查集维护连通块属性
928. 尽量减少恶意软件的传播 II - 力扣(LeetCode)
题目问从 b a d bad ba d b a d bad ba d O ( n 3 ) O(n^3) O ( n 3 )
逆向思维:枚举所有的 g o o d good g oo d s i z siz s i z b a d bad ba d c c _ b a d cc\_bad cc _ ba d b a d bad ba d b a d bad ba d b a d bad ba d b a d bad ba d g o o d good g oo d
def minMalwareSpread ( self , graph : List [ List [ int ]], initial : List [ int ]) -> int :
n = len ( graph [ 0 ])
fa = list ( range ( n ))
siz = [ 1 ] * n
cc_bad = defaultdict ( set )
def find ( x ):
if fa [ x ] != x : fa [ x ] = find ( fa [ x ])
return fa [ x ]
def union ( u , v ):
if find ( u ) != find ( v ):
siz [ find ( u )] += siz [ find ( v )]
cc_bad [ find ( u )] |= cc_bad [ find ( v )]
fa [ find ( v )] = find ( u )
bad = set ( initial )
good = set ( range ( n )) - bad
for u in good :
for v , con in enumerate ( graph [ u ]):
if not con : continue
if v in bad : cc_bad [ find ( u )] . add ( v )
else : union ( u , v )
pa = set ( find ( u ) for u in good )
bad_siz = Counter ()
for p in pa :
if len ( cc_bad [ p ]) == 1 :
bad_siz [ list ( cc_bad [ p ])[ 0 ]] += siz [ p ]
mx , res = 0 , min ( bad )
for u , sz in bad_siz . items ():
if sz > mx : mx , res = sz , u
if sz == mx : res = min ( res , u )
return res
最小费用最大流
树上问题
倍增 LCA
f [ u ] [ i ] 表示 u 节点向上跳 2 i 的节点 f[u][i] 表示 u 节点 向上跳2^i\space 的节点 f [ u ] [ i ] 表示 u 节点向上跳 2 i 的节点 d e p [ u ] 表示深度 dep[u] \space 表示深度 d e p [ u ] 表示深度
MX = int ( n . bit_length ())
f = [[ 0 ] * ( MX + 1 ) for _ in range ( n )]
dep = [ 0 ] * n
def dfs ( u , fa ):
# father [u] = fa
dep [ u ] = dep [ fa ] + 1 # 递归节点深度
f [ u ][ 0 ] = fa
for i in range ( 1 , MX + 1 ): # 倍增计算向上跳的位置
f [ u ][ i ] = f [ f [ u ][ i - 1 ]][ i - 1 ]
for v in g [ u ]:
if v != fa :
dfs ( v , u )
# 假定 0 节点是树根
dep [ 0 ] = 1
for v in g [ 0 ]:
dfs ( v , 0 )
def lca ( u , v ):
if dep [ u ] < dep [ v ]:
u , v = v , u
# u 跳到和 v 同一层
for i in range ( MX , - 1 , - 1 ):
if dep [ f [ u ][ i ]] >= dep [ v ]:
u = f [ u ][ i ]
if u == v :
return u
# 跳到 lca 的下一层
for i in range ( MX , - 1 , - 1 ):
if f [ u ][ i ] != f [ v ][ i ]:
u , v = f [ u ][ i ], f [ v ][ i ]
return f [ u ][ 0 ]
P3379 【模板】最近公共祖先(LCA) - 洛谷 | 计算机科学教育新生态 (luogu.com.cn)
from math import log
import sys
input = lambda : sys . stdin . readline () . strip ()
n , m , s = map ( int , input () . split ())
# f [n][mx]
mx = int ( log ( n , 2 ))
f = [[ 0 ] * ( mx + 1 ) for _ in range ( n + 10 )]
e = [[] for _ in range ( n + 10 )]
dep = [ 0 ] * ( n + 10 )
dep [ s ] = 1
for _ in range ( n - 1 ):
u , v = map ( int , input () . split ())
e [ u ] . append ( v )
e [ v ] . append ( u )
def dfs ( u , fa ):
dep [ u ] = dep [ fa ] + 1
f [ u ][ 0 ] = fa
for i in range ( 1 , mx + 1 ):
f [ u ][ i ] = f [ f [ u ][ i - 1 ]][ i - 1 ]
for v in e [ u ]:
if v != fa :
dfs ( v , u )
for v in e [ s ]:
dfs ( v , s )
def lca ( u , v ):
# 让 u 往上跳
if dep [ u ] < dep [ v ]: u , v = v , u
for i in range ( mx , - 1 , - 1 ):
if dep [ f [ u ][ i ]] >= dep [ v ]:
u = f [ u ][ i ]
if u == v : return u
# 一定是在 lca 的下一层
# 一起跳
for i in range ( mx , - 1 , - 1 ):
if f [ u ][ i ] != f [ v ][ i ]:
u , v = f [ u ][ i ], f [ v ][ i ]
return f [ u ][ 0 ]
for _ in range ( m ):
a , b = map ( int , input () . split ())
print ( lca ( a , b ))
树上差分
点差分:解决多路径节点计数问题。
u → v 的路径转化为 u → l c a 左孩子 + l c a → v u \rightarrow v 的路径转化为 u \rightarrow lca左孩子 + lca \rightarrow v u → v 的路径转化为 u → l c a 左孩子 + l c a → v
# 差分时左闭右开,无需考虑啊 u = a 的情况
for u , v in query :
a = lca ( u , v )
diff [ u ] += 1
diff [ a ] -= 1
diff [ v ] += 1
if father [ a ] != - 1 :
diff [ father [ a ]] -= 1
树形 DP(换根 DP)
834. 树中距离之和 - 力扣(LeetCode)
题目详情 - Problem 4E. 最大社交深度和 - HydroOJ
1,指定某个节点为根节点。
2,第一次搜索完成预处理(如子树大小等),同时得到该节点的解。
3,第二次搜索进行换根的动态规划,由已知解的节点推出相连节点的解。
def sumOfDistancesInTree ( self , n : int , edges : List [ List [ int ]]) -> List [ int ]:
g = [[] for _ in range ( n )]
dep = [ 0 ] * n
siz = [ 1 ] * n
res = [ 0 ] * n
for u , v in edges :
g [ u ] . append ( v )
g [ v ] . append ( u )
def dfs1 ( u , fa ): # 预处理深度
dep [ u ] = dep [ fa ] + 1 if fa != - 1 else 0
for v in g [ u ]:
if v != fa :
dfs1 ( v , u )
siz [ u ] += siz [ v ]
def dfs2 ( u , fa ):
for v in g [ u ]:
if v != fa :
res [ v ] = res [ u ] - siz [ v ] + ( n - siz [ v ])
dfs2 ( v , u )
dfs1 ( 0 , - 1 )
res [ 0 ] = sum ( dep )
dfs2 ( 0 , - 1 )
return res
u u u n − s i z [ v ] n - siz[v] n − s i z [ v ]
v v v s i z [ v ] siz[v] s i z [ v ]
则状态转移方程 r e s [ v ] = r e s [ u ] − s i z [ v ] + ( n − s i z [ v ] ) res[v] = res[u] - siz[v] + (n - siz[v]) res [ v ] = res [ u ] − s i z [ v ] + ( n − s i z [ v ])
树上异或
性质 1:对树上一条路径 u → x 0 → x 1 → ⋯ → v u \rightarrow x_0 \rightarrow x_1 \rightarrow \cdots \rightarrow v u → x 0 → x 1 → ⋯ → v
因而树上相邻异或 等价于 树上任意两点进行异或
性质 2:在树上任意相邻异或,总是有 偶数 个节点被异或。
3068. 最大节点价值之和 - 力扣(LeetCode)
class Solution :
def maximumValueSum ( self , nums : List [ int ], k : int , edges : List [ List [ int ]]) -> int :
res = sum ( nums )
delta = sorted ([( x ^ k ) - x for x in nums ], reverse = True )
for du , dv in zip ( delta [:: 2 ], delta [ 1 :: 2 ]):
res = max ( res , res + du + dv )
return res
树上直径
时间复杂度:O ( n ) O(n) O ( n )
定义:树上任意两节点之间最长的简单路径即为树的「直径」。
定理:
对于无负边权的树,从树的任意节点出发寻找到距离最远的节点,一定是树直径的一个端点。 (反证)
方法一:两次 dfs
def treeDiameter ( self , edges : List [ List [ int ]]) -> int :
n = len ( edges ) + 1
e = [[] for _ in range ( n + 1 )]
for u , v in edges :
e [ u ] . append ( v )
e [ v ] . append ( u )
def dfs ( u , fa ):
res , mxv = 0 , u
for v in e [ u ]:
if v == fa : continue
a , b = dfs ( v , u )
if a + 1 > res :
res , mxv = a + 1 , b
return res , mxv
_ , s = dfs ( 0 , - 1 )
res , _ = dfs ( s , - 1 )
return res
方法二:树形 DP
返回每个节点 的最长路径 fst 和 与最长路径没有公共边的次长路径 sec,取 max(fst + sec)
def treeDiameter ( self , edges : List [ List [ int ]]) -> int :
n = len ( edges ) + 1
e = [[] for _ in range ( n + 1 )]
for u , v in edges :
e [ u ] . append ( v )
e [ v ] . append ( u )
res = 0
def dfs ( u , fa ):
nonlocal res
# 找出节点 u 为子树的最长 / 次长路径
fst = sec = - 1
for v in e [ u ]:
if v == fa : continue
a , _ = dfs ( v , u )
if a >= fst :
fst , sec = a , fst
else :
sec = max ( a , sec )
res = max ( fst + sec + 2 , res )
return fst + 1 , sec + 1
dfs ( 0 , - 1 )
return res
310. 最小高度树 - 力扣(LeetCode)
树的直径问题,最小高度树的根一定在树的直径上。
def findMinHeightTrees ( self , n : int , edges : List [ List [ int ]]) -> List [ int ]:
e = [[] for _ in range ( n )]
for u , v in edges :
e [ u ] . append ( v )
e [ v ] . append ( u )
# 确定以 x 为根
pa = [ - 1 ] * n
def dfs ( u , fa ):
pa [ u ] = fa
res , mxv = 0 , u
for v in e [ u ]:
if v == fa :
continue
a , b = dfs ( v , u )
if a + 1 > res :
res , mxv = a + 1 , b
return res , mxv
_ , x = dfs ( 0 , - 1 )
dis , y = dfs ( x , - 1 )
path = []
while y != - 1 :
path . append ( y )
y = pa [ y ]
res = [ path [ dis // 2 ]]
if dis & 1 :
res . append ( path [ dis // 2 + 1 ])
return res
位运算
位运算与集合论
集合 A , B A, B A , B N N N
(1). 把 b 位置为 1
通过 或 实现
(2). 把 b 位置清零
通过 与非 实现
(3). 获得一个数从高到低的每一位的值
1261. 在受污染的二叉树中查找元素 - 力扣(LeetCode)
class FindElements :
def __init__ ( self , root : Optional [ TreeNode ]):
self . root = root
def find ( self , target : int ) -> bool :
target += 1
node = self . root
for b in range ( target . bit_length () - 2 , - 1 , - 1 ):
x = ( target >> b ) & 1
node = node . right if x else node . left
if not node : return False
return True
二维矩阵 压缩为一维二进制串
num = sum (( ch == '.' ) << i for i , ch in enumerate ( s )) # 010110
满足 n u m > > x = = s [ i ] num >> x == s[i] n u m >> x == s [ i ]
s = [ "#" , "." , "." , "#" , "." , "#" ]
num = sum (( ch == '.' ) << i for i , ch in enumerate ( s )) # 010110
print ( bin ( num )) # 0b 010110
预处理所有子集的和
时间复杂度:O ( n ⋅ 2 n ) O(n\cdot 2^n) O ( n ⋅ 2 n )
sum_ = defaultdict ( int )
for i , x in enumerate ( nums ):
for s in range ( 1 << i ):
sum_ [( 1 << i ) | s ] = sum_ [ s ] + x
从大到小枚举一个 s s s
暴力做法是从 s s s s s s 101000 → 100111 101000 \rightarrow1 00111 101000 → 100111 101000 → 100101 ,假设 s = 111101 ) 101000 \rightarrow 100101,假设 s = 111101) 101000 → 100101 ,假设 s = 111101 ) & s \& s & s
sub = s
while sub :
# 处理 sub 的逻辑
sub = ( sub - 1 ) & s
Gosper's Hack:枚举大小恰好为 k k k
例如当前为 0100110 0100110 0100110 3 3 3 0101001 0101001 0101001 l e f t = 0101000 left = 0101000 l e f t = 0101000 s u b + l o w b i t ( s u b ) sub + lowbit(sub) s u b + l o w bi t ( s u b ) r i g h t = 000001 right =000001 r i g h t = 000001 l e f t ⊕ s u b = 0001111 left \oplus sub=0001111 l e f t ⊕ s u b = 0001111 r i g h t = l e f t ⊕ s u b right =left \oplus sub r i g h t = l e f t ⊕ s u b 2 / l o w b i t ( s u b ) 2 / lowbit(sub) 2/ l o w bi t ( s u b )
时间复杂度:O ( n ⋅ C ( n , k ) ) O(n \cdot C(n,k)) O ( n ⋅ C ( n , k ))
s = ( 1 << n ) - 1
sub = ( 1 << k ) - 1
def next_sub ( x ):
lb = x & - x
left = x + lb
right = (( left ^ x ) >> 2 ) // lb
return left | right
while sub <= s :
# 处理 sub 逻辑
sub = next_sub ( sub )
判断是否有两个连续(相邻)的 1
( s & ( s >> 1 )) == 0 # 为 True 是表示没有两个连续的 1
或者
( s & ( s << 1 )) == 0
十进制长度
m = int ( log ( n + 1 , 10 )) + 1
二进制长度
二进制中 1 的数量
十进制 int 转换 对应二进制的 int
def bin ( x ):
res = 0
i = 0
while x :
res = res + pow ( 10 , i ) * ( x % 2 )
x >>= 1
i += 1
return res
十进制转 − 2 -2 − 2
1017. 负二进制转换 - 力扣(LeetCode)
def baseNeg2 ( self , n : int ) -> str :
if n == 0 : return '0'
res = []
while n :
if n & 1 : x = 1
else : x = 0
n = ( n - x ) // - 2
res . append ( str ( x ))
return '' . join ( res [:: - 1 ])
最大异或
def findMaximumXOR ( self , nums : List [ int ]) -> int :
n = max ( nums ) . bit_length ()
res = mask = 0
for i in range ( n - 1 , - 1 , - 1 ):
mask |= 1 << i
s , tmp = set (), res | ( 1 << i )
for x in nums : # x ^ a = tmp -> a = tmp ^ x
x &= mask
if tmp ^ x in s :
res = tmp
break
s . add ( x )
return res
拆位试填法
当发现题目要求所有元素按位运算得到的 最值 问题时,从高位开始考虑是否能为 1/0 。
考虑过的状态记录在 res 中,不考虑的位用 mask 置为 0 表示。
mask = res = 0
for b in range ( n , - 1 , - 1 ):
mask |= 1 << b # 蒙版
for x in nums :
x &= mask
# 最大值 ...
res |= 1 << b # 得到最大值
mask &= ~ ( 1 << b ) # 该位自由,不用考虑
3022 给定操作次数内使剩余元素的或值最小
https://leetcode.cn/problems/minimize-or-of-remaining-elements-using-operations/
mask = res = 0
for b in range ( n , - 1 , - 1 ):
mask |= 1 << b
ans_res = - 1 # 初始值全是 1
cnt = 0
for x in nums :
ans_res &= x & mask
if ans_res > 0 :
cnt += 1
else :
ans_res = - 1 # 重置初始值
if cnt > k : # 说明这一位必然是 1
# mask 这位蒙版就应置为 0,表示后续都不考虑这位
mask &= ~ ( 1 << b )
res |= 1 << b
return res
动态规划
DP 题单(LeetCode)
入门 dp
70. 爬楼梯 - 力扣(LeetCode)
递归写法
class Solution :
def climbStairs ( self , n : int ) -> int :
def dfs ( n ):
return 1 if n == 1 or n == 0 else dfs ( n - 1 ) + dfs ( n - 2 )
return dfs ( n )
记忆化搜索:lru_cache
from functools import *
class Solution :
def climbStairs ( self , n : int ) -> int :
@lru_cache ( maxsize = None )
def dfs ( n ):
return 1 if n == 1 or n == 0 else dfs ( n - 1 ) + dfs ( n - 2 )
return dfs ( n )
s = Solution ()
print ( s . climbStairs ( 3 )) # 3
198. 打家劫舍 - 力扣(LeetCode)
选或者不选
f [ i ] [ 1 ] f[i][1] f [ i ] [ 1 ] i i i i i i f [ i ] [ 0 ] f[i][0] f [ i ] [ 0 ] i i i i i i f [ i ] [ 0 ] = max(f[i - 1][1], f[i - 1][0]) f[i][0] = \text{max(f[i - 1][1], f[i - 1][0])} f [ i ] [ 0 ] = max(f[i - 1][1], f[i - 1][0]) f [ i ] [ 1 ] = f[i - 1][0] + nums[i - 1] f[i][1] = \text{f[i - 1][0] + nums[i - 1]} f [ i ] [ 1 ] = f[i - 1][0] + nums[i - 1]
class Solution :
def rob ( self , nums : List [ int ]) -> int :
n = len ( nums )
f = [[ 0 ] * 2 for _ in range ( n + 1 )]
for i in range ( 1 , n + 1 ):
f [ i ][ 0 ] = max ( f [ i - 1 ][ 1 ], f [ i - 1 ][ 0 ])
f [ i ][ 1 ] = f [ i - 1 ][ 0 ] + nums [ i - 1 ]
return max ( f [ n ][ 1 ], f [ n ][ 0 ])
线性 dp
最长上升子序列
O ( n 2 ) O(n^2) O ( n 2 ) f [ i ] f[i] f [ i ] n u m s [ i ] nums[i] n u m s [ i ]
for i , x in enumerate ( nums ):
for j in range ( i ):
if nums [ j ] < x :
f [ i ] = max ( f [ i ], f [ j ] + 1 )
O ( n l o g n ) O(nlogn) O ( n l o g n ) f [ i ] f[i] f [ i ] i i i
正序遍历 n u m s nums n u m s x x x x x x f f f x x x
# f [i] 表示长度为 i 的子序列的末尾元素的最小值
f = []
# 找到恰好大于 x 的位置
def check ( x , mid ):
return f [ mid ] >= x
for x in nums :
lo , hi = 0 , len ( f )
while lo < hi :
mid = ( lo + hi ) >> 1
if check ( x , mid ):
hi = mid
else :
lo = mid + 1
if lo >= len ( f ):
f . append ( x )
else :
f [ lo ] = x
最长公共子序列
f [ i ] [ j ] 表示从 s [ 0 : i ] 和 s 2 [ 0 : j ] 中的最长公共子序列 f[i][j] 表示从s[0: i] 和 s2[0: j] 中的最长公共子序列 f [ i ] [ j ] 表示从 s [ 0 : i ] 和 s 2 [ 0 : j ] 中的最长公共子序列
时间复杂度:O ( m n ) O(mn) O ( mn )
可以证明:f ( i − 1 , j − 1 ) + 1 ≥ max ( f ( i − 1 , j ) , f ( i , j − 1 ) ) f(i-1, j -1)+ 1 \ge \max(f(i-1,j), ~f(i,~j-1)) f ( i − 1 , j − 1 ) + 1 ≥ max ( f ( i − 1 , j ) , f ( i , j − 1 ))
# f [n][m]
f = [[ 0 ] * ( m + 1 ) for _ in range ( n + 1 )]
for i in range ( 1 , n + 1 ):
for j in range ( 1 , m + 1 ):
if s1 [ i - 1 ] == s2 [ j - 1 ]:
f [ i ][ j ] = f [ i - 1 ][ j - 1 ] + 1
else :
f [ i ][ j ] = max ( f [ i - 1 ][ j ], f [ i ][ j - 1 ])
编辑距离
def getEditDist ( s1 , s2 ):
m , n = len ( s1 ), len ( s2 )
f = [[ inf ] * ( n + 1 ) for _ in range ( m + 1 )]
for i in range ( 1 , m + 1 ): f [ i ][ 0 ] = i
for i in range ( 1 , n + 1 ): f [ 0 ][ i ] = i
f [ 0 ][ 0 ] = 0
for i in range ( 1 , m + 1 ):
for j in range ( 1 , n + 1 ):
a = f [ i - 1 ][ j ] + 1
b = f [ i ][ j - 1 ] + 1
c = f [ i - 1 ][ j - 1 ] + ( 1 if s1 [ i - 1 ] != s2 [ j - 1 ] else 0 )
f [ i ][ j ] = min ( a , b , c )
return f [ m ][ n ]
背包问题
N N N v i v_i v i w i w_i w i W W W
0 - 1 背包:每个物品用 0 或者 1 次。
完全背包:每个物品可以用 0 到 + ∞ +\infty + ∞
多重背包:每个物品最多 s i s_i s i
分组背包:物品分为若干组,每一组里面选 0 或者 1 次。
0 - 1 背包
状态表示:f ( i , j ) f(i, j) f ( i , j )
最终求解的问题 f ( N , W ) f(N, W) f ( N , W )
状态计算:
集合的划分问题:如何将集合 f ( i , j ) f(i,j) f ( i , j )
# f [i][j] 表示用前 i 个物品,在总重量不超过 j 的情况下,所有物品选法构成的集合中,总价值的最大值
# 考虑 f [i][j] 对应集合的完备划分: 选 i ,其子集的最大值是 f [i - 1][j - w[i]] + v [i],需要在 j - w [i] >= 0 满足
# 不选 i, 其子集的最大值是 f [i - 1][j]。一定可以满足
f = [[ 0 ] * ( W + 1 ) for _ in range ( N + 1 )]
for i in range ( 1 , N + 1 ):
for j in range ( 1 , W + 1 ):
if j - w [ i ] >= 0 : # 可以选i,也可以不选i
f [ i ][ j ] = max ( f [ i - 1 ][ j ], f [ i - 1 ][ j - w [ i ]] + v [ i ])
else :
f [ i ][ j ] = f [ i - 1 ][ j ] # 只能不选i
print ( f [ N ][ W ])
滚动数组优化为一维:逆序遍历
由于 f ( i , j ) f(i, j) f ( i , j ) f ( i − 1 , j ) f(i-1, j) f ( i − 1 , j ) f ( j ) f(j) f ( j ) i i i j j j f ( j ) f(j) f ( j ) f ( j ′ < j ) f(j'< j) f ( j ′ < j ) f ( i , j ′ ) f(i,j') f ( i , j ′ ) f ( j ′ ′ ≥ j ) f(j''\geq j) f ( j ′′ ≥ j ) f ( i − 1 , j ′ ′ ) f(i-1,j'') f ( i − 1 , j ′′ )
由于我们希望能够得到 f ( i − 1 , j − w [ i ] ) f(i-1, j - w[i]) f ( i − 1 , j − w [ i ]) j j j f ( j ) f(j) f ( j ) f ( j ′ ≤ j ) f(j'\leq j) f ( j ′ ≤ j ) f ( i − 1 , j ′ ) f(i-1, j') f ( i − 1 , j ′ )
所以 j j j r a n g e ( W , w [ i ] − 1 , − 1 ) range(W, w[i]-1, -1) r an g e ( W , w [ i ] − 1 , − 1 )
f = [ 0 ] * ( W + 1 )
for i in range ( 1 , N + 1 ):
for j in range ( W , w [ i ] - 1 , - 1 ):
f [ j ] = max ( f [ j ], f [ j - w [ i ]] + v [ i ])
# 此时 f [j] 就代表 f [i - 1][j], f [j - w[i] 代表 f [i - 1][j - w[i]]
return f [ W ]
NOIP 2005 普及组] 采药 - 洛谷 (luogu.com.cn)
import sys
input = lambda : sys . stdin . readline () . strip ()
W , N = map ( int , input () . split ())
w , v = [ 0 ] * ( N + 1 ), [ 0 ] * ( N + 1 )
for i in range ( 1 , N + 1 ):
w [ i ], v [ i ] = map ( int , input () . split ())
# f[i][j] 表示在前i个物品中,重量不超过j的所有选择方案的集合中,获得的最大价值
# 最终要求 f[N][W]
f = [[ 0 ] * ( W + 1 ) for _ in range ( N + 1 )]
for i in range ( 1 , N + 1 ):
for j in range ( 1 , W + 1 ):
if j - w [ i ] >= 0 : # 可以选i,也可以不选i
f [ i ][ j ] = max ( f [ i - 1 ][ j ], f [ i - 1 ][ j - w [ i ]] + v [ i ])
else :
f [ i ][ j ] = f [ i - 1 ][ j ] # 只能不选i
print ( f [ N ][ W ])
题目详情 - LC2431. 最大限度地提高购买水果的口味 - HydroOJ
增加限制条件:不超过 k 次使用折扣券。注意,k 的遍历方向也是逆序。
def maxTastiness ( self , price : List [ int ], tastiness : List [ int ], maxAmount : int , maxCoupons : int ) -> int :
# f [i][j] [k] 从前 i 个物品,不超过容量 j 的情况下,不超过 k 张券的最大价值
# f [i][j] [k] = max(f [i - 1][j] [k], f [i - 1][j - w] [k] + v, f [i - 1][j - w // 2] [k - 1] + v)
f = [[ 0 ] * ( maxCoupons + 1 ) for _ in range ( maxAmount + 1 )]
for w , v in zip ( price , tastiness ):
for j in range ( maxAmount , w // 2 - 1 , - 1 ):
for k in range ( maxCoupons , - 1 , - 1 ):
if j - w >= 0 :
f [ j ][ k ] = max ( f [ j ][ k ], f [ j - w ][ k ] + v )
if k >= 1 :
f [ j ][ k ] = max ( f [ j ][ k ], f [ j - w // 2 ][ k - 1 ] + v )
return f [ maxAmount ][ maxCoupons ]
恰好装满型 0 - 1 背包
2915. 和为目标值的最长子序列的长度 - 力扣(LeetCode)
f [ i ] [ j ] = m a x ( f [ i − 1 ] [ j ] , f [ i − 1 ] [ j − w ] + v )
f [i][j] = max(f [i - 1][j], ~ f [i - 1][j - w] + v)
f [ i ] [ j ] = ma x ( f [ i − 1 ] [ j ] , f [ i − 1 ] [ j − w ] + v ) 第二个转移的条件是:
f [ i − 1 ] [ j − w ] > 0 或者 f [ i − 1 ] [ j − w ] = 0 且 w = j
f [i - 1][j - w] > 0 \text{ 或者 } f [i - 1][j - w] = 0 \text{ 且 } ~w = j
f [ i − 1 ] [ j − w ] > 0 或者 f [ i − 1 ] [ j − w ] = 0 且 w = j 可以通过初始值修改,将不合法的 f [ i ] [ j ] f[i][j] f [ i ] [ j ] − ∞ -\infty − ∞ f [ i ] [ j ] ≥ 0 f[i][j] \ge 0 f [ i ] [ j ] ≥ 0 f [ 0 ] [ 0 ] = 0 f[0][0] =0 f [ 0 ] [ 0 ] = 0
得到二维版本:
class Solution :
def lengthOfLongestSubsequence ( self , nums : List [ int ], t : int ) -> int :
a = nums
n = len ( nums )
dp = [[ - inf ] * ( t + 1 ) for _ in range ( n + 1 )]
for i in range ( n + 1 ): dp [ i ][ 0 ] = 0
for i in range ( 1 , n + 1 ):
w = a [ i - 1 ]
for j in range ( t + 1 ):
if j >= w :
dp [ i ][ j ] = max ( dp [ i - 1 ][ j ], dp [ i - 1 ][ j - w ] + 1 )
else :
dp [ i ][ j ] = dp [ i - 1 ][ j ]
if dp [ n ][ t ] >= 0 :
return dp [ n ][ t ]
else :
return - 1
优化:j j j min ( 重量前缀 , t a r g e t ) \min(\text{重量前缀}, target) min ( 重量前缀 , t a r g e t )
def lengthOfLongestSubsequence ( self , nums : List [ int ], target : int ) -> int :
f = [ 0 ] + [ - inf ] * target
pre = 0
for w in nums :
pre += w
for j in range ( min ( pre , target ), w - 1 , - 1 ):
f [ j ] = max ( f [ j ], f [ j - w ] + 1 )
return f [ target ] if f [ target ] >= 0 else - 1
1.蓝桥课程抢购 - 蓝桥云课 (lanqiao.cn)
定义 m x = max ( B ) mx =\max(B) m x = max ( B ) [ 0 , m x ] [0, mx] [ 0 , m x ] B B B
定义 d [ i ] [ j ] d [i][j] d [ i ] [ j ] i i i j j j
如果第 i i i d [ i ] [ j ] = m a x ( d [ i − 1 ] [ j − b ] + c , d [ − 1 i ] [ j ] ) d [i][j] = max(d [i - 1][j - b] + c, d [-1i][j]) d [ i ] [ j ] = ma x ( d [ i − 1 ] [ j − b ] + c , d [ − 1 i ] [ j ]) j j j [ a , b ] [a, b] [ a , b ]
d 的维度:( n + 1 ) ⋅ ( m x + 1 ) (n + 1) \cdot (mx + 1) ( n + 1 ) ⋅ ( m x + 1 )
时间复杂度:O ( n × max ( B ) ) O(n\times \max(B)) O ( n × max ( B ))
import sys
input = lambda : sys . stdin . readline () . strip ()
n = int ( input ())
nums = []
for _ in range ( n ):
a , b , c = map ( int , input () . split ())
nums . append (( a , b , c ))
# 按照 B 排序
nums . sort ( key = lambda x : x [ 1 ])
# 所有项一定在 [0, mx] 内开始执行
mx = nums [ - 1 ][ 1 ]
d = [[ 0 ] * ( mx + 1 ) for _ in range ( n + 1 )]
for i in range ( 1 , n + 1 ):
a , b , c = nums [ i - 1 ]
for j in range ( 1 , mx + 1 ):
if a <= j <= b : # “选”
d [ i ][ j ] = max ( d [ i - 1 ][ j - a ] + c , d [ i - 1 ][ j ])
else :
d [ i ][ j ] = d [ i - 1 ][ j ]
print ( max ( d [ n ]))
滚动数组优化空间
import sys
input = lambda : sys . stdin . readline () . strip ()
n = int ( input ())
nums = []
for _ in range ( n ):
a , b , c = map ( int , input () . split ())
nums . append (( a , b , c ))
nums . sort ( key = lambda x : x [ 1 ])
mx = nums [ - 1 ][ 1 ]
d = [ 0 ] * ( mx + 1 )
for i in range ( 1 , n + 1 ):
a , b , c = nums [ i - 1 ]
for j in range ( b , a - 1 , - 1 ):
d [ j ] = max ( d [ j ], d [ j - a ] + c )
print ( max ( d ))
分割等和子集问题
给定一组数,判断是否可以分割成两个等和子集。
416. 分割等和子集 - 力扣(LeetCode)
def canPartition ( self , nums : List [ int ]) -> bool :
s , n = sum ( nums ), len ( nums )
if s & 1 : return False
# f [i][j] 表示从前 i 个数中,分割成和为 j 是否可能。
# f [n][s // 2]
f = [ 1 ] + [ 0 ] * ( s // 2 )
for x in nums :
for j in range ( s // 2 , x - 1 , - 1 ):
f [ j ] |= f [ j - x ]
return f [ s // 2 ] == 1
完全背包
**状态表示:f ( i , j ) f(i, j) f ( i , j )
状态计算: 对于集合的划分,按照第 i i i 0 , 1 , . . . , 0, 1, ... , 0 , 1 , ... ,
朴素做法:O ( N ⋅ W 2 ) O(N\cdot W^2) O ( N ⋅ W 2 )
for i in range ( 1 , N + 1 ):
for j in range ( W + 1 ):
for k in range ( j // w [ i ] + 1 ):
f [ i ][ j ] = max ( f [ i ][ j ], f [ i - 1 ][ j - k * w [ i ]] + k * v [ i ])
return f [ N ][ W ]
冗余优化 :O ( N ⋅ W ) O(N \cdot W) O ( N ⋅ W )
可以发现后面一坨的最大值等价于 f ( i , j − w ) f(i, j - w) f ( i , j − w )
f [ i , j ] = M a x ( f [ i − 1 , j ] , f [ i − 1 , j − w ] + v , f [ i − 1 , j − 2 w ] + 2 v , f [ i − 1 , j − 3 w ] + 3 v , . . . ) f [ i , j − w ] = M a x ( f [ i − 1 , j − w ] , f [ i − 1 , j − 2 w ] + v , f [ i − 1 , j − 3 w ] + 2 v , . . . )
\begin{align}
f [i, j]~ &=~Max(f [i-1, j],& &f [i-1, j-w]+v,& &~f [i-1, j-2w]+2v,& &~f [i-1, j-3w]+3v &,...) \\
f [i, j-w]~ &= ~Max( & &f [i-1, j-w],& &~f [i-1, j-2w]+v,& &~f [i-1, j-3w]+2v, &...)
\end{align}
f [ i , j ] f [ i , j − w ] = M a x ( f [ i − 1 , j ] , = M a x ( f [ i − 1 , j − w ] + v , f [ i − 1 , j − w ] , f [ i − 1 , j − 2 w ] + 2 v , f [ i − 1 , j − 2 w ] + v , f [ i − 1 , j − 3 w ] + 3 v f [ i − 1 , j − 3 w ] + 2 v , , ... ) ... ) 所以 f ( i , j ) = max ( f ( i − 1 , j ) , f ( i , j − w [ i ] ) + v [ i ] ) f(i, j) = \max \big(f(i - 1, j), f(i, j - w[i]) + v[i] \big) f ( i , j ) = max ( f ( i − 1 , j ) , f ( i , j − w [ i ]) + v [ i ] )
for i in range ( 1 , N + 1 ):
for j in range ( W + 1 ):
f [ i ][ j ] = f [ i - 1 ][ j ]
if j - w [ i ] >= 0 :
f [ i ][ j ] = max ( f [ i ][ j ], f [ i ][ j - w [ i ]] + v [ i ])
# f [i][j - w[i]] 包含了 f [i - 1][j - k * w[i]] 的部分 (k >= 1)
return f [ N ][ W ]
优化为一维
for i in range ( 1 , N + 1 ):
for j in range ( w [ i ], W + 1 ):
f [ j ] = max ( f [ j ], f [ j - w [ i ]] + v [ i ])
518. 零钱兑换 II - 力扣(LeetCode)
完全背包求组合方案数
f [ i , j ] = ∑ ( f [ i − 1 , j ] , f [ i − 1 , j − w ] + v , f [ i − 1 , j − 2 w ] + 2 v , f [ i − 1 , j − 3 w ] + 3 v , . . . ) f [ i , j − w ] = ∑ ( f [ i − 1 , j − w ] , f [ i − 1 , j − 2 w ] + v , f [ i − 1 , j − 3 w ] + 2 v , . . . )
\begin{align}
f [i, j]~ &=~\sum(f [i-1, j],& &f [i-1, j-w]+v,& &~f [i-1, j-2w]+2v,& &~f [i-1, j-3w]+3v &,...) \\
f [i, j-w]~ &= ~\sum( & &f [i-1, j-w],& &~f [i-1, j-2w]+v,& &~f [i-1, j-3w]+2v, &...)
\end{align}
f [ i , j ] f [ i , j − w ] = ∑ ( f [ i − 1 , j ] , = ∑ ( f [ i − 1 , j − w ] + v , f [ i − 1 , j − w ] , f [ i − 1 , j − 2 w ] + 2 v , f [ i − 1 , j − 2 w ] + v , f [ i − 1 , j − 3 w ] + 3 v f [ i − 1 , j − 3 w ] + 2 v , , ... ) ... ) f [ i , j ] = ∑ ( f [ i − 1 , j ] , f [ i , j − c ] ) f [ i , j − c ] = ∑ ( f [ i − 1 , j − c ] , f [ i , j − 2 ⋅ c ] )
\begin{align}
f [i, j]~ &=~\sum (f [i-1, j],& &~f [i, j-c] ) \\
f [i, j-c]~ &= ~\sum(f [i-1, j-c],& &~f [i, j- 2 \cdot c])
\end{align}
f [ i , j ] f [ i , j − c ] = ∑ ( f [ i − 1 , j ] , = ∑ ( f [ i − 1 , j − c ] , f [ i , j − c ]) f [ i , j − 2 ⋅ c ]) def change ( self , amount : int , coins : List [ int ]) -> int :
# f [i][j] 表示 前 i 个硬币凑出 j 的方案数
# 状态表示:从前 i 个硬币中组合出 j 的所有方案的集合
# 属性:个数
# 转移:对集合进行划分。
# f [i][j] = f [i - 1][j] + f [i][j - c]
n = len ( coins )
f = [[ 0 ] * ( amount + 1 ) for _ in range ( n + 1 )]
# f [i][0] = 1
for i in range ( n + 1 ): f [ i ][ 0 ] = 1
for i in range ( 1 , n + 1 ):
for j in range ( 1 , amount + 1 ):
c = coins [ i - 1 ]
f [ i ][ j ] = f [ i - 1 ][ j ]
if j - c >= 0 :
f [ i ][ j ] += f [ i ][ j - c ]
return f [ n ][ amount ]
优化成一维:
def change ( self , amount : int , coins : List [ int ]) -> int :
# f [i][j] = f [i - 1][j] + f [i][j - c]
n = len ( coins )
# 从前 i 个中构成 j 的方案数
f = [ 0 ] * ( amount + 1 )
f [ 0 ] = 1
for c in coins :
for j in range ( c , amount + 1 ):
f [ j ] += f [ j - c ]
return f [ amount ]
求排列方案数:伪完全背包
377. 组合总和 Ⅳ - 力扣(LeetCode)
f ( i ) f(i) f ( i ) i i i f ( i ) = ∑ f ( i − w ) f(i)=\sum f(i-w) f ( i ) = ∑ f ( i − w )
def combinationSum4 ( self , nums : List [ int ], target : int ) -> int :
n = len ( nums )
f = [ 0 ] * ( target + 1 )
f [ 0 ] = 1
for i in range ( 1 , target + 1 ):
for j in range ( n ):
w = nums [ j ]
if i - w >= 0 :
f [ i ] += f [ i - w ]
return f [ target ]
1449. 数位成本和为目标值的最大数字 - 力扣(LeetCode)
每个数字有一个重量,可以无限选,问恰好重量为 target 的最大数字。(类似题目:长度最大的字典序最小串等)
先用完全背包模型求出最长长度,然后贪心的从 9~1 倒序遍历逆序构造。构造的条件是 f [ t a r g e t − w ] + 1 = f [ t a r g e t ] f[target-w]+1 = f[target] f [ t a r g e t − w ] + 1 = f [ t a r g e t ]
def largestNumber ( self , cost : List [ int ], target : int ) -> str :
# 先求出能构成的最长数串
# 每个物品重量 W, 价值为 1,
# f [i][j] 表示从前 i 个物品中选法中,能够构成的最大价值
# f [i][j] = max(f [i][j], f [i][j - w])
f = [ 0 ] + [ - inf ] * target
for w in cost :
for j in range ( w , target + 1 ):
f [ j ] = max ( f [ j ], f [ j - w ] + 1 )
mxl = f [ target ]
if mxl <= 0 : return '0'
res = ''
# 贪心的构造,从高位到低位尽可能构造
for x in range ( 9 , - 1 , - 1 ):
w = cost [ x - 1 ]
while target - w >= 0 and f [ target ] == f [ target - w ] + 1 :
res += str ( x )
target -= w
return res
多重背包
在完全背包的基础上,增加每个物品最多选择选择的次数限制 s [ i ] s[i] s [ i ]
暴力做法:O ( N ⋅ W 2 ) O(N \cdot W ^2) O ( N ⋅ W 2 )
for i in range ( 1 , n + 1 ):
for j in range ( W + 1 ):
for k in range ( min ( c [ i ] + 1 , j // w [ i ] + 1 )):
f [ i ][ j ] = max ( f [ i ][ j ], f [ i - 1 ][ j - k * w [ i ]] + k * v [ i ])
f ( i , j ) = max ( f ( i − 1 , j ) , f ( i − 1 , j − w ) + v , ⋯ , f ( i − 1 , j − c ⋅ w ) + c ⋅ v ) ) f ( i , j − w ) = max ( f ( i − 1 , j − w ) , ⋯ , f ( i − 1 , j − c ⋅ w ) + ( c − 1 ) ⋅ v ) , f ( i − 1 , j − ( c + 1 ) ⋅ w ) + c ⋅ v ) )
\begin{aligned}
f(i, j)=\max (f(i - 1, j), &f(i-1,~ j-w)+v,& ~\cdots , &~ f(i-1,~ j - c \cdot w) + c \cdot v))& \\
f(i, j - w)=\max( &f(i-1,~ j-w),& ~\cdots , &~ f(i-1,~ j - c \cdot w) + (c-1) \cdot v),& ~f(i-1, j - (c + 1) \cdot w) + c \cdot v))
\end{aligned}
f ( i , j ) = max ( f ( i − 1 , j ) , f ( i , j − w ) = max ( f ( i − 1 , j − w ) + v , f ( i − 1 , j − w ) , ⋯ , ⋯ , f ( i − 1 , j − c ⋅ w ) + c ⋅ v )) f ( i − 1 , j − c ⋅ w ) + ( c − 1 ) ⋅ v ) , f ( i − 1 , j − ( c + 1 ) ⋅ w ) + c ⋅ v )) 可以发现无法借助完全背包的方法进行优化。
二进制拆分重量为新的包裹 :O ( N ⋅ W ⋅ l o g ( ∑ W ) ⋅ ) O(N \cdot W\cdot log(\sum W) \cdot ) O ( N ⋅ W ⋅ l o g ( ∑ W ) ⋅ )
思路:将每一件最多能选 c c c 1 , 2 , ⋯ , 2 k , c ′ 1, 2, \cdots, 2^k, c' 1 , 2 , ⋯ , 2 k , c ′ c = 500 c=500 c = 500 1 , 2 , ⋯ , 128 , 245 1, 2, \cdots, 128,245 1 , 2 , ⋯ , 128 , 245 0 ∼ 500 0 \sim 500 0 ∼ 500
可以估算,总包裹的个数不超过 N ⋅ l o g 2 ( ∑ W ) N \cdot log_2{(\sum W)} N ⋅ l o g 2 ( ∑ W )
W , V = [], []
for _ in range ( N ):
ow , ov , oc = map ( int , input () . split ())
k = 1
while oc >= k : # 例如 10, 拆分成 1,2,4 和 3
W , V = W + [ ow * k ], V + [ ov * k ]
oc -= k
k <<= 1
if oc > 0 :
W , V = W + [ ow * oc ], V + [ ov * oc ]
f = [ 0 ] * ( mxW + 1 )
for w , v in zip ( W , V ):
for j in range ( mxW , w - 1 , - 1 ):
f [ j ] = max ( f [ j ], f [ j - w ] + v )
print ( f [ mxW ])
分组背包
9. 分组背包问题 - AcWing 题库
有 N N N m x W mxW m x W
f ( i , j ) f(i, j) f ( i , j ) i i i j j j
状态转移:第 i i i f ( i − 1 , j ) f(i-1,j) f ( i − 1 , j ) i i i k k k f ( i − 1 , j − w [ i ] [ k ] ) + v [ i ] [ k ] f(i-1,j-w[i][k]) + v[i][k] f ( i − 1 , j − w [ i ] [ k ]) + v [ i ] [ k ]
W , V = [[ 0 ] for _ in range ( N + 1 )], [[ 0 ] for _ in range ( N + 1 )]
for i in range ( 1 , N + 1 ):
K = int ( input ())
for k in range ( K ):
w , v = map ( int , input () . split ())
W [ i ], V [ i ] = W [ i ] + [ w ], V [ i ] + [ v ]
f = [ 0 ] * ( mxW + 1 )
for i in range ( 1 , N + 1 ):
for j in range ( mxW , - 1 , - 1 ):
for k in range ( len ( W [ i ])):
if j - W [ i ][ k ] >= 0 :
f [ j ] = max ( f [ j ], f [ j - W [ i ][ k ]] + V [ i ][ k ])
网格图 dp
最大 / 最小单趟路径和
LCR 166. 珠宝的最高价值 - 力扣(LeetCode)
求从左上角 ( 0 , 0 ) (0,0) ( 0 , 0 ) ( m − 1 , n − 1 ) (m-1,~n-1) ( m − 1 , n − 1 ) f ( i , j ) = g ( i , j ) + max ( f ( i − 1 , j ) , f ( i , j − 1 ) ) f(i,j)=g(i,j)+\max(f(i-1,j),~f(i,j-1)) f ( i , j ) = g ( i , j ) + max ( f ( i − 1 , j ) , f ( i , j − 1 ))
def jewelleryValue ( self , grid : List [ List [ int ]]) -> int :
# f(i, j) 表示到达 (i, j) 网格的最高价值
m , n = len ( grid ), len ( grid [ 0 ])
f = [[ 0 ] * ( n + 1 ) for _ in range ( m + 1 )]
for i in range ( 1 , m + 1 ):
for j in range ( 1 , n + 1 ):
x = grid [ i - 1 ][ j - 1 ]
f [ i ][ j ] = x + max ( f [ i - 1 ][ j ], f [ i ][ j - 1 ])
return f [ m ][ n ]
64. 最小路径和 - 力扣(LeetCode)
巧妙设计初值:f ( 1 , 0 ) = f ( 0 , 1 ) = 0 , 其余为 i n f f(1,0)=f(0,1)=0,其余为 inf f ( 1 , 0 ) = f ( 0 , 1 ) = 0 , 其余为 in f
def minPathSum ( self , grid : List [ List [ int ]]) -> int :
m , n = len ( grid ), len ( grid [ 0 ])
f = [[ inf ] * ( n + 1 ) for _ in range ( m + 1 )]
f [ 0 ][ 1 ] = f [ 1 ][ 0 ] = 0
for i in range ( 1 , m + 1 ):
for j in range ( 1 , n + 1 ):
x = grid [ i - 1 ][ j - 1 ]
f [ i ][ j ] = x + min ( f [ i - 1 ][ j ], f [ i ][ j - 1 ])
return f [ m ][ n ]
120. 三角形最小路径和 - 力扣(LeetCode)
将三角形转换成网格图:约束 j ∈ [ 1 , i ] j \in [1,i] j ∈ [ 1 , i ]
def minimumTotal ( self , triangle : List [ List [ int ]]) -> int :
m = n = len ( triangle )
f = [[ inf ] * ( n + 1 ) for _ in range ( m + 1 )]
f [ 0 ][ 1 ] = 0
for i in range ( 1 , m + 1 ):
for j in range ( 1 , i + 1 ):
x = triangle [ i - 1 ][ j - 1 ]
f [ i ][ j ] = x + min ( f [ i - 1 ][ j ], f [ i - 1 ][ j - 1 ])
return min ( f [ m ][ 1 : ])
1289. 下降路径最小和 II - 力扣(LeetCode)
求从上一层列下标不同位置处转移的路径最小和 。维护上一层的最小值、次小值 。时间复杂度从 O ( n 3 ) O(n^3) O ( n 3 ) O ( n 2 ) O(n^2) O ( n 2 )
def minFallingPathSum ( self , grid : List [ List [ int ]]) -> int :
m = n = len ( grid )
if m == 1 : return min ( grid [ 0 ])
f = [[ inf ] * ( n + 1 ) for _ in range ( m + 1 )]
mn = mn_2 = ( 0 , - 1 )
for i in range ( 1 , m + 1 ):
pmn , pmn_2 = mn , mn_2
mn = mn_2 = ( inf , - 1 )
for j in range ( 1 , n + 1 ):
x = grid [ i - 1 ][ j - 1 ]
y = f [ i ][ j ] = x + pmn [ 0 ] if pmn [ 1 ] != j else x + pmn_2 [ 0 ]
if y < mn [ 0 ]: mn_2 , mn = mn , ( y , j )
elif y == mn [ 0 ]: mn_2 = ( y , j )
elif y < mn_2 [ 0 ]: mn_2 = ( y , j )
return min ( f [ m ])
求路径方案数
63. 不同路径 II - 力扣(LeetCode)
巧妙设计初值,避免特殊边界讨论。
def uniquePathsWithObstacles ( self , grid : List [ List [ int ]]) -> int :
m , n = len ( grid ), len ( grid [ 0 ])
f = [[ 0 ] * ( n + 1 ) for _ in range ( m + 1 )]
f [ 0 ][ 1 ] = 1
for i in range ( 1 , m + 1 ):
for j in range ( 1 , n + 1 ):
x = grid [ i - 1 ][ j - 1 ]
f [ i ][ j ] = 0 if x else f [ i - 1 ][ j ] + f [ i ][ j - 1 ]
return f [ m ][ n ]
多路线问题
1463. 摘樱桃 II - 力扣(LeetCode)
双起点 + 双路线问题
f ( t , i , j ) f(t,i,j) f ( t , i , j ) t t t ( t , i ) (t,i) ( t , i ) ( t , j ) (t,j) ( t , j ) ( 0 , 0 ) (0,0) ( 0 , 0 ) ( 0 , n − 1 ) (0, n- 1) ( 0 , n − 1 ) − i n f -inf − in f f [ 0 ] [ 0 ] [ n + 1 ] = 0 f[0][0][n + 1] = 0 f [ 0 ] [ 0 ] [ n + 1 ] = 0
def cherryPickup ( self , grid : List [ List [ int ]]) -> int :
m , n = len ( grid ), len ( grid [ 0 ])
# f(t, i, j)
res = 0
f = [[[ - inf ] * ( n + 2 ) for _ in range ( n + 2 )] for _ in range ( m + 1 )]
f [ 0 ][ 0 ][ n + 1 ] = 0
for t in range ( 1 , m + 1 ):
for i in range ( 1 , n + 1 ):
x = grid [ t - 1 ][ i - 1 ]
for j in range ( 1 , n + 1 ):
y = 0 if i == j else grid [ t - 1 ][ j - 1 ]
mx = max ( f [ t - 1 ][ i ][ j ], f [ t - 1 ][ i - 1 ][ j ], f [ t - 1 ][ i + 1 ][ j ], \
f [ t - 1 ][ i ][ j - 1 ], f [ t - 1 ][ i - 1 ][ j - 1 ], f [ t - 1 ][ i + 1 ][ j - 1 ], \
f [ t - 1 ][ i ][ j + 1 ], f [ t - 1 ][ i - 1 ][ j + 1 ], f [ t - 1 ][ i + 1 ][ j + 1 ])
f [ t ][ i ][ j ] = x + y + mx
if t == m : res = max ( res , f [ t ][ i ][ j ])
return res
741. 摘樱桃 - 力扣(LeetCode)
同起点 + 双路线问题
f ( t , i , j ) f(t, i, j) f ( t , i , j ) A , B A, B A , B t t t ( i , t − i ) , ( j , t − j ) (i, t - i), ~ (j, t - j) ( i , t − i ) , ( j , t − j )
为了区分没有采摘、不可达,初始值设定为 − i n f -inf − in f i = j i =j i = j A , B A,B A , B g r i d [ i ] [ t − i ] grid[i][t-i] g r i d [ i ] [ t − i ] g r i d [ j ] [ t − j ] + g r i d [ i ] [ t − i ] grid[j][t - j] + grid[i][t-i] g r i d [ j ] [ t − j ] + g r i d [ i ] [ t − i ] max { f ( t − 1 , i , j ) , f ( t − 1 , i − 1 , j ) , f ( t − 1 , i , j − 1 ) , f ( t − 1 , i − 1 , j − 1 ) } \max \{f(t-1,i,j),~f(t-1,i-1,j), ~f(t-1,i,j-1),~f(t-1,i-1,j-1)\} max { f ( t − 1 , i , j ) , f ( t − 1 , i − 1 , j ) , f ( t − 1 , i , j − 1 ) , f ( t − 1 , i − 1 , j − 1 )} − 1 -1 − 1
同时需要注意 t t t i i i j j j f ( 2 n − 2 , n − 1 , n − 1 ) f(2n-2,~n-1,~n-1) f ( 2 n − 2 , n − 1 , n − 1 )
def cherryPickup ( self , grid : List [ List [ int ]]) -> int :
# f(t, i, j) 表示走了 t 步, 分别到达 (i, t - i) 和 (j, t - j) 获得的最大得分
n = len ( grid )
f = [[[ - inf ] * ( n ) for _ in range ( n )] for _ in range ( 2 * n - 1 )]
f [ 0 ][ 0 ][ 0 ] = grid [ 0 ][ 0 ]
for t in range ( 1 , 2 * n - 1 ):
for i in range ( max ( 0 , t - n + 1 ), min ( n , t + 1 )):
x = grid [ i ][ t - i ]
if x < 0 : continue
for j in range ( max ( 0 , t - n + 1 ), min ( n , t + 1 )):
y = grid [ j ][ t - j ] if i != j else 0
if y < 0 : continue
mx = max ( f [ t - 1 ][ i ][ j ], f [ t - 1 ][ i - 1 ][ j ], f [ t - 1 ][ i ][ j - 1 ], f [ t - 1 ][ i - 1 ][ j - 1 ])
f [ t ][ i ][ j ] = mx + x + y
res = f [ 2 * n - 2 ][ n - 1 ][ n - 1 ]
return res if res != - inf else 0
区间 dp
石子合并
AcWing 282. 石子合并 - AcWing
s = [ 0 ] * ( n + 1 )
f = [[ 0 ] * n for _ in range ( n )]
for i in range ( n ):
s [ i + 1 ] = s [ i ] + nums [ i ]
for l in range ( 2 , n + 1 ):
for i in range ( n + 1 - l ):
j = i + l - 1
f [ i ][ j ] = inf
for k in range ( i , j ):
f [ i ][ j ] = min ( f [ i ][ j ], f [ i ][ k ] + f [ k + 1 ][ j ] + s [ j + 1 ] - s [ i ])
312. 戳气球 - 力扣(LeetCode)
长度统一处理:对于 length = 1, f [ i ] [ i − 1 ] f[i][i-1] f [ i ] [ i − 1 ] f [ j + 1 ] [ j ] f[j + 1][j] f [ j + 1 ] [ j ]
对于 length = 2, f [ i ] [ i + 1 ] 其中一项 [ i ] [ i − 1 ] + f [ i + 1 ] [ i + 1 ] + . . . f[i][i+1] 其中一项 [i][i-1] + f[i+1][i+1]+... f [ i ] [ i + 1 ] 其中一项 [ i ] [ i − 1 ] + f [ i + 1 ] [ i + 1 ] + ...
def maxCoins ( self , nums : List [ int ]) -> int :
nums = [ 1 ] + nums + [ 1 ]
n = len ( nums )
f = [[ 0 ] * n for _ in range ( n )]
for l in range ( 1 , n - 1 ):
for i in range ( 1 , n - l ):
j = i + l - 1
for k in range ( i , j + 1 ):
f [ i ][ j ] = max ( f [ i ][ j ], f [ i ][ k - 1 ] + f [ k + 1 ][ j ] + nums [ k ] * nums [ i - 1 ] * nums [ j + 1 ])
return f [ 1 ][ n - 2 ]
375. 猜数字大小 II - 力扣(LeetCode)
f [ a , b ] 表示从 [ a : b ] 一定能获胜的最小金额 f[a, b] 表示从[a : b] 一定能获胜的最小金额 f [ a , b ] 表示从 [ a : b ] 一定能获胜的最小金额
复杂度:O ( n 3 ) O(n^3) O ( n 3 )
def getMoneyAmount ( self , n : int ) -> int :
# f [a, b] 表示从 [a : b] 一定能获胜的最小金额
# 最多取到 f [n + 1][n]
f = [[ 0 ] * ( n + 1 ) for _ in range ( n + 2 )]
for l in range ( 2 , n + 1 ):
for i in range ( 1 , n + 2 - l ):
j = i + l - 1
f [ i ][ j ] = inf
for k in range ( i , j + 1 ):
f [ i ][ j ] = min ( f [ i ][ j ], k + max ( f [ i ][ k - 1 ], f [ k + 1 ][ j ]))
return f [ 1 ][ n ]
1039. 多边形三角剖分的最低得分 - 力扣(LeetCode)
def minScoreTriangulation ( self , values : List [ int ]) -> int :
# f [i: j] 表示从 [i: j] 的最小得分
# f [0: n - 1]
n = len ( values )
f = [[ 0 ] * ( n + 1 ) for _ in range ( n + 1 )]
for l in range ( 3 , n + 1 ):
for i in range ( n + 1 - l ):
j = i + l - 1
f [ i ][ j ] = inf
for k in range ( i + 1 , j ):
f [ i ][ j ] = min ( f [ i ][ j ], f [ i ][ k ] + f [ k ][ j ] + values [ i ] * values [ k ] * values [ j ])
return f [ 0 ][ n - 1 ]
95. 不同的二叉搜索树 II - 力扣(LeetCode)
卡特兰数 + 区间 dp,f [ i , j ] f[i, j] f [ i , j ] i , i + 1 , ⋯ , j i,i+1,~\cdots~, j i , i + 1 , ⋯ , j
最终问题:f ( 1 , n ) f(1,n) f ( 1 , n ) k ∈ [ i , j ] k \in [i,j] k ∈ [ i , j ] f ( i , k − 1 ) f(i,k-1) f ( i , k − 1 ) f ( k + 1 , j ) f(k+1,j) f ( k + 1 , j )
def generateTrees ( self , n : int ) -> List [ Optional [ TreeNode ]]:
# f [i, j] 表示用 1 .. j 构建的二叉搜索树的所有根节点列表
# 枚举树根节点 k in range(i, j + 1)
# f [i, k - 1] 为所有左子树可能的根节点列表
# f [k + 1, j] 为所有右子树可能的根节点列表
f = [[[ None ] for _ in range ( n + 2 )] for _ in range ( n + 2 )]
for l in range ( 1 , n + 1 ):
for i in range ( 1 , n + 2 - l ):
j = i + l - 1
f [ i ][ j ] = []
for k in range ( i , j + 1 ):
for left in f [ i ][ k - 1 ]:
for right in f [ k + 1 ][ j ]:
f [ i ][ j ] . append ( TreeNode ( k , left , right ))
return f [ 1 ][ n ]
最长回文子序列
求最长回文子序列长度问题
f [ i : j ] 表示 s [ i ] ∼ s [ j ] 中的最长回文子序列的长度 f[i: j]~ 表示s[i] \sim s[j] 中的最长回文子序列的长度 f [ i : j ] 表示 s [ i ] ∼ s [ j ] 中的最长回文子序列的长度
516. 最长回文子序列 - 力扣(LeetCode)
def mx_pal_subseq ( self , s : str ) -> int :
# f(i, j) 表示 s [i] ~ s [j] 的最长回文子序列的长度
n = len ( s )
f = [[ 0 ] * n for _ in range ( n )]
for i in range ( n ): f [ i ][ i ] = 1
for l in range ( 2 , n + 1 ):
# i + l < n + 1
for i in range ( n + 1 - l ):
j = i + l - 1
if s [ i ] == s [ j ]:
f [ i ][ j ] = f [ i + 1 ][ j - 1 ] + 2
else :
f [ i ][ j ] = max ( f [ i + 1 ][ j ], f [ i ][ j - 1 ])
return f [ 0 ][ n - 1 ]
推论:对于长度为 n n n L L L n − L n - L n − L
1312. 让字符串成为回文串的最少插入次数 - 力扣(LeetCode)
[P1435 IOI2000] 回文字串 - 洛谷 | 计算机科学教育新生态 (luogu.com.cn)
def minInsertions ( self , s : str ) -> int :
# f [i: j] 表示从 s [i] ~ s [j] 的 最长回文子序列
n = len ( s )
f = [[ 0 ] * ( n + 1 ) for _ in range ( n + 1 )]
for i in range ( n ):
f [ i ][ i ] = 1
for l in range ( 2 , n + 1 ):
for i in range ( n + 1 - l ):
j = i + l - 1
if s [ i ] == s [ j ]:
f [ i ][ j ] = f [ i + 1 ][ j - 1 ] + 2
else :
f [ i ][ j ] = max ( f [ i + 1 ][ j ], f [ i ][ j - 1 ])
return n - f [ 0 ][ n - 1 ]
2002. 两个回文子序列长度的最大乘积 - 力扣(LeetCode)
二进制枚举,将集合划分成互不相交的两部分。求各自最长回文子序列长度的乘积。O ( 2 n ⋅ n 2 ) O(2^n\cdot n^2) O ( 2 n ⋅ n 2 )
def maxProduct ( self , s1 : str ) -> int :
n , res = len ( s1 ), 0
s = ( 1 << n ) - 2
sub = s
def mx_pal_subseq ( ss ):
m = len ( ss )
f = [[ 0 ] * m for _ in range ( m )]
for i in range ( m ): f [ i ][ i ] = 1
for l in range ( 2 , m + 1 ):
for i in range ( m + 1 - l ):
j = i + l - 1
if ss [ i ] == ss [ j ]:
f [ i ][ j ] = f [ i + 1 ][ j - 1 ] + 2
else :
f [ i ][ j ] = max ( f [ i + 1 ][ j ], f [ i ][ j - 1 ])
return f [ 0 ][ m - 1 ]
while sub :
s2 = '' . join ([ s1 [ j ] for j in range ( n ) if ( sub >> j ) & 1 ])
s3 = '' . join ([ s1 [ j ] for j in range ( n ) if ( sub >> j ) & 1 == 0 ])
cur = mx_pal_subseq ( s2 ) * mx_pal_subseq ( s3 )
if cur > res : res = cur
sub = ( sub - 1 ) & s
return res
最长回文子串
5. 最长回文子串 - 力扣(LeetCode)
def longestPalindrome ( self , s : str ) -> str :
# 定义 f [i][j] 表示从 s [i] ~ s [j] 是否是回文字符串
left = right = 0
n = len ( s )
f = [[ True ] * ( n + 1 ) for _ in range ( n + 1 )]
for l in range ( 2 , n + 1 ):
for i in range ( n + 1 - l ):
j = i + l - 1
f [ i ][ j ] = s [ i ] == s [ j ] and f [ i + 1 ][ j - 1 ]
if f [ i ][ j ]:
left , right = i , j
return s [ left : right + 1 ]
数位 dp
模板 1:统计各位数字出现次数
统计在 [ a , b ] [a, b] [ a , b ]
需要实现 c o u n t ( n , x ) count(n, x) co u n t ( n , x ) [ 1 , n ] [1, n] [ 1 , n ] x x x
def count ( n , x ):
# 在 1 ~ n 中 x 数字出现的次数
# 上界 abcdefg
# yyyizzz , 考虑 i 位上 x 的出现次数
#
# 1.1 如果 x 不为 0 yyy 为 000 ~ abc - 1, zzz 为 000 ~ 999
# 1.2x 为 0,yyy 为 001 ~ abc - 1, zzz 为 000 ~ 999
#
# 2. yyy 为 abc,
# 2.1 d < x 时,0
# 2.2 d = x 时,zzz 为 000 ~ efg
# 2.3 d > x 时,zzz 为 000 ~ 999
s = str ( n )
res = 0
n = len ( s )
for i in range ( n ):
pre = 0 if i == 0 else int ( s [: i ])
suf = s [ i + 1 :]
if x == 0 : res += ( pre - 1 ) * pow ( 10 , len ( suf ))
else : res += pre * pow ( 10 , len ( suf ))
d = int ( s [ i ])
if d == x : res += ( int ( suf ) if suf else 0 ) + 1
elif d > x : res += pow ( 10 , len ( suf ))
return res
def get ( a , b ):
for i in range ( 10 ):
print ( count ( b , i ) - count ( a - 1 , i ), end = ' ' )
print ()
简化版:
def count ( n , x ): # 统计 1 ~ n 中 数字 x 的出现次数
res = 0
s = str ( n )
m = len ( s )
for i in range ( m ):
pre = 0 if i == 0 else int ( s [: i ])
d = int ( s [ i ])
sufs = s [ i + 1 : ]
if x == 0 : pre -= 1
if d > x : pre += 1
if d == x : res += ( int ( sufs ) if sufs else 0 ) + 1
res += pre * pow ( 10 , len ( sufs ))
return res
def get ( a , b ):
for i in range ( 10 ):
print ( count ( b , i ) - count ( a - 1 , i ), end = ' ' )
print ()
233. 数字 1 的个数 - 力扣(LeetCode)
def count ( n , x ): # 统计 1 ~ n 中 数字 x 的出现次数
res = 0
s = str ( n )
m = len ( s )
for i in range ( m ):
pre = 0 if i == 0 else int ( s [: i ])
d = int ( s [ i ])
sufs = s [ i + 1 : ]
if x == 0 : pre -= 1
if d > x : pre += 1
if d == x : res += ( int ( sufs ) if sufs else 0 ) + 1
res += pre * pow ( 10 , len ( sufs ))
return res
return count ( n , 1 )
模板 2:带限制数位 dp 统计问题
通用模板 v1.0:统计 [ 1 , n ] [1, ~n] [ 1 , n ]
f ( i , m a s k , i s _ l i m i t , i s _ n u m ) f(i,~mask,~is\_limit,~is\_num) f ( i , ma s k , i s _ l imi t , i s _ n u m ) m a s k mask ma s k i i i
其中, i s _ l i m i t is\_limit i s _ l imi t T r u e True T r u e i i i h i = i n t ( s [ i ] ) hi = int(s[i]) hi = in t ( s [ i ])
i s _ n u m is\_num i s _ n u m T r u e True T r u e i i i 0 0 0 1 1 1
@lru_cache ( maxsize = None )
def f ( i : int , mask : int , is_limit : bool , is_num : bool ):
if i == m :
if is_num : return 1
return 0
res = 0
lo , hi = 0 , 9
if not is_num :
lo = 1
res += f ( i + 1 , mask , False , False )
if is_limit :
hi = int ( s [ i ])
for j in range ( lo , hi + 1 ):
# j 没有在 mask 的集合中出现过
if ( mask >> j ) & 1 == 0 :
res += f ( i + 1 , mask | ( 1 << j ), is_limit and j == hi , True )
return res
return f ( 0 , 0 , True , False )
简化版本:
@lru_cache ( None )
def f ( i , mask , is_limit , is_num ):
if i == len ( s ): return int ( is_num )
res = 0 if is_num else f ( i + 1 , mask , False , False )
lo , hi = 0 if is_num else 1 , int ( s [ i ]) if is_limit else 9
for j in range ( lo , hi + 1 ):
if ( mask >> j ) & 1 == 0 :
res += f ( i + 1 , mask | ( 1 << j ), is_limit and j == hi , True )
return res
时间复杂度:记 D = 10 D = 10 D = 10 O ( D ) O(D) O ( D ) ( i , m a s k ) (i, mask) ( i , ma s k ) ( i , m a s k , i s _ l i m i t , i s _ n u m ) (i,~mask,~is\_limit,~is\_num) ( i , ma s k , i s _ l imi t , i s _ n u m ) ( i , m a s k ) (i, mask) ( i , ma s k ) m ⋅ 2 D m\cdot2^D m ⋅ 2 D m m m n n n O ( D ⋅ m ⋅ 2 D ) O(D\cdot m \cdot 2^D) O ( D ⋅ m ⋅ 2 D )
实际上某些问题中, i s _ n u m is\_num i s _ n u m n o t ( m a s k = = 0 ) not(mask ==0) n o t ( ma s k == 0 ) i s _ n u m is\_num i s _ n u m
2376. 统计特殊整数 - 力扣(LeetCode)
统计 1 ∼ n 1 \sim n 1 ∼ n m a s k mask ma s k
def countSpecialNumbers ( self , n : int ) -> int :
s = str ( n )
@lru_cache ( None )
def f ( i , mask , is_limit , is_num ):
if i == len ( s ): return int ( is_num )
res = 0 if is_num else f ( i + 1 , mask , False , False )
lo , hi = 0 if is_num else 1 , int ( s [ i ]) if is_limit else 9
for j in range ( lo , hi + 1 ):
if ( mask >> j ) & 1 == 0 :
res += f ( i + 1 , mask | ( 1 << j ), is_limit and j == hi , True )
return res
return f ( 0 , 0 , True , False )
788. 旋转数字 - 力扣(LeetCode)
统计区间:1 ∼ N 1 \sim N 1 ∼ N
限制条件:旋转后不等于自身,且合法的数字。只需要在数字中包含至少 一个 [ 2 , 5 , 6 , 9 ] [2, 5, 6, 9] [ 2 , 5 , 6 , 9 ] [ 3 , 4 , 7 ] [3, 4, 7] [ 3 , 4 , 7 ]
def rotatedDigits ( self , n : int ) -> int :
s = str ( n )
m = len ( s )
# 合法情况:包含至少一个 [2, 5, 6, 9] 且 不包含 [3, 4, 7]
nums = [ 0 , 0 , 1 , - 1 , - 1 , 1 , 1 , - 1 , 0 , 1 ]
@lru_cache ( None )
def f ( i , has_mir , is_limit , is_num ):
if i == m : return int ( has_mir and is_num )
res = 0 if is_num else f ( i + 1 , has_mir , False , False )
lo , hi = 0 if is_num else 1 , int ( s [ i ]) if is_limit else 9
for j in range ( lo , hi + 1 ):
if nums [ j ] != - 1 :
res += f ( i + 1 , has_mir or nums [ j ] == 1 , is_limit and j == hi , True )
return res
return f ( 0 , False , True , False )
902. 最大为 N 的数字组合 - 力扣(LeetCode)
def atMostNGivenDigitSet ( self , digits : List [ str ], n : int ) -> int :
s = str ( n )
ss = set ([ int ( ch ) for ch in digits ])
m = len ( s )
@lru_cache ( None )
def f ( i , is_limit , is_num ):
if i == m : return int ( is_num )
res = 0 if is_num else f ( i + 1 , False , False )
lo , hi = 0 if is_num else 1 , int ( s [ i ]) if is_limit else 9
for j in range ( lo , hi + 1 ):
if j in ss :
res += f ( i + 1 , is_limit and j == hi , True )
return res
return f ( 0 , True , False )
2827. 范围中美丽整数的数目 - 力扣(LeetCode)
运用模运算的性质:整个数字 模 k k k 1234 m o d 17 1234 \bmod 17 1234 mod 17 ( 1000 m o d 17 ) + ( 200 m o d 17 ) + ( 30 m o d 17 ) + ( 4 m o d 17 ) (1000 \bmod 17) + (200 \bmod 17)+(30 \bmod 17 )+ (4 \bmod 17) ( 1000 mod 17 ) + ( 200 mod 17 ) + ( 30 mod 17 ) + ( 4 mod 17 ) m o d _ r e s × 10 + j mod\_res \times 10 + j m o d _ res × 10 + j
def numberOfBeautifulIntegers ( self , low : int , high : int , k : int ) -> int :
def cal ( x ):
s = str ( x )
m = len ( s )
@lru_cache ( None )
def f ( i , mod_res , odd_even_delta , is_limit , is_num ):
if i == m : return int ( odd_even_delta == 0 and mod_res == 0 and is_num )
res = 0 if is_num else f ( i + 1 , mod_res , odd_even_delta , False , False )
lo , hi = 0 if is_num else 1 , int ( s [ i ]) if is_limit else 9
for j in range ( lo , hi + 1 ):
res += f ( i + 1 , ( mod_res * 10 + j ) % k , odd_even_delta + ( 1 if j & 1 else - 1 ), is_limit and j == hi , True )
return res
return f ( 0 , 0 , 0 , True , False )
return cal ( high ) - cal ( low - 1 )
600. 不含连续 1 的非负整数 - 力扣(LeetCode)
二进制数位 dp。上界改为 1
def findIntegers ( self , n : int ) -> int :
def get_bin ( x ):
res = i = 0
while x :
res = res + pow ( 10 , i ) * ( x % 2 )
i += 1
x >>= 1
return res
n = get_bin ( n )
s = str ( n )
m = len ( s )
@lru_cache ( None )
def f ( i , pre , is_limit , is_num ):
if i == m : return int ( is_num )
res = 0 if is_num else f ( i + 1 , None , False , False )
lo , hi = 0 if is_num else 1 , int ( s [ i ]) if is_limit else 1
for j in range ( lo , hi + 1 ):
if pre == None or ( j == 1 and pre != 1 ) or j == 0 :
res += f ( i + 1 , j , is_limit and j == hi , True )
return res
return f ( 0 , None , True , False ) + 1
状态机 dp
3068. 最大节点价值之和 - 力扣(LeetCode)
0 表示当前异或偶数个 k,1 表示当前异或奇数个 k
0 → 0 或者 1 → 1 0 \rightarrow 0 或者 1 \rightarrow 1 0 → 0 或者 1 → 1 加上 x 加上x 加上 x
0 → 1 或者 1 → 0 0 \rightarrow 1 或者 1 \rightarrow 0 0 → 1 或者 1 → 0 加上 x ⊕ k 加上x \oplus k 加上 x ⊕ k
def maximumValueSum ( self , nums : List [ int ], k : int , edges : List [ List [ int ]]) -> int :
n = len ( nums )
dp = [[ 0 ] * 2 for _ in range ( n + 1 )]
dp [ n ][ 1 ] = - inf
for i , x in enumerate ( nums ):
dp [ i ][ 0 ] = max ( dp [ i - 1 ][ 0 ] + x , dp [ i - 1 ][ 1 ] + ( x ^ k ))
dp [ i ][ 1 ] = max ( dp [ i - 1 ][ 1 ] + x , dp [ i - 1 ][ 0 ] + ( x ^ k ))
return dp [ n - 1 ][ 0 ]
状压 dp / 状态压缩 dp
291. 蒙德里安的梦想 - AcWing 题库
竖方块摆放确定时,横方块摆放一定确定(合法或者恰好填充),所以只需要看竖方块的摆放情况。对于 N × M N\times M N × M f ( i , j ) f(i, j) f ( i , j ) i i i j j j i i i j j j M M M 1 1 1 0 0 0
f ( i , j ) f(i,j) f ( i , j ) f ( i − 1 , k ) f(i-1, k) f ( i − 1 , k ) j & k = 0 j ~\&~ k =0 j & k = 0 j ∣ k j ~|~ k j ∣ k j ∣ k j ~|~ k j ∣ k
初始状态对于 f ( 0 ) f(0) f ( 0 ) f ( 0 , 0 ) = 1 f(0,~0) = 1 f ( 0 , 0 ) = 1 f ( N , 0 ) f(N, 0) f ( N , 0 ) f ( i , j ) = ∑ v a l i d ( f ( i − 1 , k ) ) f(i,j) = \sum valid(f(i-1,k)) f ( i , j ) = ∑ v a l i d ( f ( i − 1 , k ))
对于所有 M M M
N = M = 11
f = [[ 0 ] * ( 1 << M + 1 ) for _ in range ( N + 1 )]
def solve ( n , m ):
# f [n][1 << m]
# 预处理,判断 i 是否含有连续的奇数个 0
s = set ()
for i in range ( 1 << m ):
c = 0
for j in range ( m ):
if i >> j & 1 :
if c & 1 : break
else : c += 1
if c & 1 : s . add ( i )
f [ 0 ][ 0 ] = 1
for i in range ( 1 , n + 1 ):
for j in range ( 1 << m ):
f [ i ][ j ] = 0
for k in range ( 1 << m ):
if ( j & k == 0 and ( j | k not in s )):
f [ i ][ j ] += f [ i - 1 ][ k ]
return f [ n ][ 0 ]
最短哈密顿回路 / 旅行商问题
哈密顿回路:无向带权图中经过所有顶点的回路。朴素做法对于 N N N O ( n ! ) O(n!) O ( n !) N P − h a r d NP-hard NP − ha r d
实际上,设已经访问过的点集 S S S j j j f ( S , j ) f(S,j) f ( S , j ) S S S j j j f ( S , j ) = min { f ( S − j , k ) + w ( k , j ) , ∀ k ∈ S − j } f(S,j) = \min \{f(S-j, k) + w(k,~j) ~, \forall~k \in S-j \} f ( S , j ) = min { f ( S − j , k ) + w ( k , j ) , ∀ k ∈ S − j } S S S f ( 2 N − 1 , N − 1 ) f(2^N -1, N - 1 ) f ( 2 N − 1 , N − 1 ) f ( 0 , 0 ) = 0 f(0, 0) = 0 f ( 0 , 0 ) = 0
def solve ():
n = int ( input ())
f = [[ inf ] * n for _ in range ( 1 << n )]
w = []
for _ in range ( n ):
w . append ( list ( map ( int , input () . split ())))
f [ 1 ][ 0 ] = 0
for S in range ( 1 , 1 << n ):
for j in range ( n ):
if ( S >> j ) & 1 : # j 在 S 中,
for k in range ( n ):
if (( S ^ ( 1 << j )) >> k ) & 1 : # 且 k 在 S - j 中
f [ S ][ j ] = min ( f [ S ^ ( 1 << j )][ k ] + w [ k ][ j ], f [ S ][ j ])
return f [( 1 << n ) - 1 ][ n - 1 ]
全排列型状压
朴素 - 全排列状压
1879. 两个数组最小的异或值之和 - 力扣(LeetCode)
O ( n 2 × 2 n ) O(n^2 \times 2^n ) O ( n 2 × 2 n ) f ( i , s ) f(i, s) f ( i , s ) n u m s [ 0 : i ] nums[0: i] n u m s [ 0 : i ] s s s
class Solution :
def minimumXORSum ( self , nums1 : List [ int ], nums2 : List [ int ]) -> int :
n = len ( nums2 )
f = [[ inf ] * ( 1 << n ) for _ in range ( n + 1 )]
for i in range ( n + 1 ): f [ i ][ 0 ] = 0
for i in range ( 1 , n + 1 ):
x = nums1 [ i - 1 ]
for s in range ( 1 , 1 << n ):
for j in range ( n ):
if ( s >> j ) & 1 == 0 : continue
f [ i ][ s ] = min ( f [ i ][ s ], f [ i - 1 ][ s ^ ( 1 << j )] + ( x ^ nums2 [ j ]))
return f [ n ][( 1 << n ) - 1 ]
优化:省略前一维度,这是因为 i i i s s s O ( n × 2 n ) O(n\times 2^n) O ( n × 2 n )
class Solution :
def minimumXORSum ( self , nums1 : List [ int ], nums2 : List [ int ]) -> int :
n = len ( nums2 )
f = [ inf ] * ( 1 << n )
f [ 0 ] = 0
for s in range ( 1 , 1 << n ):
x = nums1 [ s . bit_count () - 1 ]
for j in range ( n ):
if ( s >> j ) & 1 == 0 : continue
f [ s ] = min ( f [ s ], f [ s ^ ( 1 << j )] + ( x ^ nums2 [ j ]))
return f [( 1 << n ) - 1 ]
约束型 - 全排列状压
对于带有约束的全排列问题,f [ i ] [ s ] f[i][s] f [ i ] [ s ] p [ 0 : i ] p[0: i] p [ 0 : i ] s s s f [ i ] [ s ] = ∑ f [ i − 1 ] [ s − { j } ] , ∀ v a l i d ( j ) f[i][s]=\sum f[i-1][s-\{j\}],~ \forall ~valid(j) f [ i ] [ s ] = ∑ f [ i − 1 ] [ s − { j }] , ∀ v a l i d ( j ) f [ 0 ] [ 0 ] = 1 f[0][0]=1 f [ 0 ] [ 0 ] = 1 O ( n 2 × 2 n ) O(n^2 \times 2^n) O ( n 2 × 2 n )
优化思路:由于 s s s i i i b i n ( s ) . c o u n t ( ′ 1 ′ ) bin(s).count('1') bin ( s ) . co u n t ( ′ 1 ′ ) O ( n × 2 n ) O(n\times 2^n) O ( n × 2 n )
526. 优美的排列 - 力扣(LeetCode)
时间复杂度为 O ( n 2 × 2 n ) O(n^2 \times 2^n) O ( n 2 × 2 n )
class Solution :
def countArrangement ( self , n : int ) -> int :
res = 0
# f [i][s] 考虑完 perm [1] ~ perm [i],已选择状态为 s
m = ( 1 << n ) - 1
f = [[ 0 ] * ( m + 1 ) for _ in range ( n + 1 )]
f [ 0 ][ 0 ] = 1
for i in range ( 1 , n + 1 ):
for s in range ( m + 1 ):
for j in range ( n ):
if ( s >> j ) & 1 and (( j + 1 ) % i == 0 or i % ( j + 1 ) == 0 ):
f [ i ][ s ] += f [ i - 1 ][ s ^ ( 1 << j )]
return f [ n ][ m ]
优化:省略前一维度。时间复杂度 O ( n × 2 n ) O(n\times 2^n) O ( n × 2 n )
class Solution :
def countArrangement ( self , n : int ) -> int :
res = 0
# f [i][s] 考虑完 perm [1] ~ perm [i],已选择状态为 s
m = ( 1 << n ) - 1
f = [ 1 ] + [ 0 ] * m
for s in range ( m + 1 ):
i = bin ( s ) . count ( '1' )
for j in range ( n ):
if ( s >> j ) & 1 and (( j + 1 ) % i == 0 or i % ( j + 1 ) == 0 ):
f [ s ] += f [ s ^ ( 1 << j )]
return f [ m ]
2741. 特别的排列 - 力扣(LeetCode)
f ( s , i ) f(s,i) f ( s , i ) s s s n u m s [ i ] nums[i] n u m s [ i ] s s s i i i n u m s [ j ] nums[j] n u m s [ j ] f ( s , i ) = ∑ f ( s ⊕ j , j ) , ∀ valid ( j ) f(s,i)=\sum f(s\oplus j,~j),~\forall \text{valid}(j) f ( s , i ) = ∑ f ( s ⊕ j , j ) , ∀ valid ( j ) O ( n 2 ⋅ 2 n ) O(n^2\cdot 2^n) O ( n 2 ⋅ 2 n )
moder = 10 ** 9 + 7
class Solution :
def specialPerm ( self , nums : List [ int ]) -> int :
n = len ( nums )
f = [[ 0 ] * n for _ in range ( 1 << n )]
f [ 0 ][ 0 ] = 1
for s in range ( 1 << n ):
for i in range ( n ):
if ( s >> i ) & 1 == 0 : continue
if ( s ^ ( 1 << i )) == 0 :
f [ s ][ i ] = 1
continue
for j in range ( n ):
if i == j or ( s >> j ) & 1 == 0 : continue
x , y = nums [ i ], nums [ j ]
if x % y == 0 or y % x == 0 :
f [ s ][ i ] = ( f [ s ][ i ] + f [ s ^ ( 1 << i )][ j ]) % moder
res = 0
for i in range ( n ):
res = ( res + f [ s ][ i ]) % moder
return res
划分成 k k k
f ( i , s ) f(i,s) f ( i , s ) i i i s s s f ( i , s ) = F ( ( f ( i − 1 , s − s u b ) , G ( s u b ) ) ) f(i,s)=F((f(i-1,s-sub),~G(sub) )) f ( i , s ) = F (( f ( i − 1 , s − s u b ) , G ( s u b )))
时间复杂度: O ( n ⋅ 3 n ) O(n\cdot 3^n) O ( n ⋅ 3 n ) i i i C ( n , i ) C(n,i) C ( n , i ) 2 i 2^i 2 i ( a + b ) n = ∑ i = 0 n C n i a i b n − i (a + b) ^n = \sum_{i=0}^n C_n^ia^ib^{n-i} ( a + b ) n = ∑ i = 0 n C n i a i b n − i ∑ i = 0 n C ( n , i ) ⋅ 2 i = ( 2 + 1 ) n = 3 n \sum_{i=0}^{n} C(n,i)\cdot 2^i = (2+1)^n=3^n ∑ i = 0 n C ( n , i ) ⋅ 2 i = ( 2 + 1 ) n = 3 n O ( n ) O(n) O ( n ) G G G O ( n ⋅ 3 n ) O(n\cdot 3^n) O ( n ⋅ 3 n )
2305. 公平分发饼干 - 力扣(LeetCode)
最小化 k k k f ( i , s ) f(i,s) f ( i , s ) i i i s s s i i i
考虑 s s s s u b sub s u b f ( i , s ) = min { max ( f ( i − 1 , s − s u b ) , ∑ s u b ) } f(i,s)=\min \{ \max(f(i-1,s-sub),~\sum sub)\} f ( i , s ) = min { max ( f ( i − 1 , s − s u b ) , ∑ s u b )} f ( k , 1 f(k,1 f ( k , 1 n − 1 ) n-1) n − 1 ) f ( 0 , 0 ) = 0 f(0,0)=0 f ( 0 , 0 ) = 0
def distributeCookies ( self , cookies : List [ int ], k : int ) -> int :
# f [i][s] 表示当前划分状态为 s, s 为 1 表示已经分配
# 划分完第 i 个集合,所有集合的最大值 的最小值
# f [i][s] = min(max(f [i - 1][s ^ sub], sum(sub)))
# f [k][1 << n - 1]
n = len ( cookies )
f = [[ inf ] * ( 1 << n ) for _ in range ( k + 1 )]
f [ 0 ][ 0 ] = 0
for i in range ( 1 , k + 1 ):
for s in range ( 1 , 1 << n ):
sub = s
while sub :
tot = sum ( cookies [ j ] for j in range ( n ) if ( sub >> j ) & 1 )
f [ i ][ s ] = min ( f [ i ][ s ], max ( f [ i - 1 ][ s ^ sub ], tot ))
sub = ( sub - 1 ) & s
return f [ k ][( 1 << n ) - 1 ]
1723. 完成所有工作的最短时间 - 力扣(LeetCode)
此题是上一题的数据增强版,优化方法:预处理所有子集的和 + 一维滚动状压 dp。复杂度:O ( 3 n + n ⋅ 2 n ) O(3^n+ n\cdot 2^n) O ( 3 n + n ⋅ 2 n )
def minimumTimeRequired ( self , nums : List [ int ], k : int ) -> int :
n = len ( nums )
f = [ inf ] * ( 1 << n )
f [ 0 ] = 0
sum_ = defaultdict ( int )
for i , x in enumerate ( nums ):
for s in range ( 1 << i ):
sum_ [( 1 << i ) | s ] = sum_ [ s ] + x
for _ in range ( 1 , k + 1 ):
for s in range (( 1 << n ) - 1 , 0 , - 1 ):
sub = s
while sub :
tot = sum_ [ sub ]
if f [ s ^ sub ] > tot : tot = f [ s ^ sub ]
if f [ s ] > tot : f [ s ] = tot
sub = ( sub - 1 ) & s
return f [( 1 << n ) - 1 ]
划分集合每个和不超过 k k k
1986. 完成任务的最少工作时间段 - 力扣(LeetCode)
f ( s ) f(s) f ( s ) s u b sub s u b f ( s ) = min { f ( s − s u b ) + 1 } , ∀ ∑ s u b ≤ k f(s)=\min \{f(s-sub)+1\},~\forall \sum sub\le k f ( s ) = min { f ( s − s u b ) + 1 } , ∀ ∑ s u b ≤ k O ( 3 n + n ⋅ 2 n ) O(3^n+n\cdot 2^n) O ( 3 n + n ⋅ 2 n )
def minSessions ( self , nums : List [ int ], k : int ) -> int :
n = len ( nums )
f = [ inf ] * ( 1 << n )
f [ 0 ] = 0
# 预处理所有子集的和
sum_ = defaultdict ( int )
for i , x in enumerate ( nums ):
for sub in range ( 1 << i ):
sum_ [ sub | ( 1 << i )] = sum_ [ sub ] + x
for s in range ( 1 , 1 << n ):
sub = s
while sub :
if sum_ [ sub ] <= k :
f [ s ] = min ( f [ s ], f [ s ^ sub ] + 1 )
sub = ( sub - 1 ) & s
return f [( 1 << n ) - 1 ]
集合是否能划分成 k 个相等子集
698. 划分为 k 个相等的子集 - 力扣(LeetCode)
f [ s ] f[s] f [ s ] s s s n u m s [ j ] nums[j] n u m s [ j ] l s = f [ s ⊕ ( 1 ls=f[s \oplus(1 l s = f [ s ⊕ ( 1 j ) ] j)] j )] l s + n u m s [ j ] ≤ s i z ls+nums[j] \le siz l s + n u m s [ j ] ≤ s i z f [ s ] f[s] f [ s ] f [ s ] f[s] f [ s ]
这种方法会有一定的重复,不妨反过来,对于 f [ s ] f[s] f [ s ] n u m s [ j ] nums[j] n u m s [ j ] f [ s ∣ n u m s [ j ] ] f[s | nums[j]] f [ s ∣ n u m s [ j ]]
时间复杂度:不超过 O ( n ⋅ 2 n ) O(n \cdot 2^n) O ( n ⋅ 2 n )
class Solution :
def canPartitionKSubsets ( self , nums : List [ int ], k : int ) -> bool :
siz = sum ( nums ) // k
if sum ( nums ) % k != 0 or any ( x > siz for x in nums ): return False
# f [s] 表示 在选择状态为 s 的情况下,余数是多少
n = len ( nums )
m = ( 1 << n ) - 1
f = [ 0 ] + [ - inf ] * m
for s in range ( m ):
if f [ s ] == - inf : continue
for j in range ( n ):
if ( s >> j ) & 1 == 0 :
nx = s | ( 1 << j )
if f [ nx ] == 0 : continue
if f [ s ] + nums [ j ] <= siz :
f [ nx ] = ( f [ s ] + nums [ j ]) % siz
return f [ m ] == 0
多重状压:记忆化搜索
当某些字符、数字可以使用 若干次时,传统的状压不方便表示使用状况。因此可以转用 d f s dfs df s C o u n t e r Counter C o u n t er
691. 贴纸拼词 - 力扣(LeetCode)
其中剪枝部分,要求 s [ 0 ] s[0] s [ 0 ] w o r d word w or d w o r d word w or d s [ 0 ] s[0] s [ 0 ] s [ 0 ] s[0] s [ 0 ] d f s ( s ) dfs(s) df s ( s ) i n f inf in f
例如对于 s = t h e s=the s = t h e t t t O ( n ⋅ m ) O(n\cdot m) O ( n ⋅ m ) n n n m m m
def minStickers ( self , words : List [ str ], target : str ) -> int :
words = [ Counter ( word ) for word in words ]
# dfs(s) 表示得到 s 的最少数量
@lru_cache ( None )
def dfs ( s ):
if s == '' : return 0
cs = Counter ( s )
res = inf
for word in words :
# 如果 word 压根无法消除 s [0] 可以直接跳过
# 因为再怎么使用也无法完全消除 s
# 应该首先考虑将 s [0] 能消除的方案
if s [ 0 ] not in word : continue
ns = s
for k , v in word . items ():
ns = ns . replace ( k , '' , v )
res = min ( res , dfs ( ns ) + 1 )
return res
res = dfs ( target )
return res if res < inf else - 1
k k k k k k n × m n \times m n × m
1931. 用三种不同颜色为网格涂色 - 力扣(LeetCode)
k k k
每一行使用长度为 m m m k k k c o l o r color co l or k k k k k k f ( i , s ) = ∑ f ( i − 1 , e [ s ] ) f(i,s)= \sum f(i-1, ~e[s]) f ( i , s ) = ∑ f ( i − 1 , e [ s ])
时间复杂度:O ( k 2 m × n ) O(k^{2m}\times n) O ( k 2 m × n )
moder = 10 ** 9 + 7
class Solution :
def colorTheGrid ( self , m : int , n : int ) -> int :
# 三进制表示每一行的颜色
colors = {}
for b in range ( 3 ** m ):
color = []
x = b
while x :
color . append ( x % 3 )
x //= 3
color . extend ([ 0 ] * ( m - len ( color )))
if any ( color [ i ] == color [ i + 1 ] for i in range ( len ( color ) - 1 )):
continue
colors [ b ] = color [:: - 1 ]
e = defaultdict ( list )
# 预处理每一种状态可以邻接的状态
for i , u in colors . items ():
for j , v in colors . items ():
flag = True
for b in range ( m ):
if u [ b ] == v [ b ]:
flag = False
break
if flag : e [ i ] . append ( j )
# f [i][s] 表示 i 行为 s 的方案数
f = [[ 0 ] * ( 3 ** m ) for _ in range ( n )]
for b in colors . keys ():
f [ 0 ][ b ] = 1
for i in range ( 1 , n ):
for s in colors . keys ():
for ps in e [ s ]:
f [ i ][ s ] = ( f [ i - 1 ][ ps ] + f [ i ][ s ]) % moder
return ( sum ( f [ n - 1 ])) % moder
划分 dp
约束划分个数
将数组分成 (恰好/至多) k k k
类型 1: f [ i ] [ j ] f[i][j] f [ i ] [ j ] a [ : i ] a[:i] a [ : i ] a [ : i ] a[:i] a [ : i ] j j j L L L f [ L ] [ j − 1 ] f[L][j-1] f [ L ] [ j − 1 ] f [ i ] [ j ] f[i][j] f [ i ] [ j ] a [ L : i ] a[L:i] a [ L : i ] f ( i , j ) = min ( f ( L , j − 1 ) ) f(i,j)=\min(f(L,j-1)) f ( i , j ) = min ( f ( L , j − 1 ))
类型 2:f ( i , j , p r e ) f(i,j, pre) f ( i , j , p re ) a [ i ] a[i] a [ i ] a [ : i ] a[:i] a [ : i ] j j j p r e pre p re i i i p r e pre p re f ( i , j , p r e ) = min { f ( i + 1 , j , p r e ) , f ( i + 1 , j + 1 , p r e ′ ) } f(i,j,pre)=\min \{~f(i+1,j,pre),~f(i+1,j+1,pre')~\} f ( i , j , p re ) = min { f ( i + 1 , j , p re ) , f ( i + 1 , j + 1 , p r e ′ ) }
3117. 划分数组得到最小的值之和 - 力扣(LeetCode)
f ( i , j , p r e _ a n d ) : f(i, j, pre\_and): f ( i , j , p re _ an d ) : n u m s [ i ] nums[i] n u m s [ i ] j j j p r e _ a n d pre\_and p re _ an d
def minimumValueSum ( self , nums : List [ int ], andValues : List [ int ]) -> int :
n , m = len ( nums ), len ( andValues )
@lru_cache ( None )
def f ( i , j , pre_and ):
# 表示当前考虑到 nums [i],且前缀中包含 j 段,pre_and 表示当前待划分的这段的 AND
if i == n and j == m : return 0
if i < n and j == m : return inf
if i == n and j < m : return inf
pre_and &= nums [ i ]
# 在 i 处不划分,
res = f ( i + 1 , j , pre_and )
# 在 i 处划分,条件是这一段 pre_and == andValues [j]
if pre_and == andValues [ j ]:
res = min ( res , f ( i + 1 , j + 1 , - 1 ) + nums [ i ])
return res
res = f ( 0 , 0 , - 1 )
return res if res < inf else - 1
时间复杂度:O ( m n log U ) O(mn\log U) O ( mn log U ) p r e a n d pre_and p r e a n d log U \log U log U i i i p r e _ a n d pre\_and p re _ an d l o g U logU l o gU m n log U mn \log U mn log U O ( 1 ) O(1) O ( 1 )
不相交区间
1235. 规划兼职工作 - 力扣(LeetCode)
如果报酬等于区间长度(时间差),是一个贪心 + 排序问题:按照结束时间排序,结束早的优先考虑。本题的报酬与区间长度无关,因此需要 d p dp d p
原始问题是考虑 0 ∼ max ( e n d T i m e ) 0 \sim \max (endTime) 0 ∼ max ( e n d T im e ) 0 ∼ e n d T i m e [ i ] 0 \sim endTime[i] 0 ∼ e n d T im e [ i ]
f [ x ] f[x] f [ x ] 0 ∼ e n d T i m e [ x ] 0 \sim endTime[x] 0 ∼ e n d T im e [ x ] f [ x − 1 ] f[x-1] f [ x − 1 ] x x x ≤ s t a r t T i m e [ x ] \le startTime[x] ≤ s t a r tT im e [ x ] i d x idx i d x e n d T i m e [ i d x ] ≤ s t a r t T i m e [ x ] endTime[idx]\le startTime[x] e n d T im e [ i d x ] ≤ s t a r tT im e [ x ] f [ x ] f[x] f [ x ] x x x
实现时,在数组前面增加一个 ( 0 , 0 , 0 ) (0,0,0) ( 0 , 0 , 0 )
时间复杂度:O ( n log n ) O(n \log n) O ( n log n )
def jobScheduling ( self , startTime : List [ int ], endTime : List [ int ], profit : List [ int ]) -> int :
# f [x] 表示 0 ~ endTime [x] 时间段内的最多报酬
n = len ( startTime )
nums = [( 0 , 0 , 0 )] + sorted ([( s , e , p ) for s , e , p in zip ( startTime , endTime , profit )], key = lambda x : x [ 1 ])
f = [ 0 ] * ( n + 1 )
def bisect_left ( lo , hi , k ):
while lo < hi :
mid = ( lo + hi ) >> 1
if nums [ mid ][ 1 ] > k :
hi = mid
else :
lo = mid + 1
return lo - 1
for i in range ( 1 , n + 1 ):
idx = bisect_left ( 0 , i , nums [ i ][ 0 ])
f [ i ] = max ( f [ i - 1 ], f [ idx ] + nums [ i ][ 2 ])
return f [ n ]
贪心
排序贪心
406. 根据身高重建队列 - 力扣(LeetCode)
语言整理
有一群人排好队, 每个人身高为 h i h_i h i k i k_i k i ( h 1 , k 1 ) , ( h 2 , k 2 ) , . . . , ( h i , k i ) , . . . (h_1, k_1), (h_2, k_2), ..., (h_i, k_i), ... ( h 1 , k 1 ) , ( h 2 , k 2 ) , ... , ( h i , k i ) , ...
思考
恢复顺序的依据: 通过 ( h i , k i ) (h_i, k_i) ( h i , k i )
由于被打乱, 恢复顺序一定需要排序;
由于 k i k_i k i k i k_i k i
对排序后的数组遍历, 按照 "插入排序" 的思想找到合适的位置
def reconstructQueue ( self , people : List [ List [ int ]]) -> List [ List [ int ]]:
# [7, 0] [7, 1] [6, 1] [5, 0] [5, 2] [4, 4]
people . sort ( key = lambda x : - x [ 0 ] * 10 ** 5 + x [ 1 ])
res = []
for i , p in enumerate ( people ):
h , k = p [ 0 ], p [ 1 ]
if k == i :
res . append ( p )
elif k < i :
res . insert ( k , p )
return res
857. 雇佣 K 名工人的最低成本 - 力扣(LeetCode)
排序贪心 + 堆维护 k k k max ( w i q i ) × ∑ i = 1 k q i \max(\frac{w_i}{q_i}) \times \sum_{i=1}^{k}q_i max ( q i w i ) × ∑ i = 1 k q i w i q i \frac{w_i}{q_i} q i w i k k k q q q
def mincostToHireWorkers ( self , quality : List [ int ], wage : List [ int ], k : int ) -> float :
n = len ( quality )
nums = sorted ([( w / q , q ) for w , q in zip ( wage , quality )])
hq , s = [], 0
for i in range ( k ):
heappush ( hq , - nums [ i ][ 1 ])
s += nums [ i ][ 1 ]
res = nums [ k - 1 ][ 0 ] * s
for i in range ( k , n ):
mxw = - heappop ( hq )
s -= mxw
mxw = min ( mxw , nums [ i ][ 1 ])
heappush ( hq , - mxw )
s += mxw
res = min ( res , nums [ i ][ 0 ] * s )
return res
2589. 完成所有任务的最少时间 - 力扣(LeetCode)
区间选点问题:选点数量可能超过 1 + 右端点排序贪心
为什么不能按照左端点排序?
如果按照左端点排序:
当下一个区间比当前区间先结束时,选点会在当前区间中间;
当下一个区间前缀和当前区间后缀相交时,选点在当前区间的尾部。
两者无法统一。
考虑按照 右端点排序 / 结束时间排序:
当下一个区间比当前区间先开始,选点可以在当前区间的尾部。
当下一个区间前缀和当前区间后缀相交时,选点也可以在区间的尾部。
因此二者是统一的。
从前向后考虑区间,当前区间,我们希望当前区间的后缀去匹配更多的后续区间的前缀,因此选点应该越靠后越好,即在当前区间的尾部。当相邻区间不相交时,选点是当前区间独占的。
因此,使用 s e l sel se l
时间复杂度:O ( n log n + n U ) O(n \log n + n U) O ( n log n + n U ) U U U
def findMinimumTime ( self , nums : List [ List [ int ]]) -> int :
nums . sort ( key = lambda x : x [ 1 ])
n , m = len ( nums ), nums [ - 1 ][ 1 ]
sel = [ 0 ] * ( m + 1 )
for l , r , c in nums :
c -= sum ( sel [ l : r + 1 ])
if c > 0 :
for i in range ( r , l - 1 , - 1 ):
if sel [ i ]: continue
sel [ i ] = 1
c -= 1
if c == 0 : break
return sum ( sel )
2024_CA_省 C.训练士兵
[P10387 蓝桥杯 2024 省 A] 训练士兵 - 洛谷 (luogu.com.cn)
语言整理
$$
\begin{aligned}
&共 n 人,每人需要 c_i 次训练;
\
&每人单独训练每次花费 p_i 元;
\
&团购训练花费 S 元;
\
&求所有人完成训练的最小花费?
\end{aligned}
$$
思路
团购价不变,有些人训练次数 c i c_i c i
一开始团购价 S S S t o t tot t o t t o t tot t o t
当团购不合适时 S > t o t S>tot S > t o t
——联想到贪心 + 排序,尽可能贪心的多团购,讨论时按照所有人需要的训练次数从小到大排序;
思考
t o t tot t o t ∑ p i \sum p_i ∑ p i
用 r e s res res 0 0 0 c n t cnt c n t 已经团购的次数
按照训练次数升序遍历, 如果 t o t ≥ S tot \ge S t o t ≥ S r e s ← r e s + ( c i − c n t ) × S res ← res + (c_i - cnt) \times S res ← res + ( c i − c n t ) × S c n t ← c i cnt ← c_i c n t ← c i
否则团购不合适,r e s ← r e s + ( c i − c n t ) × p i res ← res + (c_i - cnt) \times p_i res ← res + ( c i − c n t ) × p i
每一次遍历完成,代表此人训练完成且退出,需要动态维护 t o t tot t o t t o t ← t o t − p i tot ← tot- p_i t o t ← t o t − p i
'''
P10387 [蓝桥杯 2024 省 A] 训练士兵
https://www.luogu.com.cn/problem/P10387
'''
import sys
input = lambda : sys . stdin . readline () . strip ()
n , S = map ( int , input () . split ())
nums = [[ 0 , 0 ]] * n # 用于排序
p , c = [ 0 ] * n , [ 0 ] * n
# 数据预处理
for i in range ( n ):
nums [ i ] = list ( map ( int , input () . split ()))
# 排序:根据 nums [i][1] 即次数排序,默认是由低到高
nums . sort ( key = lambda x : x [ 1 ])
for i in range ( n ):
p [ i ], c [ i ] = nums [ i ][ 0 ], nums [ i ][ 1 ]
res = cnt = 0
tot = sum ( p )
for i in range ( n ):
if tot >= S : # 团购合适
res += ( c [ i ] - cnt ) * S
cnt = c [ i ]
else : # 团购不合适,此人单独训练
res += ( c [ i ] - cnt ) * p [ i ]
tot -= p [ i ] # 第 i 人完成训练,减去他的单独训练成本
print ( res )
反悔贪心
反悔堆
630. 课程表 III - 力扣(LeetCode)
反悔贪心:按照截止日期排序,尽可能不跳过每一个课程。反悔条件(cur > y)满足时从反悔堆反悔用时最大的课程。
def scheduleCourse ( self , courses : List [ List [ int ]]) -> int :
# 按照截至日期排序
courses . sort ( key = lambda x : x [ 1 ])
hq = []
res , cur = 0 , 0
for x , y in courses :
cur += x # 贪心:尽可能不跳过每一个课程
heapq . heappush ( hq , - x ) # 反悔堆:存放所有课程耗时
if cur > y : # 反悔条件:超过截止日期
cur += heapq . heappop ( hq )
else :
res += 1
return res
LCP 30. 魔塔游戏 - 力扣(LeetCode)
def magicTower ( self , nums : List [ int ]) -> int :
if sum ( nums ) + 1 <= 0 :
return - 1
hq = []
res , cur = 0 , 1
for x in nums :
cur += x # 贪心:尽可能不使用移动
if x < 0 : # 反悔堆
heapq . heappush ( hq , x )
if cur <= 0 : # 反悔条件:血量不是正值
res += 1
cur -= heapq . heappop ( hq ) # 从反悔堆中,贪心回复血量
return res
1642. 可以到达的最远建筑 - 力扣(LeetCode)
def furthestBuilding ( self , heights : List [ int ], bricks : int , ladders : int ) -> int :
n = len ( heights )
d = [ max ( 0 , heights [ i ] - heights [ i - 1 ]) for i in range ( 1 , n )]
hq = []
for res , x in enumerate ( d ):
# ladders - len(hq) 代表剩余梯子数量
heapq . heappush ( hq , x ) # 贪心 + 反悔堆
if ladders - len ( hq ) < 0 : # 反悔条件:梯子不够了
bricks -= heapq . heappop ( hq )
if bricks < 0 :
return res
return n - 1
871. 最低加油次数 - 力扣(LeetCode)
循环反悔贪心 + 反悔堆后置(需要贪心完成后才能加入当前值)
def minRefuelStops ( self , target : int , startFuel : int , stations : List [ List [ int ]]) -> int :
stations . append ([ target , 0 ])
n = len ( stations )
pre = 0
res , cur = 0 , startFuel
hq = []
for x , y in stations :
cur -= x - pre # 贪心:尽可能耗油不加油
pre = x
while hq and cur < 0 : # 反悔条件:剩余油不够了
res += 1
cur -= heapq . heappop ( hq )
if cur < 0 and not hq :
return - 1
heapq . heappush ( hq , - y ) # 反悔堆:保存没加的油
return res
尝试反悔 + 反悔栈
也是一个二维贪心问题。尽可能优先考虑利润维度。
2813. 子序列最大优雅度 - 力扣(LeetCode)
def findMaximumElegance ( self , items : List [ List [ int ]], k : int ) -> int :
items . sort ( reverse = True )
s = set () # 只出现一次的种类 c
stk = [] # 反悔栈:出现两次以上的利润 p
res = total_profit = 0
for i , ( p , c ) in enumerate ( items ):
if i < k :
total_profit += p
if c not in s : # 种类 c 首次出现, 对应 p 一定最大, 一定保留
s . add ( c )
else :
stk . append ( p ) # 反悔栈:存放第二次及以后出现的更小的 p
elif stk and c not in s :
# 只有 c 没有出现在 s 中时,才尝试反悔一个出现两次及以上的 p
total_profit += p - stk . pop ()
s . add ( c )
# 贪心:s 的长度只增不减
res = max ( res , total_profit + len ( s ) ** 2 )
return res
消消乐贪心
配合哈希表 / 哈希集合,在 O ( n ) O(n) O ( n ) x x x
最长连续子序列
最长连续序列
给定一个未排序的整数数组 nums ,找出数字连续的最长子序列。
对于任何一个数 x x x
def longestConsecutive ( self , nums : List [ int ]) -> int :
s = set ( nums )
res = 0
for x in nums :
if x not in s : continue
cur = 1
s . remove ( x )
y = x + 1
while y in s :
s . remove ( y )
cur , y = cur + 1 , y + 1
y = x - 1
while y in s :
s . remove ( y )
cur , y = cur + 1 , y - 1
res = max ( res , cur )
return res
2007. 从双倍数组中还原原数组 - 力扣(LeetCode)
对于任何一个数 x x x O ( n ) O(n) O ( n )
def findOriginalArray ( self , changed : List [ int ]) -> List [ int ]:
n = len ( changed )
if n & 1 : return []
res = []
cnt = Counter ( changed )
for i , x in enumerate ( changed ):
if cnt [ x ] == 0 : continue
if x == 0 :
if cnt [ 0 ] & 1 : return []
res . extend ( cnt [ 0 ] // 2 * [ 0 ])
cnt [ 0 ] = 0
continue
while x & 1 == 0 and cnt [ x // 2 ] > 0 : x //= 2
y = x
while cnt [ y ] > 0 :
if cnt [ y * 2 ] < cnt [ y ]: return []
res . extend ( cnt [ y ] * [ y ])
cnt [ y * 2 ] -= cnt [ y ]
cnt [ y ] = 0
if cnt [ y * 2 ]: y = 2 * y
else : y = 4 * y
return res
贪心集合划分
划分集合和不超过 k k k
1986. 完成任务的最少工作时间段 - 力扣(LeetCode)
一种做法是 O ( 3 n + n ⋅ 2 n ) O(3^n+n\cdot 2^n) O ( 3 n + n ⋅ 2 n ) O ( 2 n ) O(2^n) O ( 2 n )
首先按照从到大小排序。 对于 a [ i ] a[i] a [ i ] O ( 2 n ) O(2^n) O ( 2 n )
def minSessions ( self , nums : List [ int ], k : int ) -> int :
nums . sort ( reverse = True )
n = len ( nums )
cnt = [ 0 ] * n
res = inf
def dfs ( i , cur ):
nonlocal res
if cur >= res : return
if i == n :
res = cur
return
x = nums [ i ]
for j in range ( cur ):
if cnt [ j ] + x <= k :
cnt [ j ] += x
dfs ( i + 1 , cur )
cnt [ j ] -= x
cnt [ cur ] += x
dfs ( i + 1 , cur + 1 )
cnt [ cur ] -= x
dfs ( 0 , 0 )
return res
划分集合和不超过 k k k
排序 + 双指针贪心。
881. 救生艇 - 力扣(LeetCode)
def numRescueBoats ( self , nums : List [ int ], k : int ) -> int :
nums . sort ( reverse = True )
n = len ( nums )
i , j = 0 , n - 1
res = 0
while i <= j :
lft = k - nums [ i ]
i += 1
if lft >= nums [ j ]:
j -= 1
res += 1
return res
贡献法
经典问题:子数组的最小值之和,子数组的最大值之和,子数组的极差之和。
套娃式定义,如子数组的子数组,子序列的子序列
求某些的和,可以考虑成子子问题对总问题的贡献
2104. 子数组范围和 - 力扣(LeetCode)
考虑每个值对子数组最大值,最小值的贡献情况,用单调栈维护。
最大值用减小栈维护,贡献是 ( i − t ) × ( t − s t k [ − 1 ] ) × n u m s [ t ] (i - t) \times (t - stk[-1]) \times nums[t] ( i − t ) × ( t − s t k [ − 1 ]) × n u m s [ t ]
def subArrayRanges ( self , nums : List [ int ]) -> int :
res = 0
stk = [ - 1 ]
total_mx = 0 # 贡献
nums . append ( inf )
for i , x in enumerate ( nums ):
# 单调减
while len ( stk ) > 1 and x >= nums [ stk [ - 1 ]]:
t = stk . pop ()
total_mx += ( i - t ) * ( t - stk [ - 1 ]) * nums [ t ]
stk . append ( i )
stk = [ - 1 ]
nums [ - 1 ] = - inf
total_mn = 0
for i , x in enumerate ( nums ):
# 单调增
while len ( stk ) > 1 and x <= nums [ stk [ - 1 ]]:
t = stk . pop ()
total_mn += ( i - t ) * ( t - stk [ - 1 ]) * nums [ t ]
stk . append ( i )
return total_mx - total_mn
计算几何
旋转与向量
将点 ( x , y ) (x, ~y) ( x , y ) α \alpha α ( x cos α + y sin α , y cos α − x sin α ) (x \cos \alpha+y\sin\alpha,~~~ y \cos \alpha~ - x\sin\alpha ) ( x cos α + y sin α , y cos α − x sin α )
证明:
点 P ( x , y ) P(x, y) P ( x , y ) r r r θ \theta θ
{ x = r cos θ y = r sin θ
\begin{cases}
x = r \cos \theta
\\
y = r \sin \theta
\end{cases}
\\
{ x = r cos θ y = r sin θ 顺时针旋转 α \alpha α
{ x ′ = r cos ( θ − α ) = x cos α + y sin α y ′ = r sin ( θ − α ) = y cos α − x sin α
\begin{cases}
x' = r \cos (\theta - \alpha) = x \cos \alpha + y \sin \alpha
\\
y' = r \sin (\theta - \alpha) = y \cos \alpha - x \sin \alpha
\end{cases}
\\
{ x ′ = r cos ( θ − α ) = x cos α + y sin α y ′ = r sin ( θ − α ) = y cos α − x sin α 距离
A ( x 1 , y 1 ) , B ( x 2 , y 2 ) A(x_1, ~y_1),~ B(x_2, ~y_2) A ( x 1 , y 1 ) , B ( x 2 , y 2 )
曼哈顿距离 = ∣ x 1 − x 2 ∣ + ∣ y 1 − y 2 ∣ = |x_1 - x_2| + |y_1 - y_2| = ∣ x 1 − x 2 ∣ + ∣ y 1 − y 2 ∣
切比雪夫距离 = max ( ∣ x 1 − x 2 ∣ , ∣ y 1 − y 2 ∣ ) = \max(|x_1 - x_2| ,~ |y_1 - y_2|) = max ( ∣ x 1 − x 2 ∣ , ∣ y 1 − y 2 ∣ )
曼哈顿距离转切比雪夫
即将所有点顺时针旋转 45° 后再乘 2 \sqrt{2} 2
将 P ( x , y ) P(x,y) P ( x , y ) P ′ ( x + y , x − y ) P'(x+y,x-y) P ′ ( x + y , x − y ) d M = d Q ′ d_{M} = d'_Q d M = d Q ′
对于三维点 P ( x , y , z ) P(x, y, z) P ( x , y , z ) P ′ ′ ( x + y + z , − x + y + z , x − y + z , x + y − z ) P''(x+y+z, -x+y+z, x-y+z, x + y -z) P ′′ ( x + y + z , − x + y + z , x − y + z , x + y − z ) d M = d Q ′ ′ d_M = d''_Q d M = d Q ′′
当需要求若干点之间的最大 d M d_M d M
∀ i , j ∈ P , max ( ∣ x i − x j ∣ + ∣ y i − y j ∣ ) ⟺ max ( max ( ∣ x i ′ − x j ′ ∣ , ∣ y i ′ − y j ′ ∣ ) ) ⟺ ∀ i , j ∈ P , max ( max ( ∣ x i ′ − x j ′ ∣ ) , max ( ∣ y i ′ − y j ′ ∣ ) )
\begin{aligned}
\forall {i, j} \in P, \max(|x_i - x_j| + |y_i - y_j|) &\iff \max(\max(|x'_i - x'_j|, |y'_i - y'_j|)) \\
&\iff \forall {i, j} \in P , \max(\max(|x'_i - x'_j|), \max(|y'_i - y'_j|))
\end{aligned}
∀ i , j ∈ P , max ( ∣ x i − x j ∣ + ∣ y i − y j ∣ ) ⟺ max ( max ( ∣ x i ′ − x j ′ ∣ , ∣ y i ′ − y j ′ ∣ )) ⟺ ∀ i , j ∈ P , max ( max ( ∣ x i ′ − x j ′ ∣ ) , max ( ∣ y i ′ − y j ′ ∣ )) 3102. 最小化曼哈顿距离 - 力扣(LeetCode)
from sortedcontainers import SortedList
class Solution :
def minimumDistance ( self , points : List [ List [ int ]]) -> int :
msx , msy = SortedList (), SortedList ()
for x , y in points :
msx . add ( x + y )
msy . add ( x - y )
res = inf
for x , y in points :
msx . remove ( x + y )
msy . remove ( x - y )
xmx = msx [ - 1 ] - msx [ 0 ]
ymx = msy [ - 1 ] - msy [ 0 ]
res = min ( res , max ( xmx , ymx ))
msx . add ( x + y )
msy . add ( x - y )
return res
切比雪夫转曼哈顿距离
将 P ( x , y ) P(x, y) P ( x , y ) P ′ ( x + y 2 , x − y 2 ) P'(\frac{x + y}{2}, \frac{x-y}{2}) P ′ ( 2 x + y , 2 x − y ) d Q = d M ′ d_Q = d'_M d Q = d M ′
切比雪夫距离在计算的时候需要取 max,往往不是很好优化,对于一个点,计算其他点到该的距离的复杂度为 O(n)
而曼哈顿距离只有求和以及取绝对值两种运算,我们把坐标排序后可以去掉绝对值的影响,进而用前缀和优化,可以把复杂度降为 O(1)
[P3964 TJOI2013] 松鼠聚会 - 洛谷 | 计算机科学教育新生态 (luogu.com.cn)
转换成切比雪夫距离。将 x, y 分离,前缀和维护到各个 xi 和 yi 的距离和,再相加
def solve ():
n = int ( input ())
points = []
res = inf
for _ in range ( n ):
x , y = map ( int , input () . split ())
points . append ((( x + y ) / 2 , ( x - y ) / 2 ))
numsx = [ p [ 0 ] for p in points ]
numsy = [ p [ 1 ] for p in points ]
def g ( nums ):
nums . sort ()
curx = nums [ 0 ]
curd = sum ( nums [ i ] - curx for i in range ( 1 , n ))
dic = { nums [ 0 ]: curd }
for i in range ( 1 , n ):
x = nums [ i ]
d = x - curx
curd = curd + i * d - ( n - i ) * d
dic [ x ] = curd
curx = x
return dic
dicx , dicy = g ( numsx ), g ( numsy )
for x , y in points :
ans = dicx [ x ] + dicy [ y ]
res = min ( res , ans )
print ( int ( res ))
杂项问题
【蓝桥杯】Python自带编辑器IDLE的使用教程_python蓝桥杯编译器-CSDN博客
IDLE使用
c e i l ceil ce i l
同时存在除法和 c e i l ceil ce i l c e i l ( a / b ) ceil(a /b) ce i l ( a / b ) c e i l ( a / b + x ) ceil(a/b +x) ce i l ( a / b + x )
方法 1:c e i l ( x ) = m a t h . c e i l ( x − e p s ) ceil(x) = math.ceil(x - eps) ce i l ( x ) = ma t h . ce i l ( x − e p s ) e p s eps e p s 10 − 8 10^{-8} 1 0 − 8
方法 2:所有数乘 b b b b × c e i l ( a , b ) = ( ( a − 1 ) / / b + 1 ) × b b \times ceil(a,b) = ((a-1)//b + 1) \times b b × ce i l ( a , b ) = (( a − 1 ) // b + 1 ) × b c e i l ( 4 , 3 ) × 3 = 2 × 3 = 6 ceil(4,3) \times3=2\times 3=6 ce i l ( 4 , 3 ) × 3 = 2 × 3 = 6
1883. 准时抵达会议现场的最小跳过休息次数 - 力扣(LeetCode)
f ( i , j ) = min { f ( i − 1 , j − 1 ) + d [ i ] / s , c e i l ( f ( i − 1 , j ) + d [ i ] / s ) } f(i, j) =\min \{f(i - 1, j - 1) + d[i]/s,\ ceil(f(i - 1, j) + d[i]/s)\} f ( i , j ) = min { f ( i − 1 , j − 1 ) + d [ i ] / s , ce i l ( f ( i − 1 , j ) + d [ i ] / s )}
方法 1:
eps = 1e-8
def ceil ( x ):
return math . ceil ( x - eps )
def minSkips ( self , d : List [ int ], s : int , hoursBefore : int ) -> int :
n = len ( d )
if sum ( d ) > s * hoursBefore : return - 1
if n == 1 : return 0 if d [ 0 ] <= s * hoursBefore else - 1
mx = sum ( d ) + n
f = [[ mx ] * ( n + 1 ) for _ in range ( n + 1 )]
d = [ D / s for D in d ]
f [ 0 ][ 0 ] = ceil ( d [ 0 ])
f [ 0 ][ 1 ] = d [ 0 ]
for i in range ( 1 , n - 1 ):
for j in range ( i + 2 ):
f [ i ][ j ] = ceil ( f [ i - 1 ][ j ] + d [ i ]) # 不休息
if j : f [ i ][ j ] = min ( f [ i ][ j ], f [ i - 1 ][ j - 1 ] + d [ i ]) # 休息
for k in range ( n ):
if f [ n - 2 ][ k ] + d [ - 1 ] <= hoursBefore :
return k
方法 2:
def ceil ( a , b ):
return (( a - 1 ) // b + 1 ) * b
def minSkips ( self , d : List [ int ], s : int , hoursBefore : int ) -> int :
n = len ( d )
if sum ( d ) > s * hoursBefore : return - 1
if n == 1 : return 0 if d [ 0 ] <= s * hoursBefore else - 1
mx = sum ( d ) + n
f = [[ mx ] * ( n + 1 ) for _ in range ( n + 1 )]
f [ 0 ][ 0 ] = ceil ( d [ 0 ], s )
f [ 0 ][ 1 ] = d [ 0 ]
for i in range ( 1 , n - 1 ):
for j in range ( i + 2 ):
f [ i ][ j ] = ceil ( f [ i - 1 ][ j ] + d [ i ], s )
if j : f [ i ][ j ] = min ( f [ i ][ j ], f [ i - 1 ][ j - 1 ] + d [ i ])
for k in range ( n ):
if f [ n - 2 ][ k ] + d [ - 1 ] <= hoursBefore * s :
return k
离散化
二分写法
sorted_nums = sorted ( set ( nums ))
nums = [ bisect . bisect_left ( sorted_nums , x ) + 1 for x in nums ]
字典写法
sorted_nums = sorted ( set ( nums ))
mp = { x : i + 1 for i , x in enumerate ( sorted_nums )}
nums = [ mp [ x ] for x in nums ]
二分 + 还原
tmp = nums . copy ()
sorted_nums = sorted ( set ( nums ))
nums = [ bisect . bisect_left ( sorted_nums , x ) + 1 for x in nums ]
mp_rev = { i : x for i , x in zip ( nums , tmp )}
日期问题
蓝桥杯必备模块——datetime 轻松应对各类时间问题_python时间差计算:轻松应对日期和时间的差异-CSDN博客
Python datetime模块详解、示例-CSDN博客
datetime 库
from datetime import *
# 计算日期之差
t1 = date ( year = 2025 , month = 3 , day = 1 )
t2 = date ( year = 2025 , month = 3 , day = 17 )
print ( t2 - t1 ) # 16 days, 0:00:00
print (( t2 - t1 ) . days ) # 16
# 参数也可简化
t1 = date ( 2025 , 1 , 1 )
t2 = date ( 2025 , 3 , 17 )
print (( t2 - t1 ) . days ) # 75
# 获取当前日期
print ( date . today ()) # 2025-03-17
t1 = date ( 2025 , 3 , 17 )
print ( t1 + timedelta ( days = 2 )) # 2025-03-19
print ( t1 + timedelta ( 1 )) # 2025-03-18
print ( t1 . weekday ()) # 0,weekday()从0~6对应星期1~7
0第几天 - 蓝桥云课 (lanqiao.cn)
from datetime import *
print (( date ( 2000 , 5 , 4 ) - date ( 2000 , 1 , 1 )) . days + 1 ) # 第几天,要加1
0星期一 - 蓝桥云课 (lanqiao.cn)
from datetime import *
t1 = date ( 1901 , 1 , 1 )
t2 = date ( 2000 , 12 , 31 )
res = 0
while t1 <= t2 :
if t1 . weekday () == 0 :
res += 1
t1 += timedelta ( days = 1 )
print ( res )
0含 2 天数 - 蓝桥云课 (lanqiao.cn)
Python 的 datetime 模块支持的日期范围是从 0001-01-01 到 9999-12-31。如果你尝试处理超出这个范围的日期,就会引发这个错误。
from datetime import *
t1 = date ( 1900 , 1 , 1 )
t2 = date ( 9999 , 12 , 31 )
delta = timedelta ( 1 )
res = 0
while t1 < t2 :
if '2' in '' . join ([ str ( t1 . year ), str ( t1 . month ), str ( t1 . day )]): res += 1
t1 += delta
print ( res + 1 ) # 1994240,加上最后一天的2
灵茶 の 试炼 (qq.com)
2025年4月12日
2025年2月26日
GitHub